Split a file into individual records using SCOPE_CHUNK¶
Introduction¶
This design pattern can be used to split the data in a multi-record file into multiple files, each containing a single record, using the SCOPE_CHUNK prefix syntax of the Set function.
Tip
This pattern is recommended when the source data is flat (non-hierarchical) and the operation does not contain a transformation that uses conditional mapping. For complex (hierarchical) source data, see Split a file into individual records using SourceInstanceCount.
Use case¶
In this scenario, the source data contains multiple records, and the business process or target endpoint requires records to be processed individually.
Design pattern¶
This design pattern is to read the file using an operation where the transformation is using the same source and target schema. This pattern has these key characteristics:
- In the first field of the transformation processing the data, the
Setfunction is used to set a variable that begins withSCOPE_CHUNKfollowed by additional text to construct the variable name. The first argument builds the output filename, typically using a record identifier from the source data. The filenames must be unique to avoid being overwritten, so a record counter or a GUID can be used as part of the filename. - A file storage target such as Temporary Storage or Local Storage must be used. (Using a Variable is not supported.) Defining a path is recommended. The filename should be configured with the global variable name used in the
Setfunction. - The operation options must be configured with Enable Chunking selected, with a Chunk Size of
1, Number of Records per File of1, and Max Number of Threads of1. - During runtime, each record will be read and assigned a unique filename, and individually written to the target.
