Snowflake Insert activity¶
Introduction¶
A Snowflake Insert activity, using its Snowflake connection, inserts table data (either as a CSV file or directly mapped to columns of a table) into Snowflake and is intended to be used as a target to consume data in an operation.
Create a Snowflake Insert activity¶
An instance of a Snowflake Insert activity is created from a Snowflake connection using its Insert activity type.
To create an instance of an activity, drag the activity type to the design canvas or copy the activity type and paste it on the design canvas. For details, see Creating an activity instance in Component reuse.
An existing Snowflake Insert activity can be edited from these locations:
- The design canvas (see Component actions menu in Design canvas).
- The project pane's Components tab (see Component actions menu in Project pane Components tab).
Configure a Snowflake Insert activity¶
Follow these steps to configure a Snowflake Insert activity:
-
Step 1: Enter a name and select an object
Provide a name for the activity and select an object, either a table or a view. -
Step 2: Select an approach
Different approaches are supported for inserting data to Snowflake. Choose from either Stage File or SQL Insert. When using the Stage File approach, you can select either the Amazon S3 or Internal stage file types. -
Step 3: Review the data schemas
Any request or response schemas generated from the endpoint are displayed.
Step 1: Enter a name and select an object¶
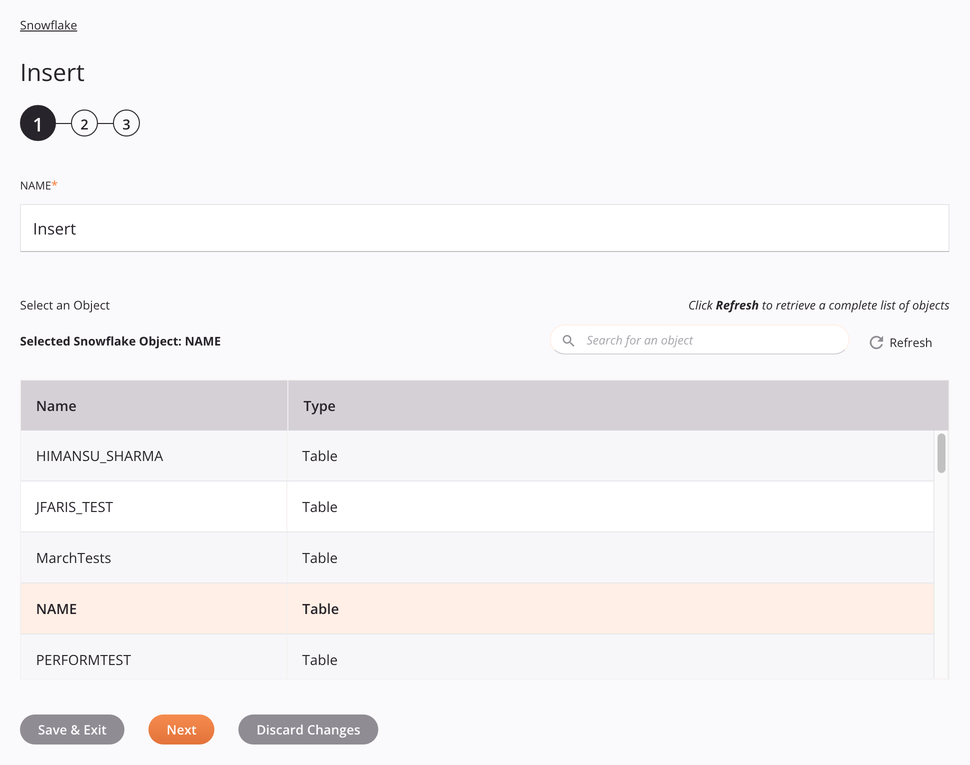
In this step, provide a name for the activity and select a table or view (see Snowflake's Overview of Views). Each user interface element of this step is described below.
-
Name: Enter a name to identify the activity. The name must be unique for each Snowflake Insert activity and must not contain forward slashes
/or colons:. -
Select an Object: This section displays objects available in the Snowflake endpoint. When reopening an existing activity configuration, only the selected object is displayed instead of reloading the entire object list.
-
Selected Snowflake Object: After an object is selected, it is listed here.
-
Search: Enter any column's value into the search box to filter the list of objects. The search is not case-sensitive. If objects are already displayed within the table, the table results are filtered in real time with each keystroke. To reload objects from the endpoint when searching, enter search criteria and then refresh, as described below.
-
Refresh: Click the refresh icon
 or the word Refresh to reload objects from the Snowflake endpoint. This may be useful if objects have been added to Snowflake. This action refreshes all metadata used to build the table of objects displayed in the configuration.
or the word Refresh to reload objects from the Snowflake endpoint. This may be useful if objects have been added to Snowflake. This action refreshes all metadata used to build the table of objects displayed in the configuration. -
Selecting an Object: Within the table, click anywhere on a row to select an object. Only one object can be selected. The information available for each object is fetched from the Snowflake endpoint:
-
Name: The name of an object, either a table or a view.
-
Type: The type of the object, either a table or a view.
-
Tip
If the table does not populate with available objects, the Snowflake connection may not be successful. Ensure you are connected by reopening the connection and retesting the credentials.
-
-
Save & Exit: If enabled, click to save the configuration for this step and close the activity configuration.
-
Next: Click to temporarily store the configuration for this step and continue to the next step. The configuration will not be saved until you click the Finished button on the last step.
-
Discard Changes: After making changes, click to close the configuration without saving changes made to any step. A message asks you to confirm that you want to discard changes.
Step 2: Select an approach¶
Different approaches are supported for inserting data to Snowflake. Choose from either SQL Insert or Stage File. When using the Stage File approach, you select either the Amazon S3 or Internal stage file types.
- SQL insert approach
- Amazon S3 stage file approach
- Google Cloud Storage stage file approach
- Internal stage file approach
- Microsoft Azure stage file approach
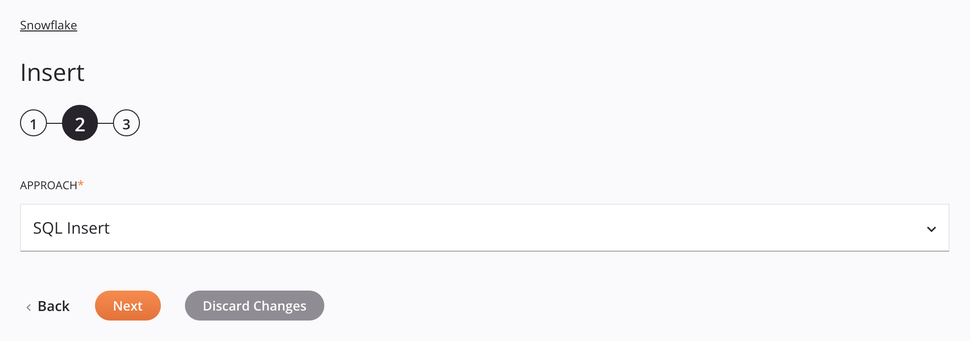
SQL Insert approach¶
For this approach, the table columns will be shown in the data schema step that follows, allowing them to be mapped in a transformation.
-
Approach: Use the dropdown to select SQL Insert.
-
Back: Click to return to the previous step and temporarily store the configuration.
-
Next: Click to continue to the next step and temporarily store the configuration. The configuration will not be saved until you click the Finished button on the last step.
-
Discard Changes: After making changes, click to close the configuration without saving changes made to any step. A message asks you to confirm that you want to discard changes.
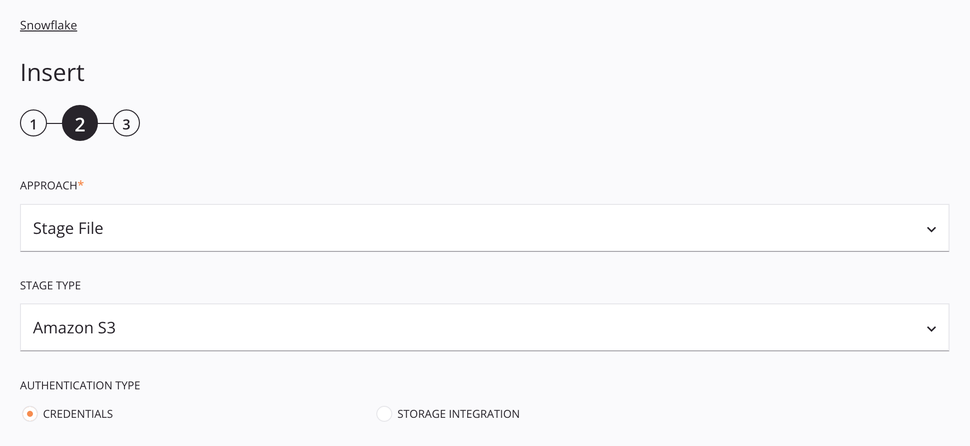
Amazon S3 Stage File approach¶
This approach allows a CSV file to be inserted into Snowflake using an Amazon S3 source. The file is staged and then copied into the table following the specifications of the request data schema.
For information on making requests to Amazon S3, see Making Requests in the Amazon S3 documentation.
-
Approach: Use the dropdown to select Stage File.
-
Stage Type: Choose Amazon S3 to retrieve data from Amazon S3 storage.
-
Authentication Type: Choose from either using Credentials or Storage Integration. Credentials requires the Amazon S3 access key ID and secret access Key. Storage Integration requires only the storage integration name. These authentication types are covered below.
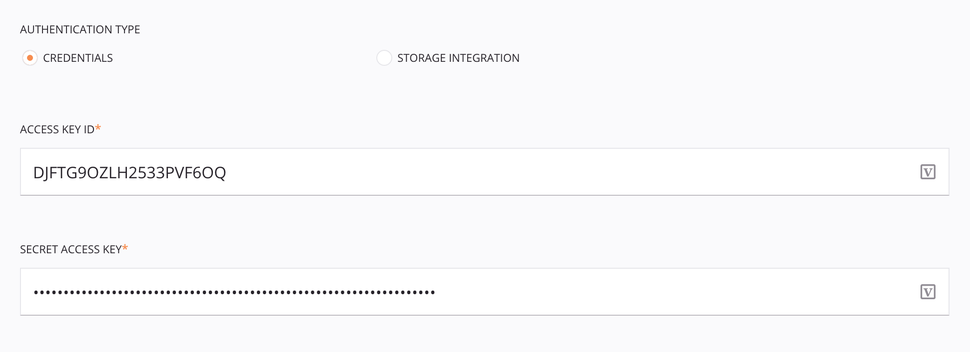
Credentials authentication¶
The Credentials authentication type requires the Amazon S3 access key ID and secret access key (for information on making requests to Amazon S3, see Making Requests in the Amazon S3 documentation).
-
Authentication Type: Choose Credentials.
-
Access Key ID: Enter the Amazon S3 access key ID.
-
Secret Access Key: Enter the Amazon S3 secret access Key.
Storage integration authentication¶
The Storage Integration authentication type requires creation of a Snowflake storage integration. For information on creating a Snowflake storage integration, see Create Storage Integration in the Snowflake documentation.
-
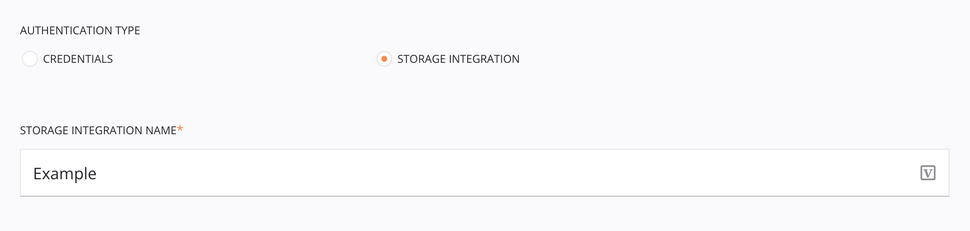
Authentication Type: Choose Storage Integration.
-
Storage Integration Name: Enter the name of the Snowflake storage integration.
Additional options¶
For both Credentials and Storage Integration authentication, there are these additional options:
-
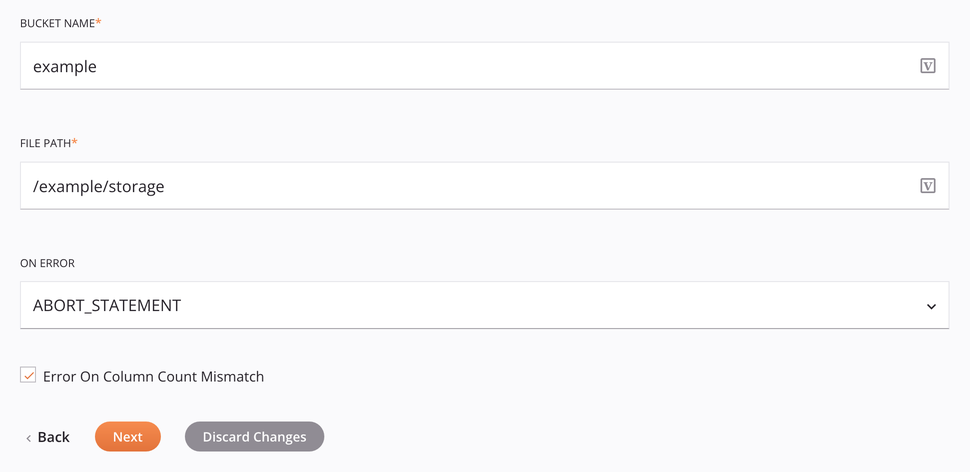
Bucket Name: Enter a valid bucket name for an existing bucket on the Amazon S3 server. This is ignored if
bucketNameis supplied in the data schemaInsertAmazonS3Request. -
File Path: Enter the file path.
-
On Error: Choose one of these options from the On Error dropdown; additional options will appear as appropriate:
-
Abort_Statement: Aborts the processing if any errors are encountered.
-
Continue: Continues loading the file even if errors are encountered.
-
Skip_File: Skips the file if any errors are encountered in the file.
-
Skip_File_\<num>: Skips the file when the number of errors in the file equal or exceed the number specified in Skip File Number.
-
Skip_File_\<num>%: Skips the file when the percentage of errors in the file exceeds the percentage specified in Skip File Number Percentage.
-
-
Error on Column Count Mismatch: If selected, reports an error in the error node of the response schema if the source and target column counts do not match. If you do not select this option, the operation does not fail and the provided data is inserted.
-
Back: Click to return to the previous step and temporarily store the configuration.
-
Next: Click to continue to the next step and temporarily store the configuration. The configuration will not be saved until you click the Finished button on the last step.
-
Discard Changes: After making changes, click to close the configuration without saving changes made to any step. A message asks you to confirm that you want to discard changes.
Internal Stage File approach¶
This approach allows a CSV file to be inserted into Snowflake. The file will be staged and then copied into the table following the specifications of the request data schema.
-
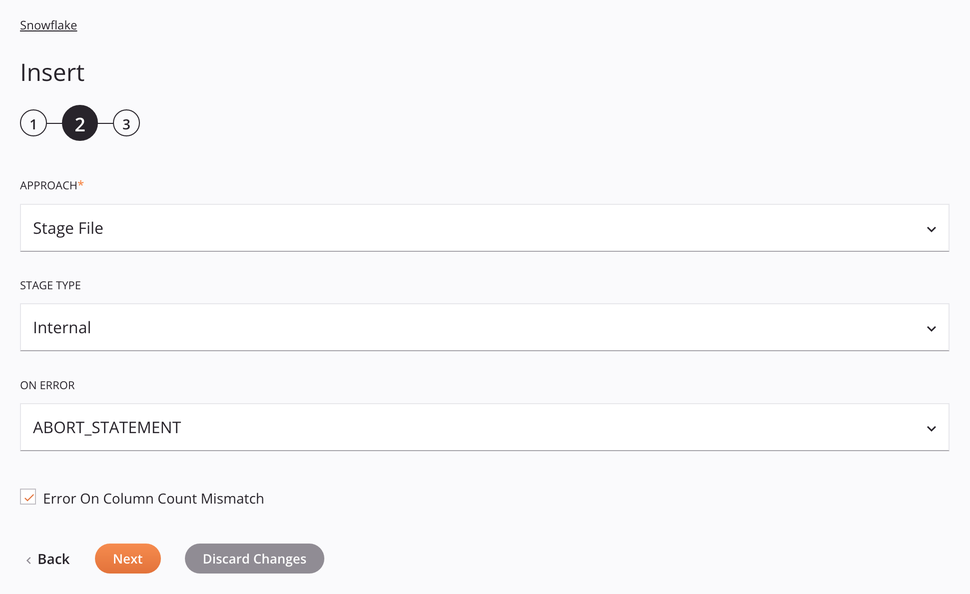
Approach: Use the dropdown to select Stage File.
-
Stage Type: Choose Internal to retrieve the data from an internal source.
-
On Error: Choose one of these options from the On Error dropdown; additional options will appear as appropriate:
-
Abort_Statement: Aborts the processing if any errors are encountered.
-
Continue: Continues loading the file even if errors are encountered.
-
Skip_File: Skips the file if any errors are encountered in the file.
-
Skip_File_\<num>: Skips the file when the number of errors in the file equal or exceed the number specified in Skip File Number.
-
Skip_File_\<num>%: Skips the file when the percentage of errors in the file exceeds the percentage specified in Skip File Number Percentage.
-
-
Error on Column Count Mismatch: If selected, reports an error in the error node of the response schema if the source and target column counts do not match. If you do not select this option, the operation does not fail and the provided data is inserted.
-
Back: Click to return to the previous step and temporarily store the configuration.
-
Next: Click to continue to the next step and temporarily store the configuration. The configuration will not be saved until you click the Finished button on the last step.
-
Discard Changes: After making changes, click to close the configuration without saving changes made to any step. A message asks you to confirm that you want to discard changes.
Google Cloud Storage Stage File approach¶
This approach allows a CSV file to be inserted into Google Cloud Storage. The file will be staged and then copied into the table following the specifications of the request data schema.
-
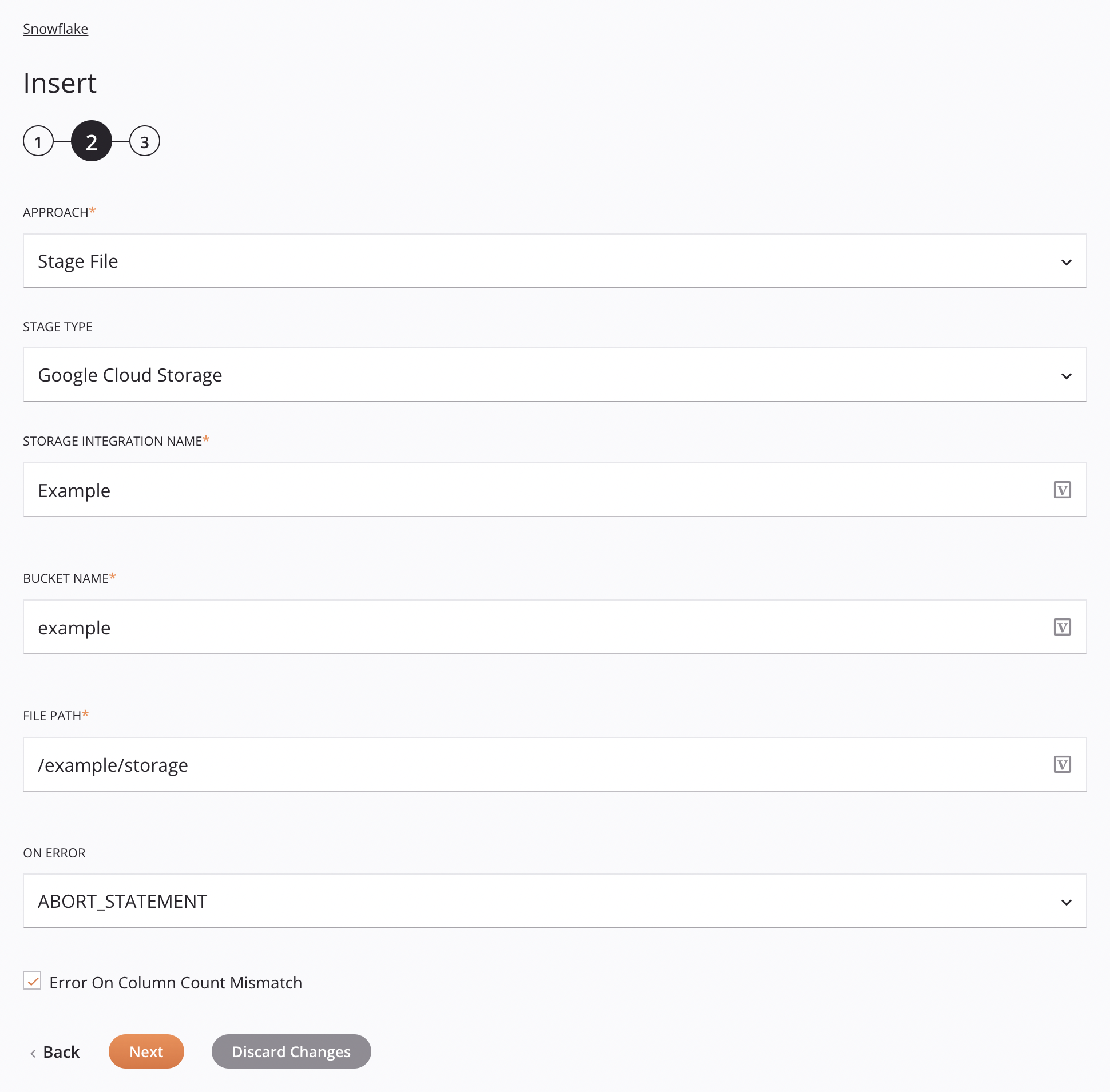
Approach: Use the dropdown to select Stage File.
-
Stage Type: Choose Google Cloud Storage to retrieve the data from an internal source.
-
Storage Integration Name: Enter the name of the Snowflake storage integration.
-
Bucket Name: Enter a valid bucket name for an existing bucket in Google Cloud Storage. This is ignored if
bucketNameis supplied in the data schemaInsertGoogleCloudRequest. -
File Path: Enter the file path.
-
On Error: Choose one of these options from the On Error dropdown; additional options will appear as appropriate:
-
Abort_Statement: Aborts the processing if any errors are encountered.
-
Continue: Continues loading the file even if errors are encountered.
-
Skip_File: Skips the file if any errors are encountered in the file.
-
Skip_File_\<num>: Skips the file when the number of errors in the file equal or exceed the number specified in Skip File Number.
-
Skip_File_\<num>%: Skips the file when the percentage of errors in the file exceeds the percentage specified in Skip File Number Percentage.
-
-
Error on Column Count Mismatch: If selected, reports an error in the error node of the response schema if the source and target column counts do not match. If you do not select this option, the operation does not fail and the provided data is inserted.
-
Back: Click to return to the previous step and temporarily store the configuration.
-
Next: Click to continue to the next step and temporarily store the configuration. The configuration will not be saved until you click the Finished button on the last step.
-
Discard Changes: After making changes, click to close the configuration without saving changes made to any step. A message asks you to confirm that you want to discard changes.
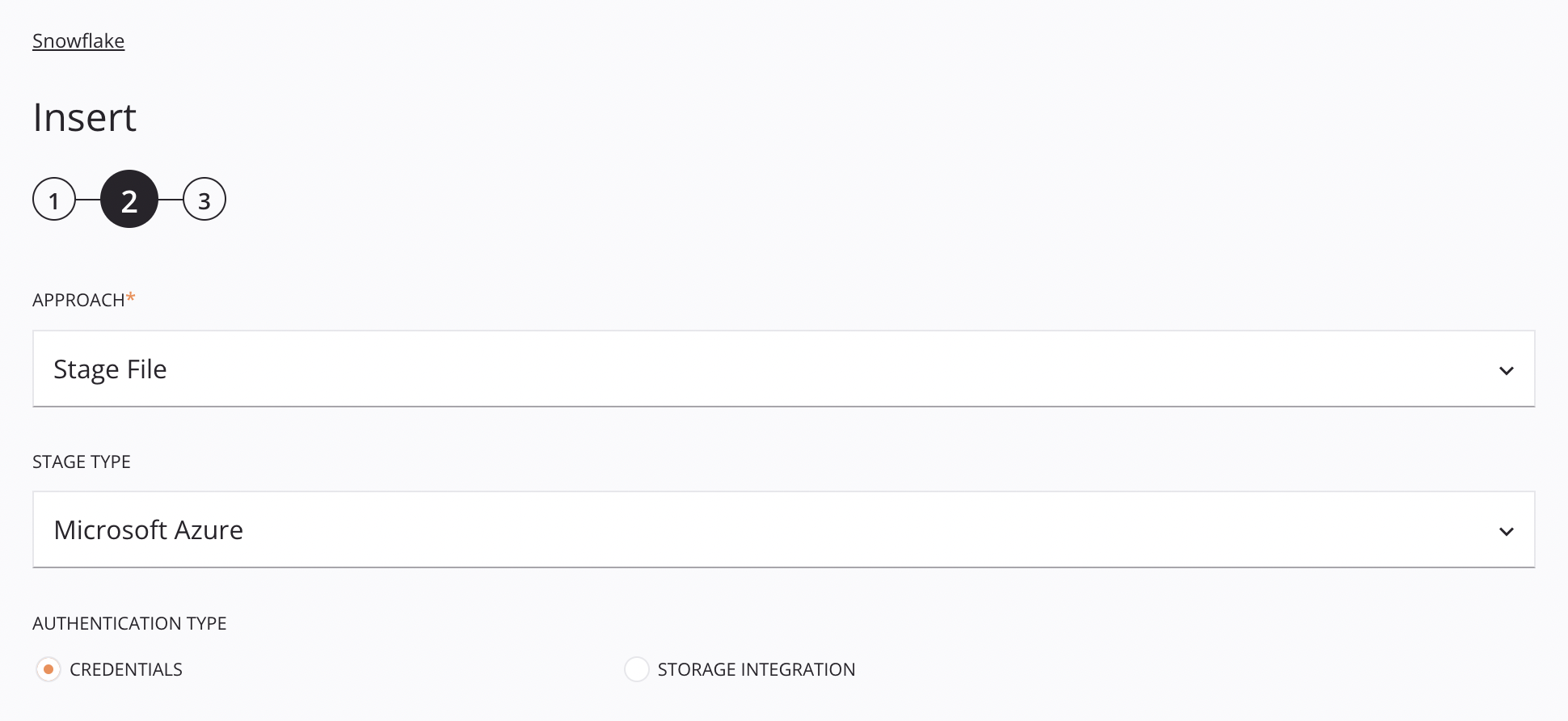
Microsoft Azure Stage File approach¶
This approach allows a CSV file to be inserted into Snowflake using a Microsoft Azure source. The file is staged and then copied into the table following the specifications of the request data schema.
-
Approach: Use the dropdown to select Stage File.
-
Stage Type: Choose Microsoft Azure to retrieve data from Microsoft Azure storage containers.
-
Authentication Type: Choose from either using Credentials or Storage Integration. Credentials requires a Microsoft Azure shared access signature (SAS) token and a storage account name. Storage Integration requires only a storage integration name. These authentication types are covered below.
Credentials authentication¶
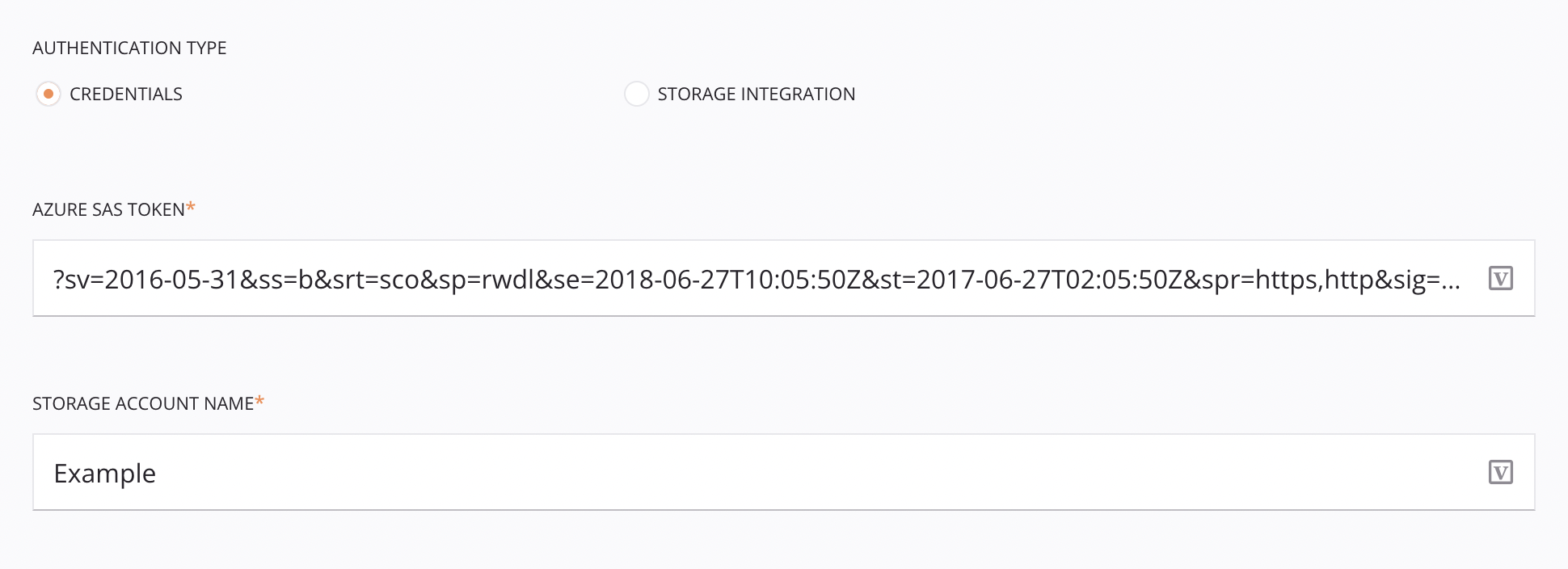
The Credentials authentication type requires a Microsoft Azure SAS token and a storage account name.
-
Authentication Type: Choose Credentials.
-
Azure SAS Token: Enter the Microsoft Azure SAS token. For information on creating SAS tokens for storage containers in Microsoft Azure, see Create SAS tokens for your storage containers in the Microsoft Azure documentation.
-
Storage Account Name: Enter the Microsoft Azure storage account name.
Storage integration authentication¶
The Storage Integration authentication type requires creation of a Snowflake storage integration. For information on creating a Snowflake storage integration, see Create Storage Integration in the Snowflake documentation.

-
Authentication Type: Choose Storage Integration.
-
Storage Integration Name: Enter the name of the Snowflake storage integration.
Additional options¶
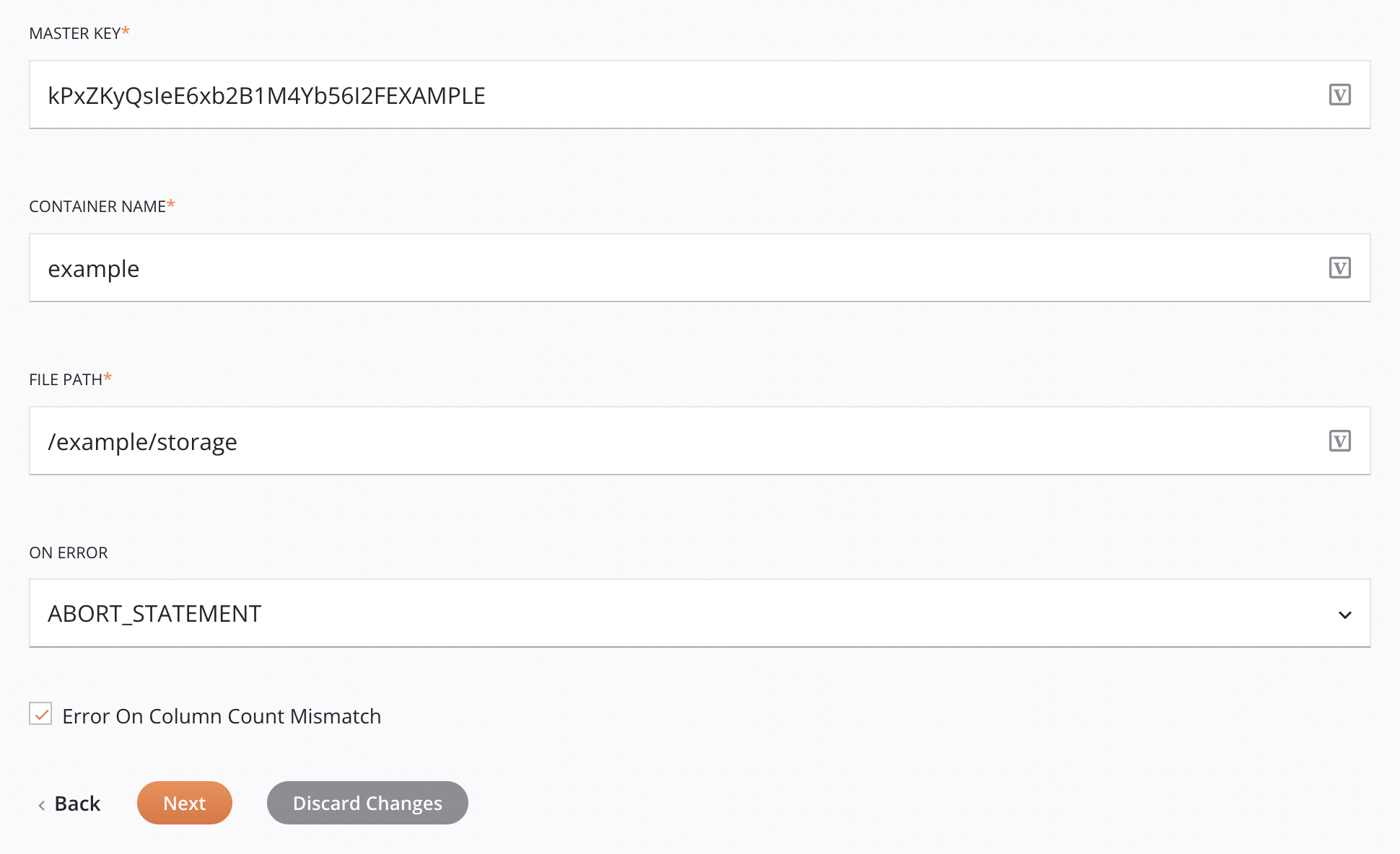
For both Credentials and Storage Integration authentication, there are these additional options:
-
Master Key: Enter the master key used for client-side encryption (CSE) in Microsoft Azure. This is ignored if
azureMasterKeyis supplied in the data schemaInsertMicrosoftAzureCloudRequest.Note
For information on creating keys in Microsoft Azure, see Quickstart: Set and retrieve a key from Azure Key Vault using the Azure portal in the Microsoft Azure documentation.
For information on storage CSE in Microsoft Azure, see Client-side encryption for blobs in the Microsoft Azure documentation.
-
Container Name: Enter a valid bucket name for an existing storage container in Microsoft Azure. This is ignored if
containerNameis supplied in the data schemaInsertMicrosoftAzureCloudRequest. -
File Path: Enter the file path.
-
On Error: Choose one of these options from the On Error dropdown; additional options will appear as appropriate:
-
Abort_Statement: Aborts the processing if any errors are encountered.
-
Continue: Continues loading the file even if errors are encountered.
-
Skip_File: Skips the file if any errors are encountered in the file.
-
Skip_File_\<num>: Skips the file when the number of errors in the file equal or exceed the number specified in Skip File Number.
-
Skip_File_\<num>%: Skips the file when the percentage of errors in the file exceeds the percentage specified in Skip File Number Percentage.
-
-
Error on Column Count Mismatch: If selected, reports an error in the error node of the response schema if the source and target column counts do not match. If you do not select this option, the operation does not fail and the provided data is inserted.
-
Back: Click to return to the previous step and temporarily store the configuration.
-
Next: Click to continue to the next step and temporarily store the configuration. The configuration will not be saved until you click the Finished button on the last step.
-
Discard Changes: After making changes, click to close the configuration without saving changes made to any step. A message asks you to confirm that you want to discard changes.
Step 3: Review the data schemas¶
The request and response schemas generated from the endpoint are displayed. The schemas displayed depend on the Approach specified in the previous step.
These subsections describe the request and response structures for each approach and stage type combination:
- SQL insert approach
- Amazon S3 stage file approach
- Google Cloud Storage stage file approach
- Internal stage file approach
- Microsoft Azure stage file approach
These actions are available with each approach:
-
Data Schemas: These data schemas are inherited by adjacent transformations and are displayed again during transformation mapping.
Note
Data supplied in a transformation takes precedence over the activity configuration.
The Snowflake connector uses the Snowflake JDBC Driver and the Snowflake SQL commands. Refer to the API documentation for information on the schema nodes and fields.
-
Refresh: Click the refresh icon
or the word Refresh to regenerate schemas from the Snowflake endpoint. This action also regenerates a schema in other locations throughout the project where the same schema is referenced, such as in an adjacent transformation. -
Back: Click to temporarily store the configuration for this step and return to the previous step.
-
Finished: Click to save the configuration for all steps and close the activity configuration.
-
Discard Changes: After making changes, click to close the configuration without saving changes made to any step. A message asks you to confirm that you want to discard changes.
SQL Insert approach¶
If the approach is SQL Insert, the table columns will be shown, allowing them to be mapped in a transformation.
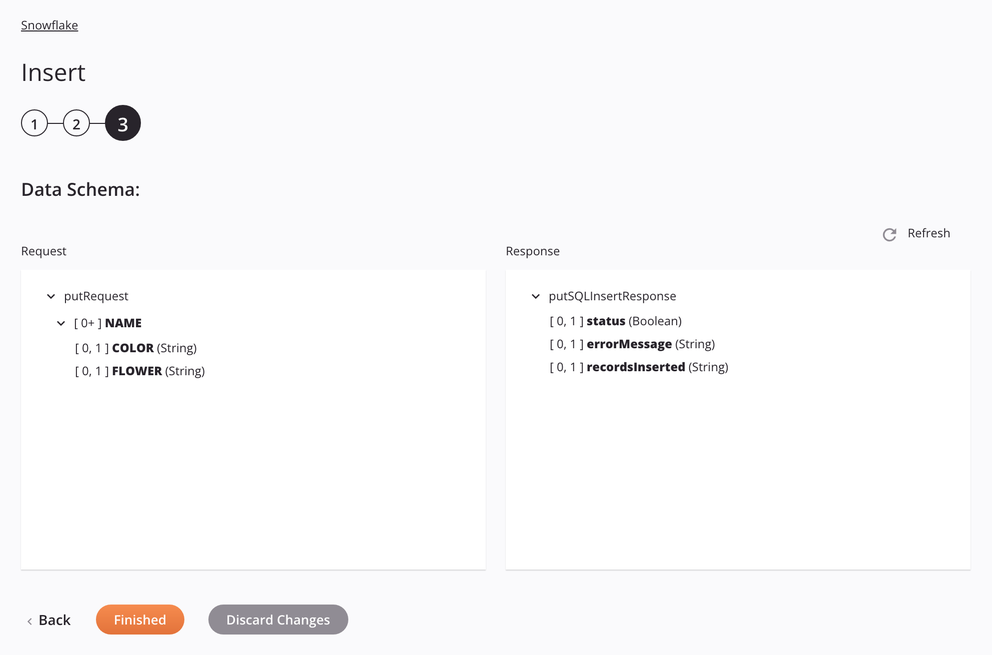
-
Request
Request Schema Field/Node Notes tableNode showing the table name. column_AFirst table column name. column_BSecond table column name. . . .Succeeding table columns. -
Response
Response Schema Field/Node Notes statusBoolean flag telling if record insertion was successful. errorMessageDescriptive error message if a failure during insertion. recordsInsertedNumber of records inserted if a successful insertion.
Amazon S3 Stage File approach¶
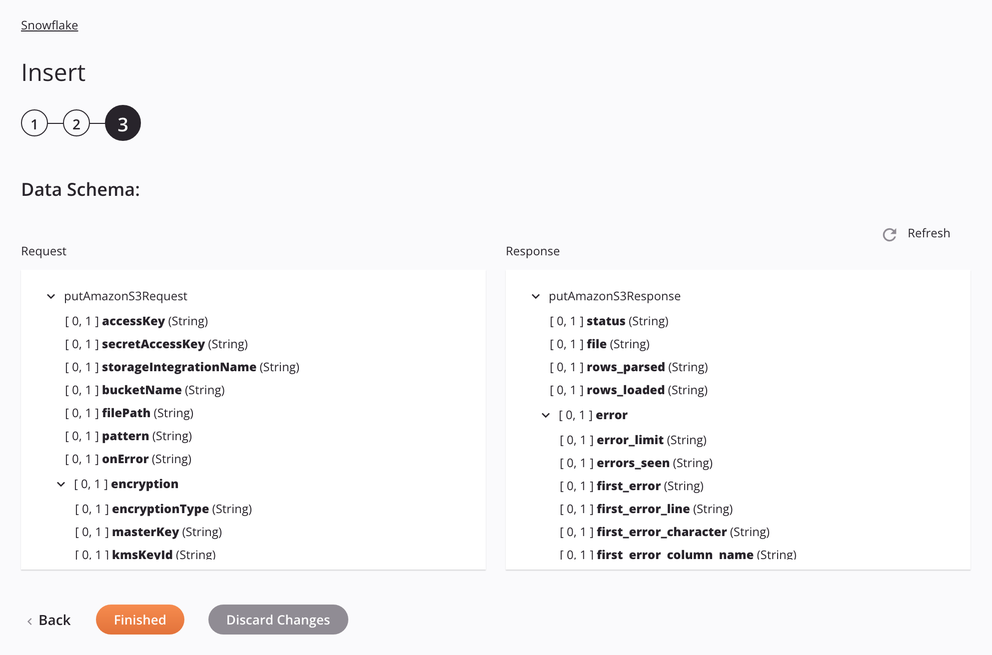
If the approach is Amazon S3 Stage File, the specifications for staging and inserting a CSV file will be shown in the data schema so that they can be mapped in a transformation. The pattern used is to match only one file. If the pattern matches more than one file, the activity will error with a descriptive message.
-
Request
Request Schema Field/Node Notes accessKeyAmazon S3 Access Key ID. secretAccessKeyAmazon S3 Secret Access Key. storageintegrationNameName of the Snowflake storage integration to be used for Snowflake storage integration authentication. bucketNameValid bucket name for an existing bucket on the Amazon S3 server. filePathLocation of the stage file on the Amazon S3 bucket. patternRegular-expression pattern used for finding the file on the stage; if compressionisGZIP,[.]gzis appended to the pattern.onErrorOn Error option selected. encryptionNode representing the encryption. encryptionTypeAmazon S3 encryption type (either server-side encryption or client-side encryption). masterKeyAmazon S3 Master Key. kmsKeyIdAmazon Key Management Service master ID. fileFormatNode representing the file format. nullIfA string to be converted to SQL NULL; by default, it is an empty string. See theNULL_IFoption of the SnowflakeCOPY INTO<location>documentation.enclosingCharCharacter used to enclose data fields; see the FIELD_OPTIONALLY_ENCLOSED_BYoption of the SnowflakeCOPY INTO<location>documentation.Note
The
enclosingCharcan be either a single quote character'or double quote character". To use the single quote character, use either the octal'or the hex0x27representations or use a double single quote escape''. When a field contains this character, escape it using the same character.compressionThe compression algorithm used for the data files. GZIPorNONEare supported. See the Compression option of the SnowflakeCOPY INTO<location>documentation.skipHeaderNumber of lines at the start of the source file to skip. errorOnColumnCountMismatchBoolean flag to report an error if the response schema source and target counts do not match. fieldDelimiterThe delimiter character used to separate data fields; see the FIELD_DELIMITERoption of the SnowflakeCOPY INTO<table>documentation.recordDelimiterThe delimiter character used to separate groups of fields; see the RECORD_DELIMITERoption of the SnowflakeCOPY INTO<table>documentation. -
Response
Response Schema Field/Node Notes statusStatus returned. fileName of the staged CSV file processed when inserting data into the Snowflake table. rows_parsedNumber of rows parsed from the CSV file. rows_loadedNumber of rows loaded from the CSV file into the Snowflake table without error. errorNode representing the error messages. error_limitNumber of errors that cause the file to be skipped as set in Skip_File_\<num>. errors_seenCount of errors seen. first_errorThe first error in the source file. first_error_lineThe first line number of the first error. first_error_characterThe first character of the first error. first_error_column_nameThe column name of the first error location.
Google Cloud Storage Stage File approach¶
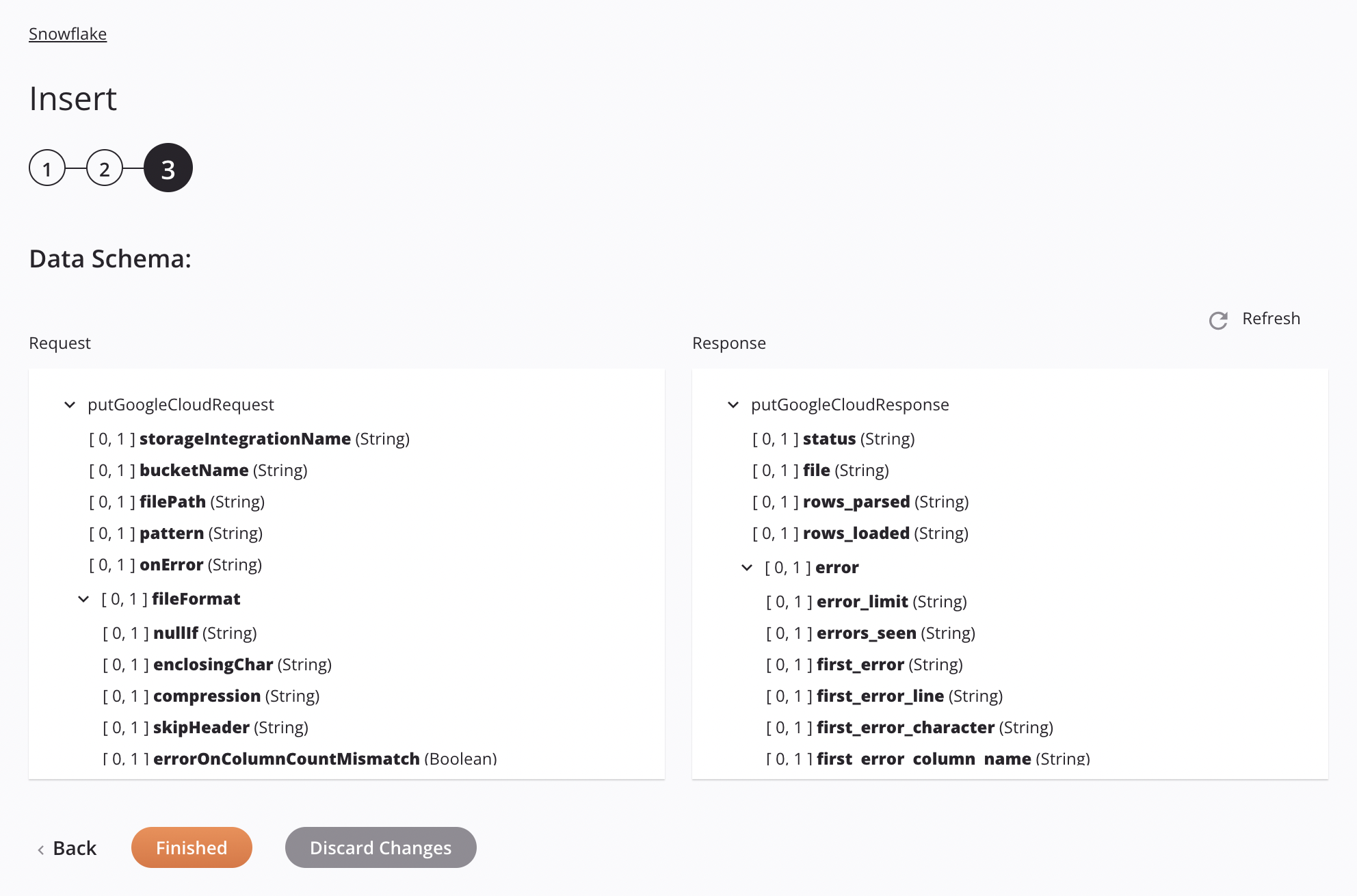
If the approach is Google Cloud Storage Stage File, the specifications for staging and inserting a CSV file will be shown in the data schema so that they can be mapped in a transformation. The pattern used is to match only one file. If the pattern matches more than one file, the activity will error with a descriptive message.
-
Request
Request Schema Field/Node Notes storageintegrationNameName of the Snowflake storage integration to be used for Snowflake storage integration authentication. bucketNameValid bucket name for an existing bucket in Google Cloud Storage. filePathLocation of the stage file in the Google Cloud Storage bucket. patternRegular-expression pattern used for finding the file on the stage; if compressDatais true,[.]gzis appended to the pattern.onErrorOn Error option selected. fileFormatNode representing the file format. nullIfA string to be converted to SQL NULL; by default, it is an empty string. See theNULL_IFoption of the SnowflakeCOPY INTO<location>documentation.enclosingCharCharacter used to enclose data fields; see the FIELD_OPTIONALLY_ENCLOSED_BYoption of the SnowflakeCOPY INTO<location>documentation.Note
The
enclosingCharcan be either a single quote character'or double quote character". To use the single quote character, use either the octal'or the hex0x27representations or use a double single quote escape''. When a field contains this character, escape it using the same character.compressionThe compression algorithm used for the data files. GZIPorNONEare supported. See the Compression option of the SnowflakeCOPY INTO<location>documentation.skipHeaderNumber of lines at the start of the source file to skip. errorOnColumnCountMismatchBoolean flag to report an error if the response schema source and target counts do not match. fieldDelimiterThe delimiter character used to separate data fields; see the FIELD_DELIMITERoption of the SnowflakeCOPY INTO<table>documentation.recordDelimiterThe delimiter character used to separate groups of fields; see the RECORD_DELIMITERoption of the SnowflakeCOPY INTO<table>documentation. -
Response
Response Schema Field/Node Notes statusStatus returned. fileName of the staged CSV file processed when inserting data into the Snowflake table. rows_parsedNumber of rows parsed from the CSV file. rows_loadedNumber of rows loaded from the CSV file into the Snowflake table without error. errorNode representing the error messages. error_limitNumber of errors that cause the file to be skipped as set in Skip_File_\<num>. errors_seenCount of errors seen. first_errorThe first error in the source file. first_error_lineThe first line number of the first error. first_error_characterThe first character of the first error. first_error_column_nameThe column name of the first error location.
Internal Stage File approach¶
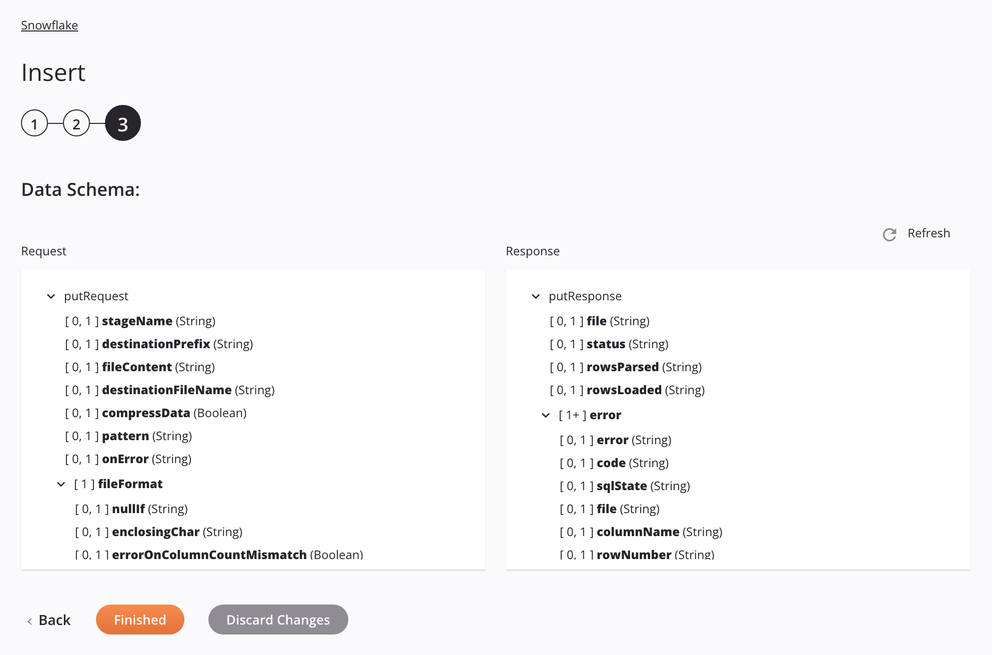
If the approach is Internal Stage File, the specifications for staging and inserting a CSV file will be shown in the data schema so that they can be mapped in a transformation. The pattern used is to match only one file. If the pattern matches more than one file, the activity will error with a descriptive message.
-
Request
Request Schema Field/Node Notes stageNameInternal Snowflake stage, table name, or path. destinationPrefixPath or prefix under which the data will be uploaded on the Snowflake stage. fileContentData file contents, in CSV format, that is to be staged for uploading to the Snowflake table. destinationFileNameDestination file name to be used on the Snowflake stage. compressDataBoolean flag for whether to compress the data before uploading it to the internal Snowflake stage. patternRegular-expression pattern used for finding the file on the stage; if compressDatais true,[.]gzis appended to the pattern.onErrorOn Error option selected. fileFormatNode representing the file format. nullIfA string to be converted to SQL NULL; by default, it is an empty string. See theNULL_IFoption of the SnowflakeCOPY INTO<location>documentation.enclosingCharCharacter used to enclose data fields; see the FIELD_OPTIONALLY_ENCLOSED_BYoption of the SnowflakeCOPY INTO<location>documentation.Note
The
enclosingCharcan be either a single quote character'or double quote character". To use the single quote character, use either the octal'or the hex0x27representations or use a double single quote escape''. When a field contains this character, escape it using the same character.errorOnColumnCountMismatchBoolean flag to report an error if the response schema source and target counts do not match. fieldDelimiterThe delimiter character used to separate data fields; see the FIELD_DELIMITERoption of the SnowflakeCOPY INTO<table>documentation.recordDelimiterThe delimiter character used to separate groups of fields; see the RECORD_DELIMITERoption of the SnowflakeCOPY INTO<table>documentation. -
Response
Response Schema Field/Node Notes fileName of the staged CSV file processed when putting data into the Snowflake table. statusStatus returned. rowsParsedNumber of rows parsed from the CSV file. rowsLoadedNumber of rows loaded from the CSV file into the Snowflake table without error. errorNode representing the error messages. errorThe error message. codeThe returned error code. sqlStateThe returned SQL state numeric error code of the database call. fileNode representing the error messages. columnNameName and order of the column that contained the error. rowNumberThe number of the row in the source file where the error was encountered. rowStartLineThe number of the first line of the row where the error was encountered.
Microsoft Azure Stage File approach¶
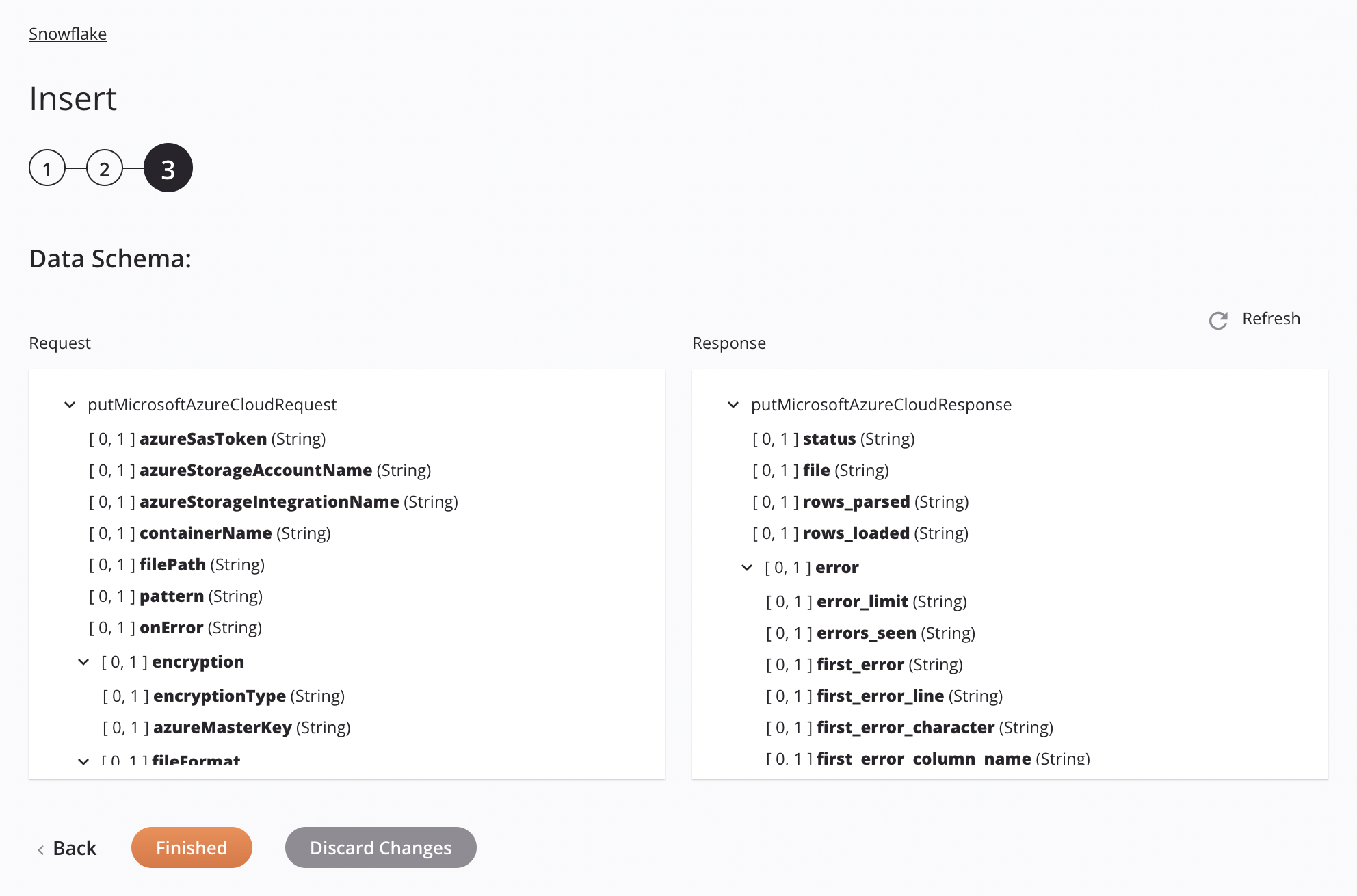
If the approach is Microsoft Azure Stage File, the specifications for staging and inserting a CSV file will be shown in the data schema so that they can be mapped in a transformation. The pattern used is to match only one file. If the pattern matches more than one file, the activity will error with a descriptive message.
-
Request
Request Schema Field/Node Notes azureSasTokenMicrosoft Azure Shared Access Signature (SAS) Token. azureStorageAccountNameMicrosoft Azure Storage Account Name. azureStorageintegrationNameName of the Snowflake storage integration to be used for Snowflake storage integration authentication. containerNameValid container name for an existing storage container in Microsoft Azure. filePathLocation of the stage file in the Microsoft Azure storage container. patternRegular-expression pattern used for finding the file on the stage; if compressionisGZIP,[.]gzis appended to the pattern.onErrorOn Error option selected. encryptionNode representing the encryption. encryptionTypeMicrosoft Azure encryption type (client-side encryption only). azureMasterKeyMicrosoft Azure Master Key. fileFormatNode representing the file format. nullIfA string to be converted to SQL NULL; by default, it is an empty string. See theNULL_IFoption of the SnowflakeCOPY INTO<location>documentation.enclosingCharCharacter used to enclose data fields; see the FIELD_OPTIONALLY_ENCLOSED_BYoption of the SnowflakeCOPY INTO<location>documentation.Note
The
enclosingCharcan be either a single quote character'or double quote character". To use the single quote character, use either the octal'or the hex0x27representations or use a double single quote escape''. When a field contains this character, escape it using the same character.compressionThe compression algorithm used for the data files. GZIPorNONEare supported. See the Compression option of the SnowflakeCOPY INTO<location>documentation.skipHeaderNumber of lines at the start of the source file to skip. errorOnColumnCountMismatchBoolean flag to report an error if the response schema source and target counts do not match. fieldDelimiterThe delimiter character used to separate data fields; see the FIELD_DELIMITERoption of the SnowflakeCOPY INTO<table>documentation.recordDelimiterThe delimiter character used to separate groups of fields; see the RECORD_DELIMITERoption of the SnowflakeCOPY INTO<table>documentation. -
Response
Response Schema Field/Node Notes statusStatus returned. fileName of the staged CSV file processed when inserting data into the Snowflake table. rows_parsedNumber of rows parsed from the CSV file. rows_loadedNumber of rows loaded from the CSV file into the Snowflake table without error. errorNode representing the error messages. error_limitNumber of errors that cause the file to be skipped as set in Skip_File_\<num>. errors_seenCount of errors seen. first_errorThe first error in the source file. first_error_lineThe first line number of the first error. first_error_characterThe first character of the first error. first_error_column_nameThe column name of the first error location.
Next steps¶
After configuring a Snowflake Insert activity, complete the configuration of the operation by adding and configuring other activities, transformations, or scripts as operation steps. You can also configure the operation settings, which include the ability to chain operations together that are in the same or different workflows.
Menu actions for an activity are accessible from the project pane and the design canvas. For details, see Activity actions menu in Connector basics.
Snowflake Insert activities can be used as a target with these operation patterns:
- Transformation pattern
- Two-transformation pattern (as the first or second target)
To use the activity with scripting functions, write the data to a temporary location and then use that temporary location in the scripting function.
When ready, deploy and run the operation and validate behavior by checking the operation logs.