Operation options in Jitterbit Design Studio¶
This page describes the options that are configurable for any operation. To reach these options, right-click on the background of any operation graph and select Options in the menu. The Operations Options window will display:
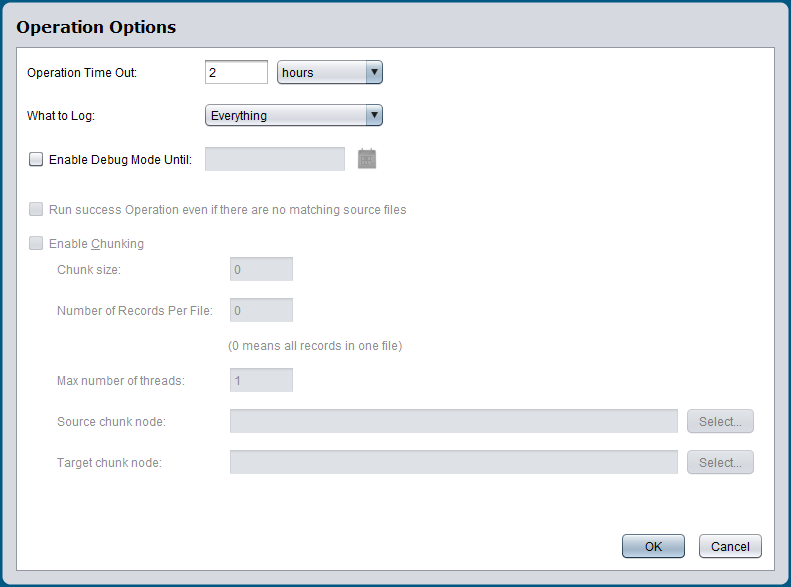
These sections describe the available operation options:
Operation time out¶
-
The Operation Time Out is the maximum amount of time the operation will run for before being canceled. If your operation has large datasets or is complex, this may cause the operation to take a longer time to run.
-
By default, the Operation Time Out is set to 2 hours. If the operation is running for more than 2 hours without completing or failing, it will be automatically canceled.
-
You may wish to increase this value if the operation has large datasets that are taking a long time to run. Or decrease it if the operations are time-sensitive; i.e., you do not want the operation to be accomplished if it cannot complete within a certain timeframe.
Note
Enabling the EnableAPITimeout setting in the private agent configuration file allows operations triggered by API Manager APIs to use these operation timeout settings.
What to log¶
- The What to Log option lets you choose between "Everything" or "Errors Only." These are the logs that you can view when you right-click on the background of an operation and choose Operation Log. Note that within the Operation Log, you also have the option to filter by errors only.
- By default, everything is logged. This includes success, canceled, pending, running, and error statuses.
- A reason that you may wish to select "Errors Only" prior to the log being generated is that if you are having operation latency issues this may improve them. This way, if you weren't planning on using the other non-error messages normally filtered out in the Operation Log, you can prevent them from being generated in the first place.
Enable debug mode¶
In the Operation Options window, select Enable Debug Mode Until and set a date for the setting to be turned off. This date is limited to 2 weeks from the current date. Logging will be turned off at the beginning of that date (12:00 am) using the timezone of the agent. Enabling debug mode for a specific operation can help if you are having issues with a particular operation and do not need to turn on debug logging for your entire project, which can create very large files within the directory.
When operation debug logging is enabled, these types of logs are generated, depending on the type of agent:
-
Private agent: Debug log files for an operation. This option is used mainly for debugging problems during testing and should not be turned on in production as it can create very large files. Debug logging can also be enabled for the entire project from the private agent itself (see Operation debug logging). The debug log files are accessible directly on private agents and are downloadable through the Management Console Agents and Runtime Operations pages.
-
Private agent or cloud agent: Operation logs for successful API operations (configured for custom APIs or OData services). By default, only API operations with errors are logged in the operation logs.
Run success operation¶
- The option Run Success Operation even if there are no matching source files applies to operations that have "OnSuccess" triggers configured.
- By default, your OnSuccess operations will only run if they have a matching source file to process.
- You have the option to "force" the previous operation to be successful, effectively letting you kick off the "OnSuccess" operation even if the trigger failed. This can be useful for setting up later parts of project without depending on success of a dependent operation.
Note
The parameter AlwaysRunSuccessOperation in the [OperationEngine] section of the jitterbit.conf file overrides the Run Success Operation Even If There Are No Matching Source Files setting.
Enable chunking¶
- Chunking allows Jitterbit to process data to the target system in chunks.
- The Chunk size tells Jitterbit how many source records to process per thread.
- The Number of Records Per File instructs Jitterbit to place only the requested number of records in the target file.
- The Max number of threads tells Jitterbit how many concurrent threads to process.
- The Source chunk node and Target chunk node enable the user to define what constitutes a record and should be set for hierarchical data structures and XML.
- By default, chunking is not enabled.
- This allows for faster processing of large datasets and is also used to address record limits imposed by various web-service-based systems when making a request.