After using this pattern, typically the next step is to use the FileList function to get the array of filenames in the directory (configure the file directory Read activity with the * wildcard), then loop through the array and read each file into the source for the next operation.
Examples¶
Examples using the design pattern described above are provided for two different types of source data: a flat CSV file and a hierarchical JSON file.
Flat CSV¶
This example operation chain applies the design pattern described above to split flat CSV data into a file for each record. Each number corresponds with a description of the operation step below. For additional details, refer to the screenshots for the Hierarchical JSON example.
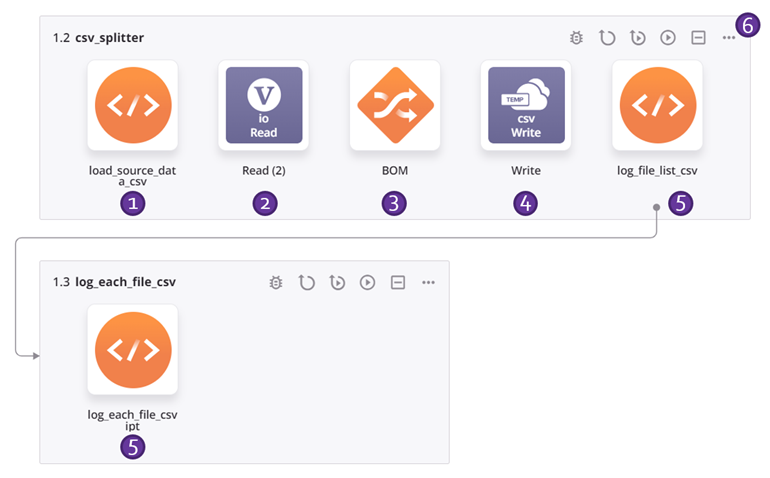
-
The script assigns the source data to a global variable named
io(input/output). (A script is used for demonstration purposes; the source data could also come from a configured endpoint.)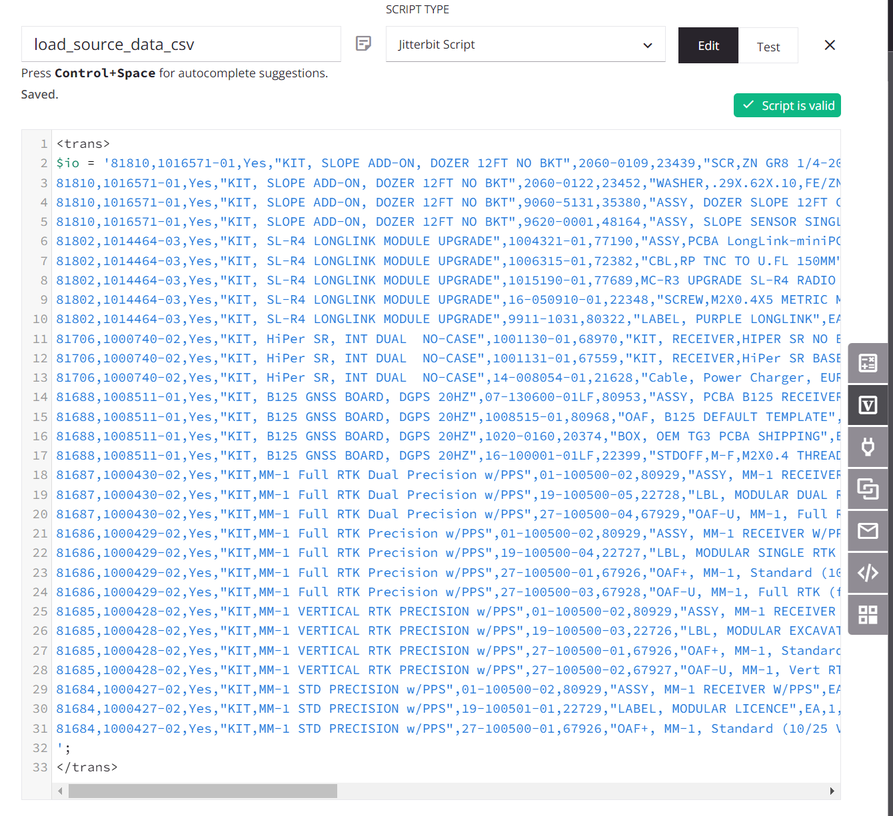
-
The
ioglobal variable is used to configure a Variable endpoint, and an associated Variable Read activity is used by the operation as the source of the transformation. -
Within the transformation, the source and targets use the same schema, and all the fields are mapped. The first data field in the transformation's mapping script is configured to use
SCOPE_CHUNK. TheSetfunction is used to build a variable starting with the phraseSCOPE_CHUNKand is concatenated with the unique record ID from the source as well as a record counter, and a suffix of.csv: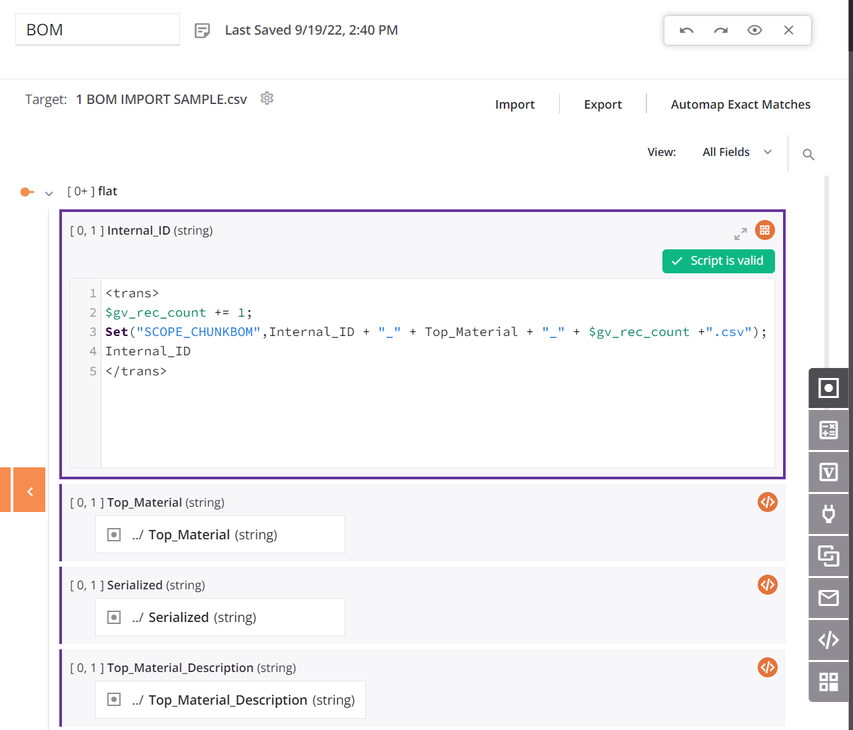
-
The target is a Temporary Storage Write activity configured with a default path and the filename global variable defined earlier.
-
The scripts are for logging the output and are optional. The first script gets a list of the files from the directory and loops over the list, logging the filename and size, and then passes the filename to an operation with another script that logs the file contents. (See the screenshots for the Hierarchical JSON example above.)
-
The operation options must be configured with Enable Chunking selected, with a Chunk Size of
1, Number of Records per File of1, and Max Number of Threads of1.
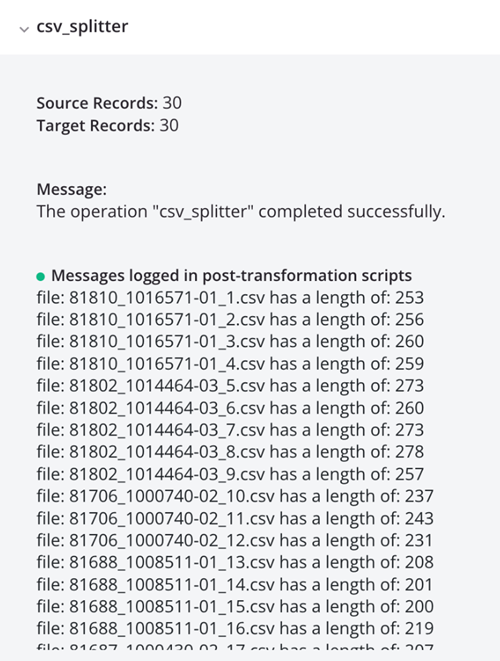
Running the operation results in individual CSV records, shown in the log output:
Hierarchical JSON¶
This example operation chain applies the design pattern described above to split hierarchical JSON data into a file for each record. Each number corresponds with a description of the operation step below.
Note
This design pattern is no longer the recommended method of splitting hierarchical JSON data. For the recommended method, see Split a file into individual records using SourceInstanceCount.
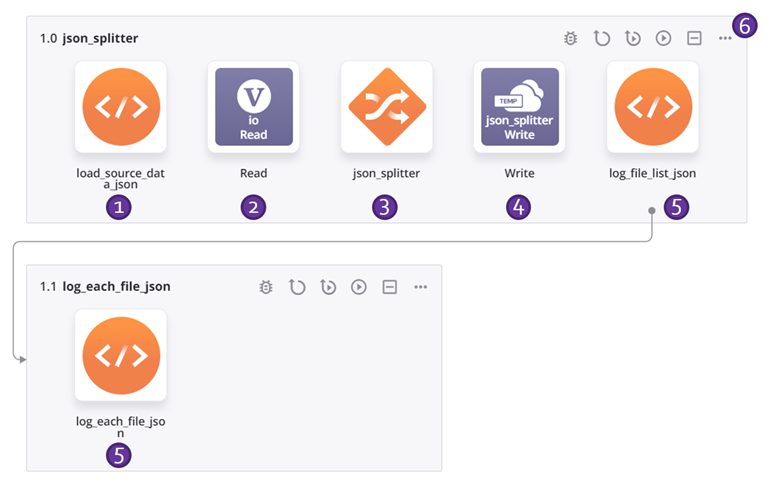
-
The script assigns the source data to a global variable named
io(input/output). (A script is used for demonstration purposes; the source data could also come from a configured endpoint.)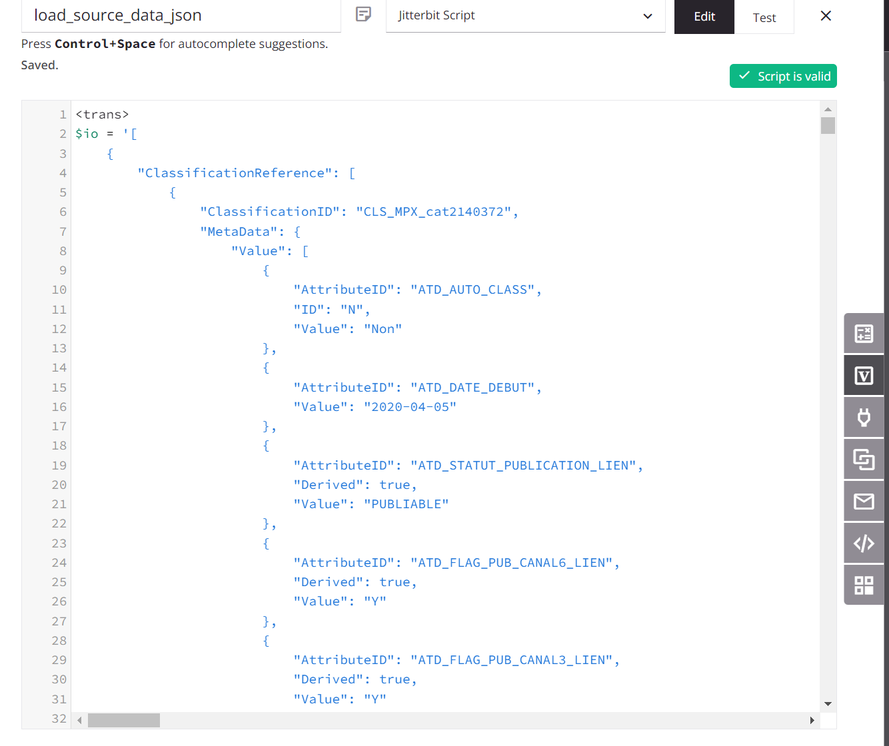
-
The
ioglobal variable is used to configure a Variable endpoint, and an associated Variable Read activity is used by the operation as the source of the transformation:
-
Within the transformation, the source and target use the same schema, and all the fields are mapped:
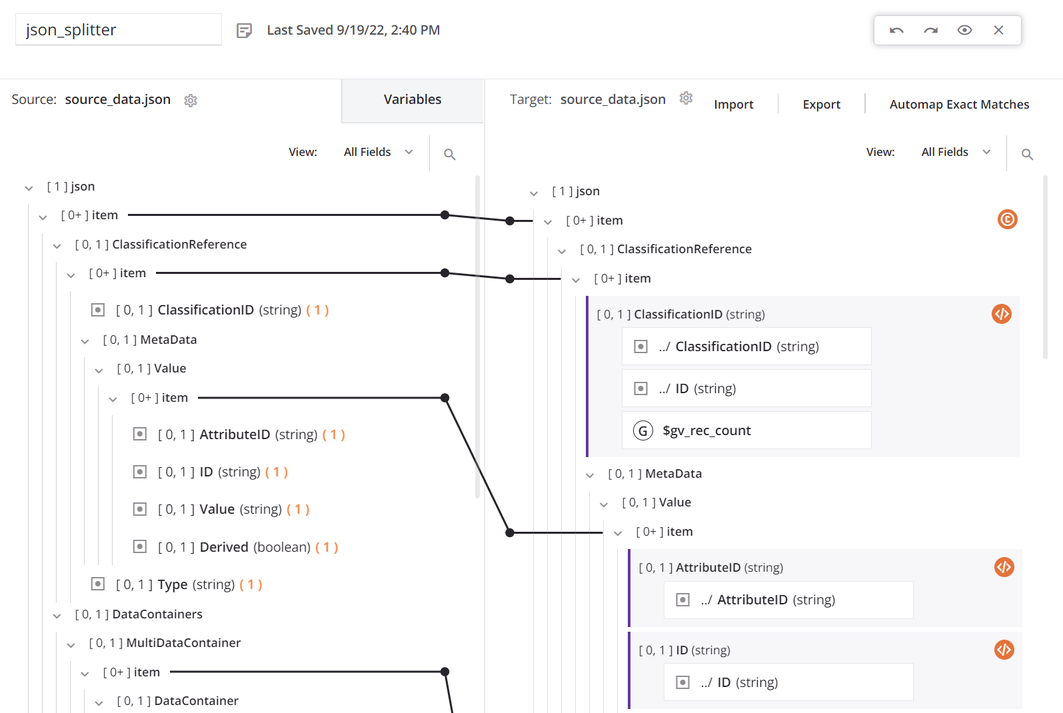
The top
itemnode has a condition to generate the record count. The first data field in the transformation mapping is configured to useSCOPE_CHUNK. TheSetfunction is used to build a variable starting with the phraseSCOPE_CHUNKand is concatenated with the unique record ID from the source as well as a record counter, and a suffix of.json: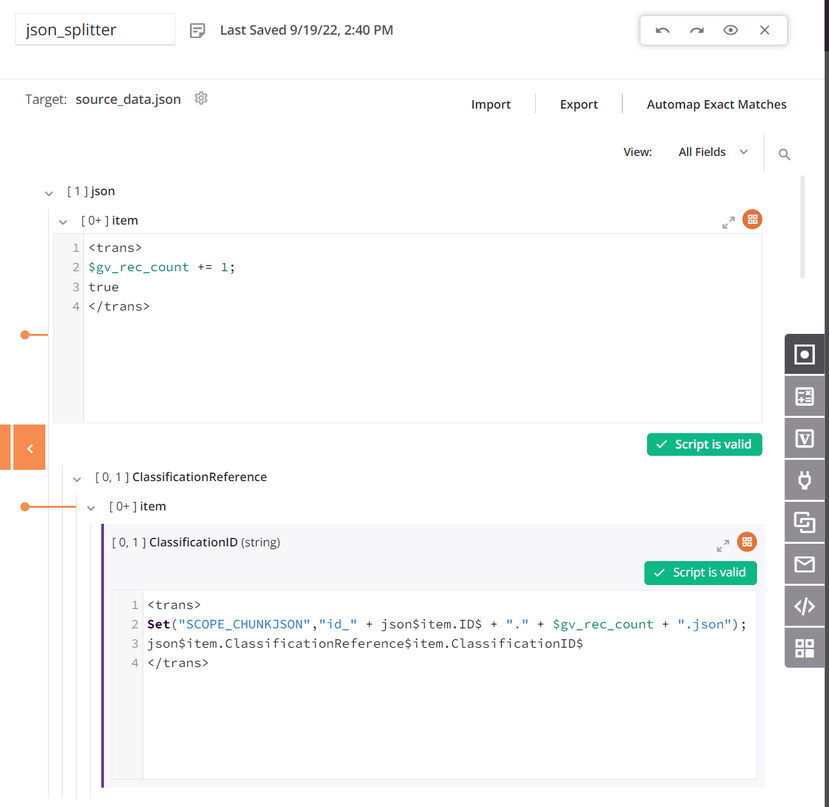
-
The target is a Temporary Storage Write activity configured with a default path and the filename global variable defined earlier:
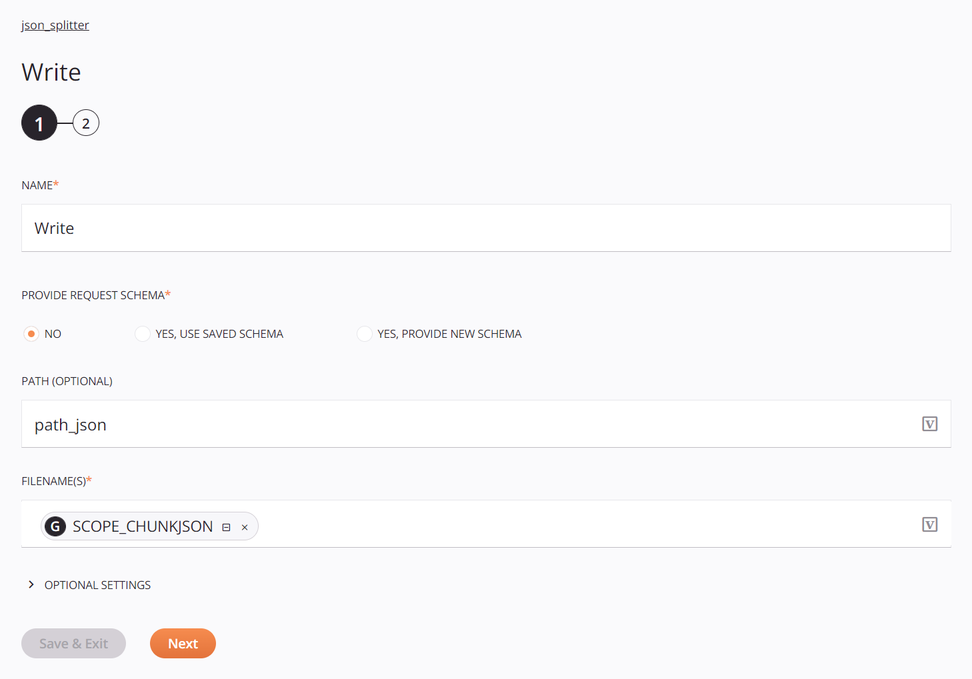
-
The scripts are for logging the output and are optional. The first script gets a list of the files from the directory and loops over the list, logging the filename and size, and then passes the filename to an operation with another script that logs the file contents:
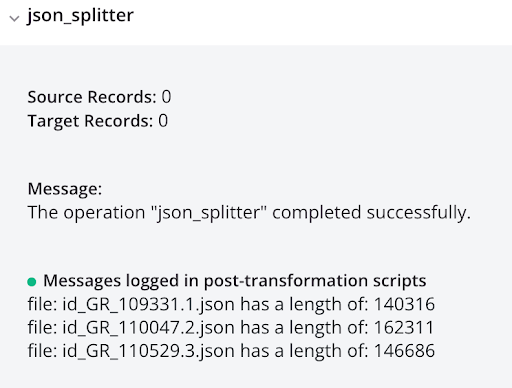
log_file_list_json<trans> arr = Array(); arr = FileList("<TAG>activity:tempstorage/json_splitter/tempstorage_read/Read</TAG>"); cnt = Length(arr); i = 0; While(i < cnt, filename = arr[i]; file = ReadFile("<TAG>activity:tempstorage/json_splitter/tempstorage_read/Read</TAG>",filename); WriteToOperationLog("file: " + filename + " has a length of: " + Length(file)); $gv_file_filter = filename; RunOperation("<TAG>operation:log_each_file_json</TAG>"); i++ ); </trans>log_each_file_json<trans> WriteToOperationLog(ReadFile("<TAG>activity:tempstorage/json_splitter/tempstorage_read/Read</TAG>",$gv_file_filter)); </trans> -
The operation options must be configured with Enable Chunking selected, with a Chunk Size of
1, Number of Records per File of1, and Max Number of Threads of1: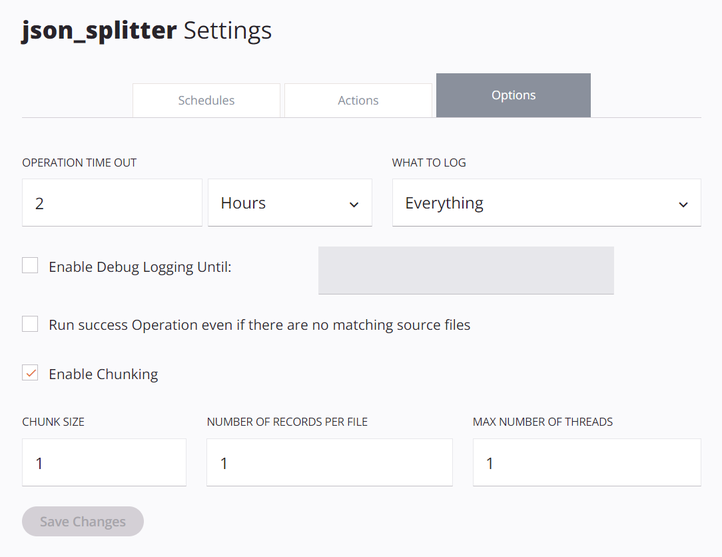
Running the operation results in individual JSON records, shown in the log output: