Conexión de Amazon Redshift¶
Introducción¶
Una conexión de Amazon Redshift, creada mediante el conector de Amazon Redshift, establece acceso a Amazon Redshift. Una vez configurada una conexión, puede crear instancias de actividades de Amazon Redshift asociadas con esa conexión para usarlas como fuentes (para proporcionar datos en una operación) o como destinos (para consumir datos en una operación).
Nota
Este conector admite Habilitar reautenticación en caso de cambio política de la organización. Si está habilitado, un cambio en el Nombre de usuario maestro en esta conexión requiere que los usuarios vuelvan a ingresar la Contraseña maestra para la conexión.
Crear o Editar una Conexión de Amazon Redshift¶
Se crea una nueva conexión de Amazon Redshift mediante el conector de Amazon Redshift desde una de estas ubicaciones:
- La pestaña Conexiones de la paleta de componentes de diseño (consulte Paleta de Componentes de Diseño).
- La página Conexiones globales (vea Crear una conexión global en Conexiones globales).
Una conexión de Amazon Redshift existente se puede editar desde estas ubicaciones:
- La pestaña Conexiones de la paleta de componentes de diseño (consulte Paleta de Componentes de Diseño).
- La pestaña Componentes del panel del proyecto (consulte Menú de acciones de componentes en Pestaña Componentes del panel de proyecto).
- La página Conexiones globales (vea Editar una conexión global en Conexiones globales).
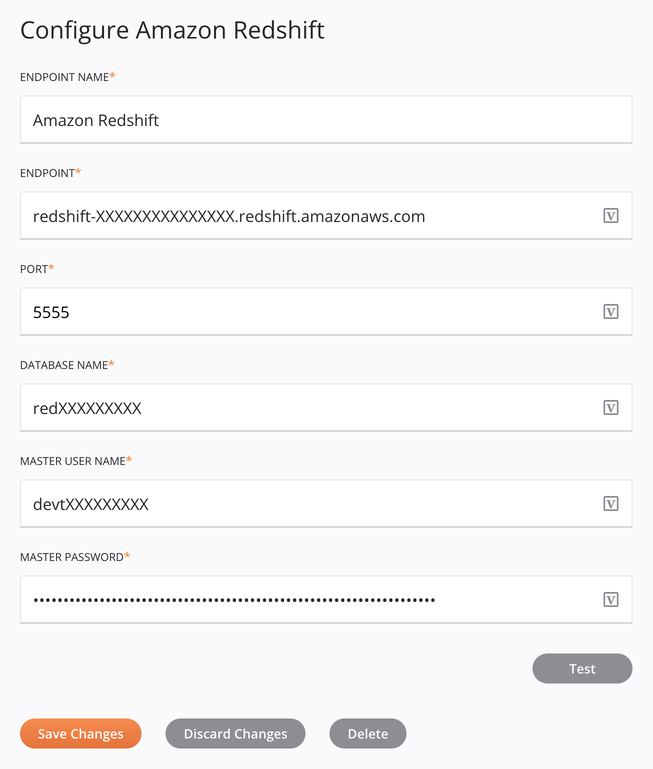
Configurar una Conexión de Amazon Redshift¶
A continuación se describe cada elemento de la interfaz de usuario de la pantalla de configuración de la conexión de Amazon Redshift.
Consejo
Campos con un ícono de variable ![]() admite el uso de variables globales, variables del proyecto, y variables de Jitterbit. Comience escribiendo un corchete abierto
admite el uso de variables globales, variables del proyecto, y variables de Jitterbit. Comience escribiendo un corchete abierto [ en el campo o haciendo clic en el icono de variable para mostrar una lista de las variables existentes para elegir.
-
Nombre de la conexión: Introduzca un nombre que se utilizará para identificar la conexión. El nombre debe ser único para cada conexión de Amazon Redshift y no debe contener barras diagonales (
/) o dos puntos (:). Este nombre también se utiliza para identificar el extremo de Amazon Redshift, que hace referencia tanto a una conexión específica como a sus actividades. -
Extremo: Introduzca el extremo del clúster de Amazon Redshift.
-
Puerto: Introduzca el número de puerto que se especificó cuando se creó el clúster. Si tiene un firewall, asegúrese de que este puerto esté abierto para su uso.
-
Nombre de la base de datos: Ingrese la base de datos que se creó para el clúster.
-
Nombre de usuario maestro: Ingrese el nombre de usuario maestro.
-
Contraseña maestra: Ingrese la contraseña maestra.
-
Prueba: Haga clic para verificar la conexión usando la configuración proporcionada. Cuando se prueba la conexión, los agentes del grupo de agentes asociado con el ambiente actual descargan la última versión del conector. Este conector admite la suspensión de la descarga de la última versión del conector mediante Desactivar actualización automática del conector política de la organización.
-
Guardar cambios: Haga clic para guardar y cerrar la configuración de conexión.
-
Descartar cambios: Después de realizar cambios en una configuración nueva o existente, haga clic para cerrar la configuración sin guardar. Un mensaje le pide que confirme que desea descartar los cambios.
-
Eliminar: Después de abrir una configuración de conexión existente, haga clic para eliminar permanentemente la conexión del proyecto y cerrar la configuración (consulte Dependencias de componentes, eliminación y eliminación). Un mensaje le pide que confirme que desea eliminar la conexión.
Próximos Pasos¶
Una vez creada una conexión de Amazon Redshift, coloca un tipo de actividad en el tela de diseño para crear instancias de actividad que se utilizarán como fuentes (para proporcionar datos en una operación) o como destinos (para consumir datos en una operación).
Se puede acceder a las acciones de menú para una conexión y sus tipos de actividad desde el panel del proyecto y la paleta de componentes de diseño. Para obtener más información, consulte Menús de acciones en Conceptos básicos del conector.
Estos tipos de actividades están disponibles:
-
Insertar en bloque: Inserta varios registros en una tabla en Amazon Redshift y está diseñado para usarse como destino en una operación. Esta actividad proporciona la opción de establecer la cantidad de registros por lote y la opción de detener el procesamiento de los registros restantes si se encuentra un error.
-
Consulta: Recupera registros de una tabla en Amazon Redshift y está diseñado para usarse como fuente en una operación.
-
Actualizar: Actualiza un objeto existente o crea un objeto nuevo en Amazon Redshift y está diseñado para usarse como destino en una operación.
-
Invocar procedimiento almacenado: Llama a un procedimiento almacenado desde un esquema en Amazon Redshift y está diseñado para usarse como destino en una operación.
-
Insertar registro: Inserta un registro en una tabla en Amazon Redshift y está diseñado para usarse como destino en una operación.
-
Actualizar registro: Actualiza un registro en una tabla en Amazon Redshift y está diseñado para usarse como destino en una operación.
-
Copiar: Inserta registros en una tabla en Amazon Redshift y está diseñado para usarse como destino para consumir datos en una operación.
-
Actualización masiva: Actualiza varios registros en una tabla en Amazon Redshift y está diseñado para usarse como destino en una operación. Esta actividad proporciona la opción de establecer la cantidad de registros por lote y la opción de detener el procesamiento de los registros restantes si se encuentra un error.
-
Eliminar el registro: Elimina un registro de Amazon Redshift y está diseñado para usarse como destino en una operación.