Operation options¶
Introduction¶
Each operation can be configured with options such as when the operation will time out, what to log, and the timeframe for operation debug logging. The presence of certain components as operation steps makes visible additional options for whether a subsequent operation runs and whether to use chunking.
Access operation options¶
The Settings option for operations is accessible from these locations:
- The project pane's Workflows tab (see Component actions menu in Project pane Workflows tab).
- The project pane's Components tab (see Component actions menu in Project pane Components tab).
- The design canvas (see Component actions menu in Design canvas).
Once the operation settings screen is open, select the Options tab:

Configure operation options¶
Each option available within the Options tab of the operation settings is described below.
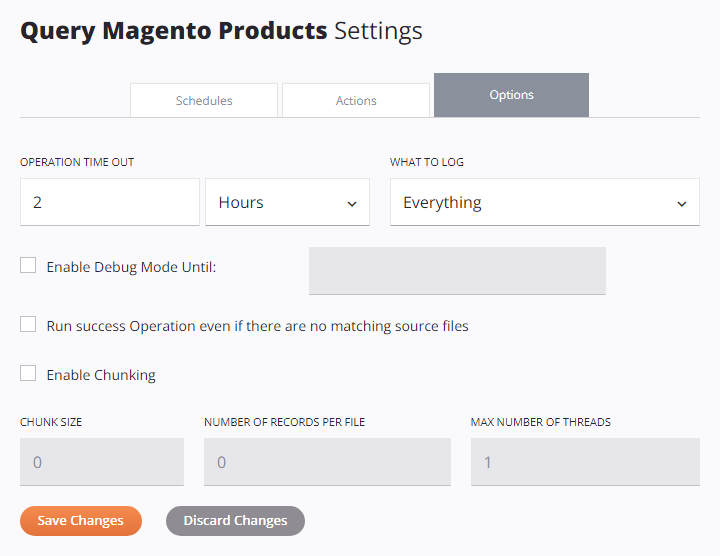
-
Operation Time Out: Specify the maximum amount of time the operation will run for before being canceled. In the first field, enter a number and in the second field use the dropdown to select the units in Seconds, Minutes, or Hours. The default is 2 hours.
Common reasons for adjusting the Operation Time Out value include these:
-
Increase the timeout value if the operation has large datasets that are taking a long time to run.
-
Decrease the timeout value if the operation is time-sensitive; that is, you do not want the operation to succeed if it cannot complete within a certain timeframe.
Note
Operations that are triggered by API Manager APIs are not subject to the Operation Time Out setting when using cloud agents. On private agents, use the
EnableAPITimeoutsetting in the private agent configuration file to have the Operation Time Out setting apply to operations triggered by APIs. -
-
What to Log: Use the dropdown to select what to log in the operation logs, one of Everything (default) or Errors Only:
-
Everything: Operations with any operation status are logged.
-
Errors Only: Only operations with an error-type status (such as Error, SOAP Fault, or Success with Child Error) are logged. Successful child operations are not logged. Parent (root-level) operations are always logged, as they require logging to function properly.
A common reason for limiting the logs to Errors Only is if you are having operation latency issues. This way, if you weren't planning on using the other non-error messages normally filtered out in the operation logs, you can prevent them from being generated in the first place.
-
-
Enable Debug Mode Until: Select to enable operation debug logging and specify a date that debug mode will automatically be disabled, limited to two weeks from the current date. Operation debug logging will be turned off at the beginning of that date (that is, 12:00 am) using the agent time zone.
When selecting Enable Debug Mode Until, a dialog provides an Also Apply to Child Operations checkbox that will cascade the settings to any child operations. This option is also provided when clearing the operation debug mode setting.
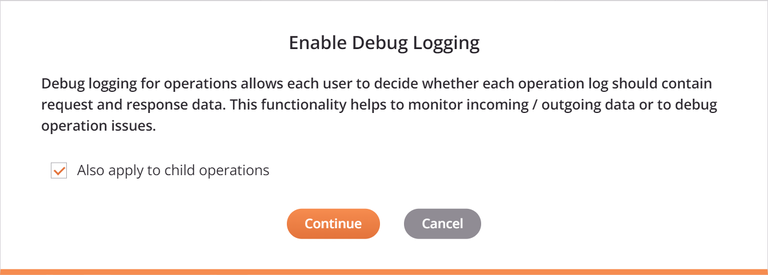
When operation debug logging is enabled, these types of logs are generated, depending on the type of agent:
-
Private agent: Debug log files for an operation. This option is used mainly for debugging problems during testing and should not be turned on in production as it can create very large files. Debug logging can also be enabled for the entire project from the private agent itself (see Operation debug logging). The debug log files are accessible directly on private agents and are downloadable through the Management Console Agents > Agents and Runtime Operations pages.
-
Private agent or cloud agent: Two types of logs can be generated:
-
Component Input and Output Data: Data written to a Cloud Studio operation log for an operation running on agent version 10.48 or later. The data is retained for 30 days by Harmony.
-
API Operation Logs: Operation logs for successful API operations (configured for custom APIs or OData services). By default, only API operations with errors are logged in the operation logs.
-
For additional details, see Operation debug logging for cloud agents or Operation debug logging for private agents.
Caution
The generation of component input and output data is unaffected by the agent group setting Enable Cloud Logging (see Agents > Agent groups). Component input and output data will be logged to the Harmony cloud even if cloud logging is disabled.
To disable generation of component input and output data in a private agent group, in the private agent configuration file under the
[VerboseLogging]section, setverbose.logging.enable=false.Warning
When component input and output data are generated, all request and response data for that operation are logged to the Harmony cloud and remain there for 30 days. Be aware that personally identifiable information (PII) and sensitive data such as credentials provided in a request payload will be visible in clear text in the input and output data within the Harmony cloud logs.
-
-
Run Success Operation Even If There Are No Matching Source Files: Select to force an upstream operation to be successful. This effectively lets you kick off an operation with an On Success condition (configured with an operation action) even if the trigger failed.
This option is applicable only if the operation contains an API, File Share, FTP, HTTP, Local Storage, SOAP, Temporary Storage, or Variable activity that is used as a source in the operation, and applies only when the operation has an On Success condition configured. By default, any On Success operations run only if they have a matching source file to process. This option can be useful for setting up later parts of a project without requiring success of a dependent operation.
Note
The setting
AlwaysRunSuccessOperationin the[OperationEngine]section of the private agent configuration file overrides the Run Success Operation Even If There Are No Matching Source Files setting. -
Enable Chunking: Select to enable chunking using the specified parameters:
-
Chunk Size: Enter a number of source records (nodes) to process for each thread. When chunking is enabled for operations that do not contain any Salesforce-based activities, the default chunk size is
1. When a Salesforce-based activity is added to an operation that does not have chunking enabled, chunking automatically becomes enabled with a default chunk size of200. If using a Salesforce-based bulk activity, you should change this default to a much larger number, such as 10,000. -
Number of Records per File: Enter a requested number of records to be placed in the target file. The default is
0, meaning there is no limit on the number of records per file. -
Max Number of Threads: Enter the number of concurrent threads to process. When chunking is enabled for operations that do not contain any Salesforce-based activities, the default number of threads is
1. When a Salesforce-based activity is added to an operation that does not have chunking enabled, chunking automatically becomes enabled with a default number of threads of2.
This option is present only if the operation contains a transformation or a database, NetSuite, Salesforce, Salesforce Service Cloud, ServiceMax, or SOAP activity, and is used for processing data to the target system in chunks. This allows for faster processing of large datasets and is also used to address record limits imposed by various web-service-based systems when making a request.
Note if you are using a Salesforce-based (Salesforce, Salesforce Service Cloud, or ServiceMax) endpoint:
-
If a Salesforce-based activity is added to an operation that does not have chunking enabled, chunking becomes enabled with default settings specifically for Salesforce-based activities as described above.
-
If a Salesforce-based activity is added to an operation that already has chunking enabled, the chunking settings are not changed. Likewise, if a Salesforce-based activity is removed from an operation, the chunking settings are not changed.
Additional information and best practices for chunking are provided in the next section, Chunking.
-
-
Save Changes: Click to save and close the operation settings.
-
Discard Changes: After making changes to the operation settings, click to close the settings without saving.
Chunking¶
Chunking is used to split the source data into multiple chunks based on the configured chunk size. The chunk size is the number of source records (nodes) for each chunk. The transformation is then performed on each chunk separately, with each source chunk producing one target chunk. The resulting target chunks combine to produce the final target.
Chunking can be used only if records are independent and from a non-LDAP source. We recommend using as large a chunk size as possible, making sure that the data for one chunk fits into available memory. For additional methods to limit the amount of memory a transformation uses, see Transformation processing.
Warning
Using chunking affects the behavior of global and project variables. See Use variables with chunking below.
API limitations¶
Many web service APIs (SOAP/REST) have size limitations. For example, a Salesforce-based upsert accepts only 200 records for each call. With sufficient memory, you could configure an operation to use a chunk size of 200. The source would be split into chunks of 200 records each, and each transformation would call the web service once with a 200-record chunk. This would be repeated until all records have been processed. The resulting target files would then be combined. (Note that you could also use Salesforce-based bulk activities to avoid the use of chunking.)
Parallel processing¶
If you have a large source and a multi-CPU computer, chunking can be used to split the source for parallel processing. Since each chunk is processed in isolation, several chunks can be processed in parallel. This applies only if the source records are independent of each other at the chunk node level. Web services can be called in parallel using chunking, improving performance.
When using chunking on an operation where the target is a database, note that the target data is first written to numerous temporary files (one for each chunk). These files are then combined to one target file, which is sent to the database for insert/update. If you set the Jitterbit variable jitterbit.target.db.commit_chunks to 1 or true when chunking is enabled, each chunk is instead committed to the database as it becomes available. This can improve performance significantly as the database insert/updates are performed in parallel.
Use variables with chunking¶
As chunking can invoke multi-threading, its use can affect the behavior of variables that are not shared between the threads.
Global and project variables are segregated between the instances of chunking, and although the data is combined, changes to these variables are not. Only changes made to the initial thread are preserved at the end of the transformation.
For example, if an operation — with chunking and multiple threads — has a transformation that changes a global variable, the global variable's value after the operation ends is that from the first thread. Any changes to the variable in other threads are independent and are discarded when the operation completes.
These global variables are passed to the other threads by value rather than by reference, ensuring that any changes to the variables are not reflected in other threads or operations. This is similar to the RunOperation function when in asynchronous mode.