Create single- or multiple-record output¶
Use case¶
A frequent scenario is where the source contains multiple records and efficient orchestration is enabled if the target files are written individually such that the file name contains a key value derived from a field value in the record.
The default behavior of Jitterbit is to create a single file containing multiple records when the source contains multiple records. This page also demonstrates (in Example 2) how to accomplish multiple record output using the SOURCE_CHUNK reserved global variable prefix.
Note
This design pattern uses Design Studio as an example; you may apply the same concepts in Cloud Studio using similar steps.
Example 1: Multiple records in single output file¶
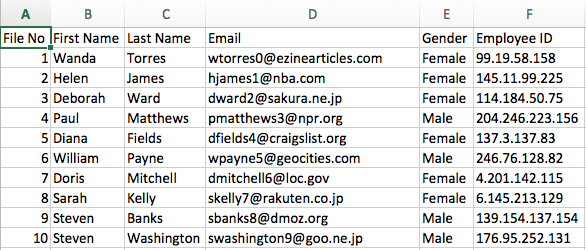
For these examples, assume that the source file contains a list of employees where one field contains an employee ID.
Source data example:
Create a basic Operation where we accept all the defaults:
Define the Source:
Simple mapping where the transformation shows the source and target records:
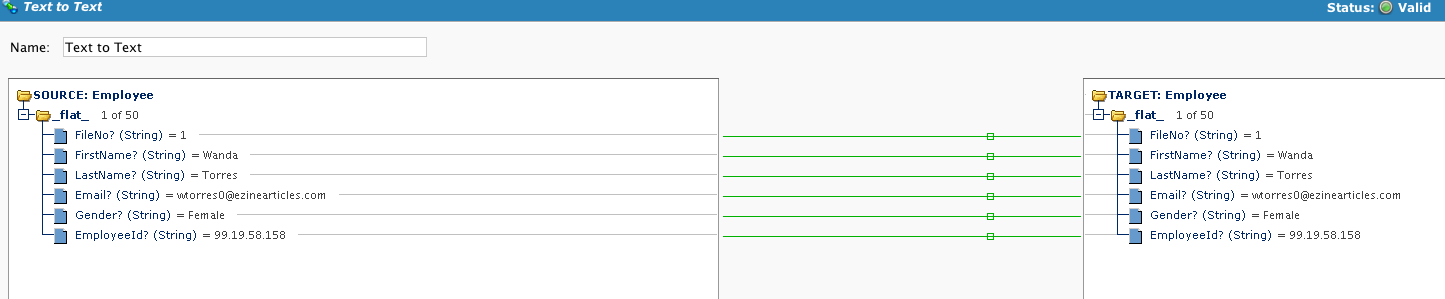
Define the Target:
The target file (Multiple records.txt) will be a single file that contains multiple records:

Example 2: Multiple output files containing a single record¶
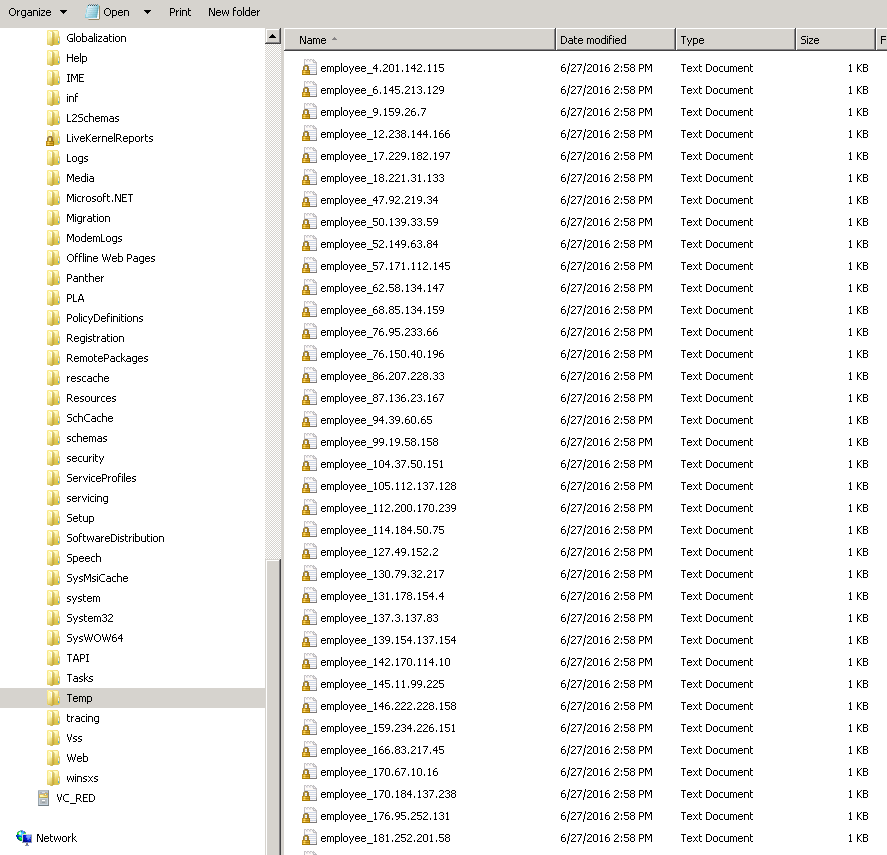
The target endpoint requires a file format where the employee ID is required in the file name. This means creating 50 records with each record in a file name patterned after employee_\<employee id>.txt.
Prior to introduction of SCOPE_CHUNK, the generation of multiple files containing a single record would require an additional set of operations to read the records and write them out individually.
Using SCOPE_CHUNK, a single operation can generate multiple records and provide control on the data-driven file name. This example will process a file for a different set of 50 employees that contains the same data fields as the source data file that is used in Example 1. The operation in this example creates 50 records, each ending in a file name of employee_\<employee id>.txt.
Caution
The SCOPE_CHUNK prefix syntax is not supported in operations with a transformation that uses conditional mapping.
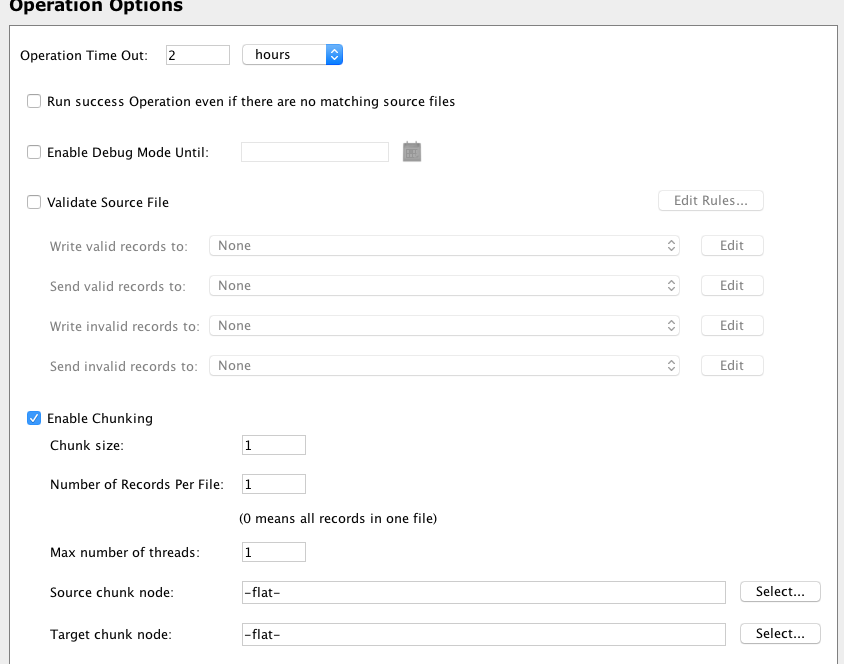
Set Enable Chunking in the Operation Options. Set Chunk size, Number of Records Per File and Max number of threads to 1. This will force the transformation to process one record at a time:
The mapping is similar, with the addition of applying a script to the last field. Note that when the operation is tested, only 1 record is processed.
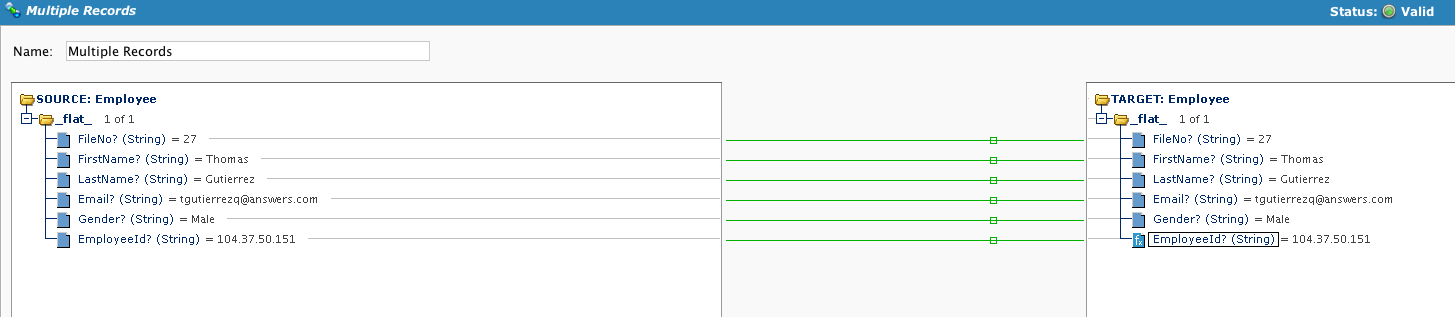
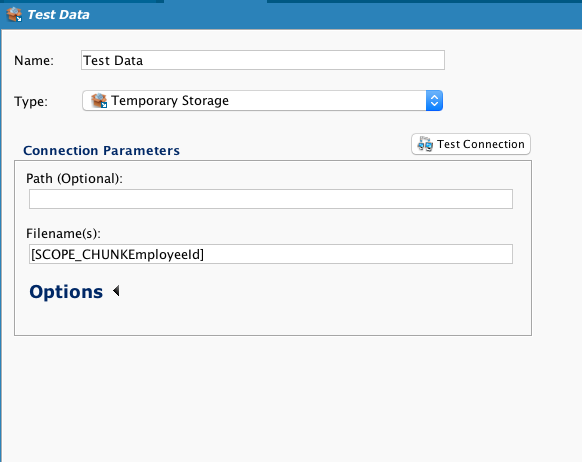
Create a Script on the last field. By building a global variable prefaced with SCOPE_CHUNK, and filling in the desired file name to include a record value, we can pass the global variable to the target.

Enter the global variable into the target's Filename(s) field:
When run, the operation now creates an individual file for each employee, containing only that one employee record, and individually named to include the employee ID. In the screen shot shown, the filename suffixes (.txt) are hidden: