Actividad de Inserción de Snowflake¶
Introducción¶
Una actividad Snowflake Insertar, usando su conexión Snowflake, inserta datos de la tabla (ya sea como un archivo CSV o asignados directamente a columnas de una tabla) en Snowflake y está diseñado para usarse como destino para consumir datos en una operación.
Crear una Actividad de Inserción de Snowflake¶
Se crea una instancia de una actividad Snowflake Insertar a partir de una conexión Snowflake utilizando su tipo de actividad Insertar.
Para crear una instancia de una actividad, arrastre el tipo de actividad al tela de diseño o cópielo y péguelo en el tela de diseño. Para obtener más información, consulte Creación de una instancia de actividad en Reutilización de componentes.
Una actividad Insertar de Snowflake existente se puede editar desde estas ubicaciones:
- El tela de diseño (consulte Menú de acciones del componente en Tela de Diseño).
- La pestaña Componentes del panel del proyecto (consulte Menú de acciones de componentes en Pestaña Componentes del panel de proyecto).
Configurar una Actividad de Inserción de Snowflake¶
Siga estos pasos para configurar una actividad Insertar de Snowflake:
-
Paso 1: Ingrese un nombre y seleccione un objeto
Proporcione un nombre para la actividad y seleccione un objeto, ya sea una tabla o una vista. -
Paso 2: Seleccione un enfoque
Se admiten diferentes enfoques para insertar datos en Snowflake. Elija entre Stage File o SQL Insert. Al utilizar el enfoque Archivo de etapa, puede seleccionar los tipos de archivo de etapa Amazon S3 o Interno. -
Paso 3: revisar los esquemas de datos
Se muestran todos los esquemas de solicitud o respuesta generados desde el extremo.
Paso 1: Ingrese un Nombre y Seleccione un Objeto¶
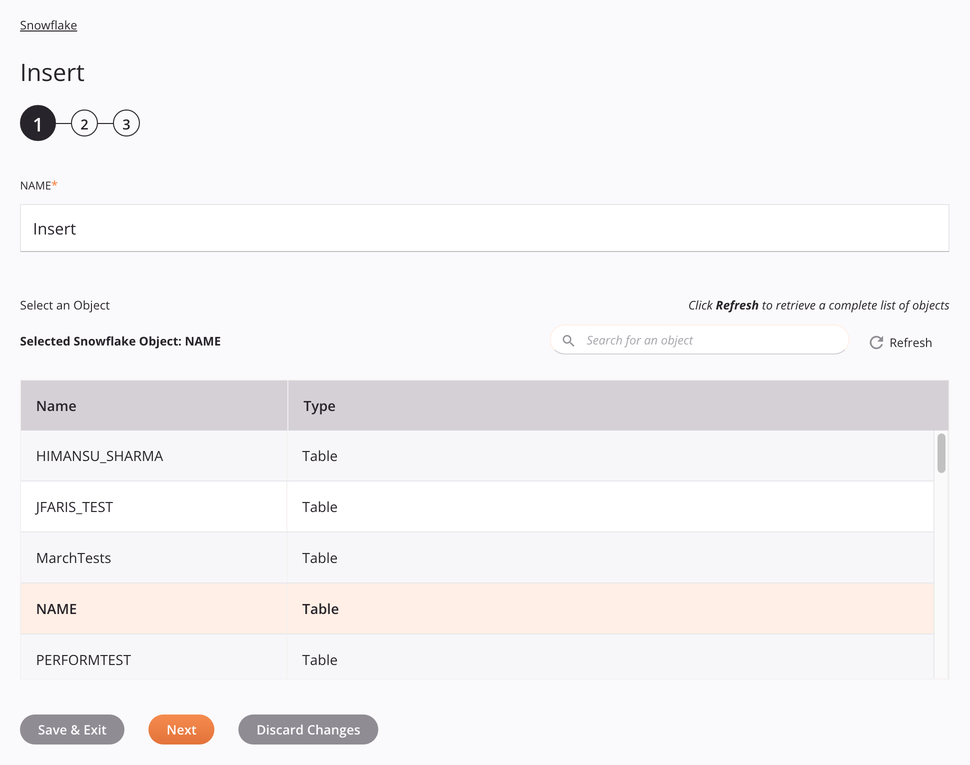
En este paso, proporcione un nombre para la actividad y seleccione una tabla o vista (consulte Descripción general de vistas de Snowflake). Cada elemento de la interfaz de usuario de este paso se describe a continuación.
-
Nombre: Introduzca un nombre para identificar la actividad. El nombre debe ser único para cada actividad de Snowflake Insertar y no debe contener barras diagonales.
/o dos puntos:. -
Seleccione un objeto: Esta sección muestra los objetos disponibles en el extremo de Snowflake. Al volver a abrir una configuración de actividad existente, solo se muestra el objeto seleccionado en lugar de recargar toda la lista de objetos.
-
Objeto de Snowflake seleccionado: Después de seleccionar un objeto, aparece aquí.
-
Buscar: Ingrese cualquier parte del nombre del objeto en el cuadro de búsqueda para filtrar la lista de objetos. La búsqueda no distingue entre mayúsculas y minúsculas. Si los objetos ya se muestran dentro de la tabla, los resultados de la tabla se filtran en tiempo real con cada pulsación de tecla. Para recargar objetos desde el extremo durante la búsqueda, ingrese los criterios de búsqueda y luego actualice, como se describe a continuación.
-
Actualizar: Haga clic en el icono de actualización
 o la palabra Actualizar para recargar objetos desde el extremo de Snowflake. Esto puede resultar útil si se han agregado objetos a Snowflake. Esta acción actualiza todos los metadatos utilizados para crear la tabla de objetos que se muestran en la configuración.
o la palabra Actualizar para recargar objetos desde el extremo de Snowflake. Esto puede resultar útil si se han agregado objetos a Snowflake. Esta acción actualiza todos los metadatos utilizados para crear la tabla de objetos que se muestran en la configuración. -
Seleccionar un objeto: Dentro de la tabla, haga clic en cualquier lugar de una fila para seleccionar un objeto. Sólo se puede seleccionar un objeto. La información disponible para cada objeto se obtiene del extremo de Snowflake:
-
Nombre: El nombre de un objeto, ya sea una tabla o una vista.
-
Tipo: El tipo de objeto, ya sea una tabla o una vista.
-
Consejo
Si la tabla no se completa con los objetos disponibles, la Conexión de Snowflake puede no tener éxito. Asegúrese de estar conectado volviendo a abrir la conexión y volviendo a probar las credenciales.
-
-
Guardar y salir: Si está habilitado, haga clic para guardar la configuración para este paso y cerrar la configuración de la actividad.
-
Siguiente: Haga clic para almacenar temporalmente la configuración para este paso y continuar con el siguiente. La configuración no se guardará hasta que haga clic en el botón Finalizado en el último paso.
-
Descartar cambios: Después de realizar cambios, haga clic para cerrar la configuración sin guardar los cambios realizados en ningún paso. Un mensaje le pide que confirme que desea descartar los cambios.
Paso 2: Seleccione un Enfoque¶
Se admiten diferentes enfoques para insertar datos en Snowflake. Elija entre Inserción SQL o Archivo de etapa. Cuando se utiliza el método Stage File, se seleccionan los tipos de archivos de etapa Amazon S3 o Internal.
- Enfoque de inserción SQL
- Enfoque de archivo de etapa de Amazon S3
- Enfoque de archivo de etapa de Google Cloud Storage
- Enfoque de archivo de etapa interna
- Enfoque de archivo de etapa de Microsoft Azure
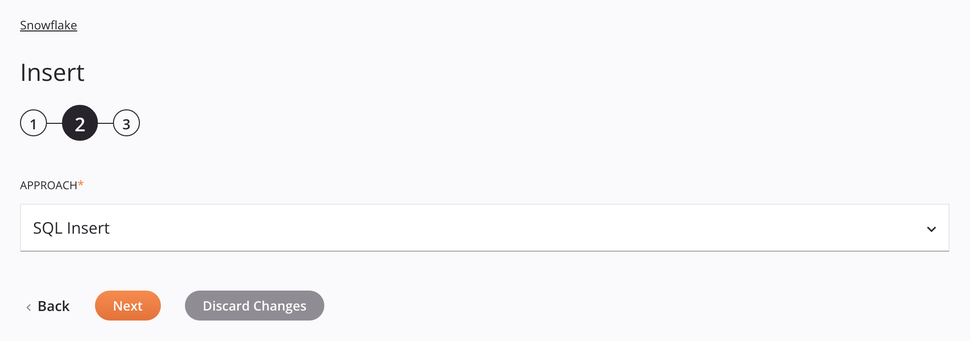
enfoque de Inserción SQL¶
Para este enfoque, las columnas de la tabla se mostrarán en el paso del esquema de datos que sigue, lo que permitirá asignarlas en una transformación.
-
Enfoque: Utilice el menú desplegable para seleccionar Inserción SQL.
-
Volver: Haga clic para regresar al paso anterior y almacenar temporalmente la configuración.
-
Siguiente: Haga clic para continuar con el siguiente paso y almacenar temporalmente la configuración. La configuración no se guardará hasta que haga clic en el botón Finalizado en el último paso.
-
Descartar cambios: Después de realizar cambios, haga clic para cerrar la configuración sin guardar los cambios realizados en ningún paso. Un mensaje le pide que confirme que desea descartar los cambios.
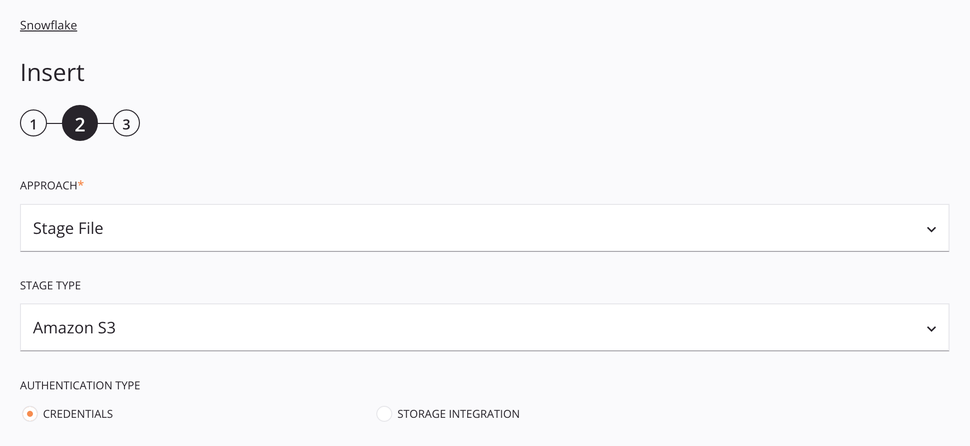
Enfoque de Archivo de Etapa de Amazon S3¶
Este enfoque permite insertar un archivo CSV en Snowflake utilizando una fuente de Amazon S3. El archivo se prepara y luego se copia en la tabla siguiendo las especificaciones del esquema de datos de la solicitud.
Para obtener información sobre cómo realizar solicitudes a Amazon S3, consulte Realización de solicitudes en la documentación de Amazon S3.
-
Enfoque: Utilice el menú desplegable para seleccionar Stage File.
-
Tipo de etapa: Elija Amazon S3 para recuperar datos del almacenamiento de Amazon S3.
-
Tipo de autenticación: Elija entre usar Credenciales o Integración de almacenamiento. Credenciales requiere el ID de la clave de acceso de Amazon S3 y la clave de acceso secreta. Integración de almacenamiento requiere solo el nombre de la integración de almacenamiento. Estos tipos de autenticación se tratan a continuación.
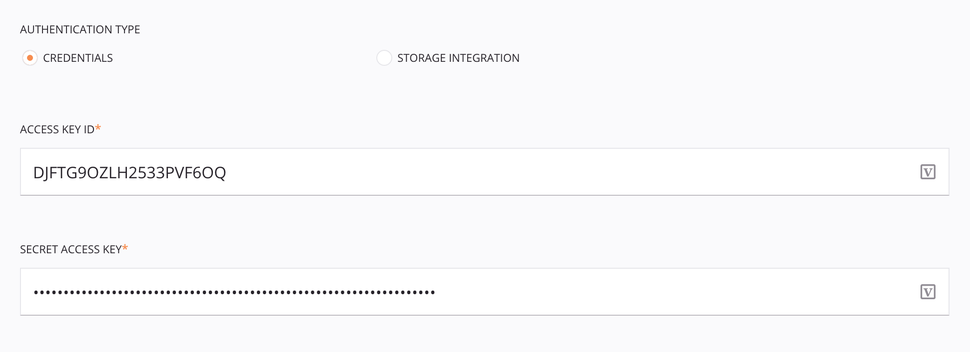
Autenticación de Credenciales¶
El tipo de autenticación Credenciales requiere el ID de la clave de acceso de Amazon S3 y la clave de acceso secreta (para obtener información sobre cómo realizar solicitudes a Amazon S3, consulte Realización de solicitudes en la documentación de Amazon S3).
-
Tipo de autenticación: Elija Credenciales.
-
ID de clave de acceso: Introduzca el ID de clave de acceso de Amazon S3.
-
Clave de acceso secreta: Ingrese la clave de acceso secreta de Amazon S3.
Autenticación de Integración de Almacenamiento¶
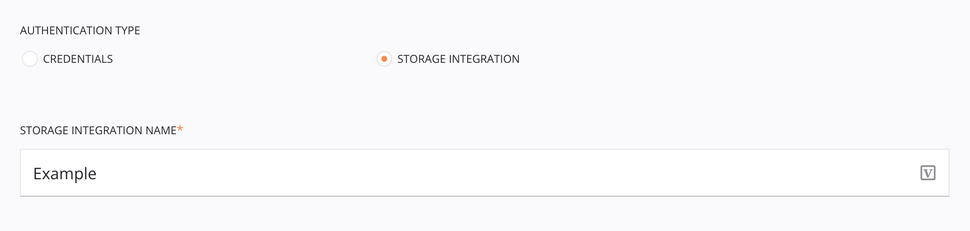
El tipo de autenticación Integración de almacenamiento requiere la creación de una integración de almacenamiento Snowflake. Para obtener información sobre cómo crear una integración de almacenamiento de Snowflake, consulte Crear integración de almacenamiento en la documentación de Snowflake.
-
Tipo de autenticación: Elija Integración de almacenamiento.
-
Nombre de la integración de almacenamiento: Ingrese el nombre de la integración de almacenamiento de Snowflake.
Opciones Adicionales¶
Tanto para la autenticación de Credenciales como de Integración de almacenamiento, existen estas opciones adicionales:
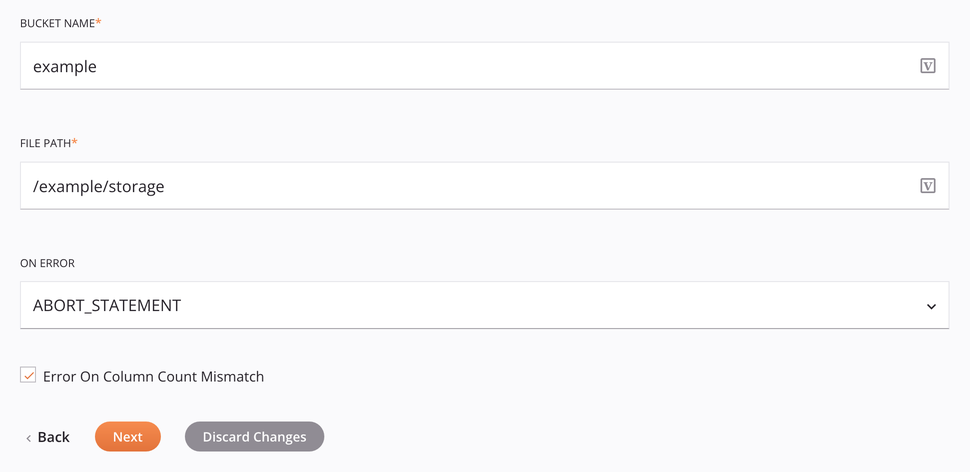
-
Nombre del depósito: Introduzca un nombre de depósito válido para un depósito existente en el servidor Amazon S3. Esto se ignora si
bucketNamese proporciona en el esquema de datosInsertAmazonS3Request. -
Ruta del archivo: Introduzca la ruta del archivo.
-
En caso de error: Elija una de estas opciones en el menú desplegable En caso de error; Aparecerán opciones adicionales según corresponda:
-
Abort_Statement: Anula el procesamiento si se encuentra algún error.
-
Continuar: Continúa cargando el archivo incluso si se encuentran errores.
-
Skip_File: Omite el archivo si se encuentra algún error en él.
-
Skip_File_\<num>: Omite el archivo cuando el número de errores en el archivo iguala o excede el número especificado en Omitir número de archivo.
-
Skip_File_\<num>%: Omite el archivo cuando el porcentaje de errores en el archivo excede el porcentaje especificado en Omitir porcentaje de número de archivo.
-
-
Error al no coincidir el recuento de columnas: Si se selecciona, informa un error en el nodo de error del esquema de respuesta si los recuentos de columnas de origen y de destino no coinciden. Si no selecciona esta opción, la operación no falla y se insertan los datos proporcionados.
-
Volver: Haga clic para regresar al paso anterior y almacenar temporalmente la configuración.
-
Siguiente: Haga clic para continuar con el siguiente paso y almacenar temporalmente la configuración. La configuración no se guardará hasta que haga clic en el botón Finalizado en el último paso.
-
Descartar cambios: Después de realizar cambios, haga clic para cerrar la configuración sin guardar los cambios realizados en ningún paso. Un mensaje le pide que confirme que desea descartar los cambios.
enfoque de Archivo de Etapa Interna¶
Este enfoque permite insertar un archivo CSV en Snowflake. El archivo se preparará y luego se copiará en la tabla siguiendo las especificaciones del esquema de datos de la solicitud.
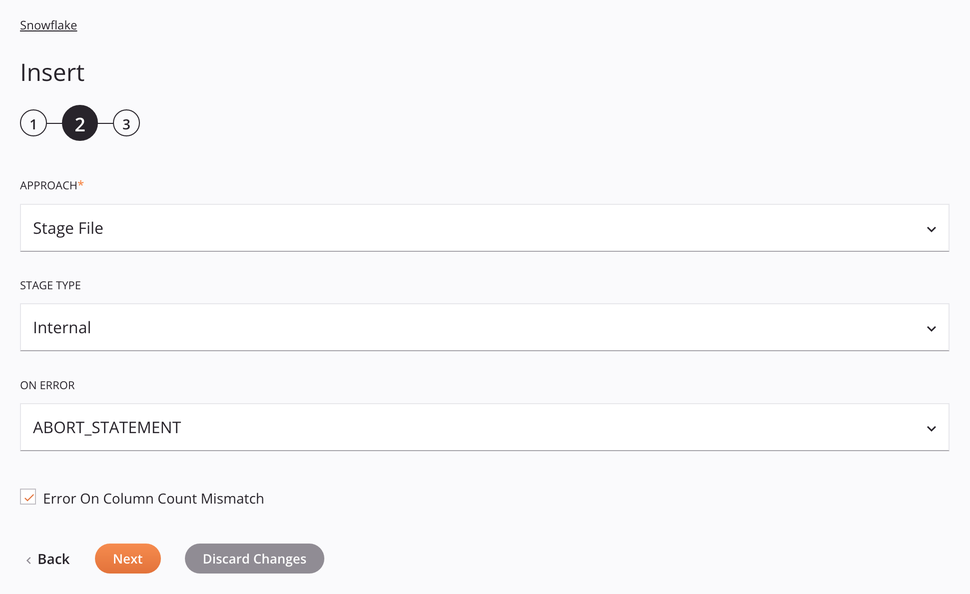
-
Enfoque: Utilice el menú desplegable para seleccionar Stage File.
-
Tipo de etapa: Elija Interno para recuperar los datos de una fuente interna.
-
En caso de error: Elija una de estas opciones en el menú desplegable En caso de error; Aparecerán opciones adicionales según corresponda:
-
Abort_Statement: Anula el procesamiento si se encuentra algún error.
-
Continuar: Continúa cargando el archivo incluso si se encuentran errores.
-
Skip_File: Omite el archivo si se encuentra algún error en él.
-
Skip_File_\<num>: Omite el archivo cuando el número de errores en el archivo iguala o excede el número especificado en Omitir número de archivo.
-
Skip_File_\<num>%: Omite el archivo cuando el porcentaje de errores en el archivo excede el porcentaje especificado en Omitir porcentaje de número de archivo.
-
-
Error al no coincidir el recuento de columnas: Si se selecciona, informa un error en el nodo de error del esquema de respuesta si los recuentos de columnas de origen y de destino no coinciden. Si no selecciona esta opción, la operación no falla y se insertan los datos proporcionados.
-
Volver: Haga clic para regresar al paso anterior y almacenar temporalmente la configuración.
-
Siguiente: Haga clic para continuar con el siguiente paso y almacenar temporalmente la configuración. La configuración no se guardará hasta que haga clic en el botón Finalizado en el último paso.
-
Descartar cambios: Después de realizar cambios, haga clic para cerrar la configuración sin guardar los cambios realizados en ningún paso. Un mensaje le pide que confirme que desea descartar los cambios.
Enfoque de Archivos de Etapa de Google Cloud Storage¶
Este enfoque permite insertar un archivo CSV en Google Cloud Storage. El archivo se preparará y luego se copiará en la tabla siguiendo las especificaciones del esquema de datos de la solicitud.
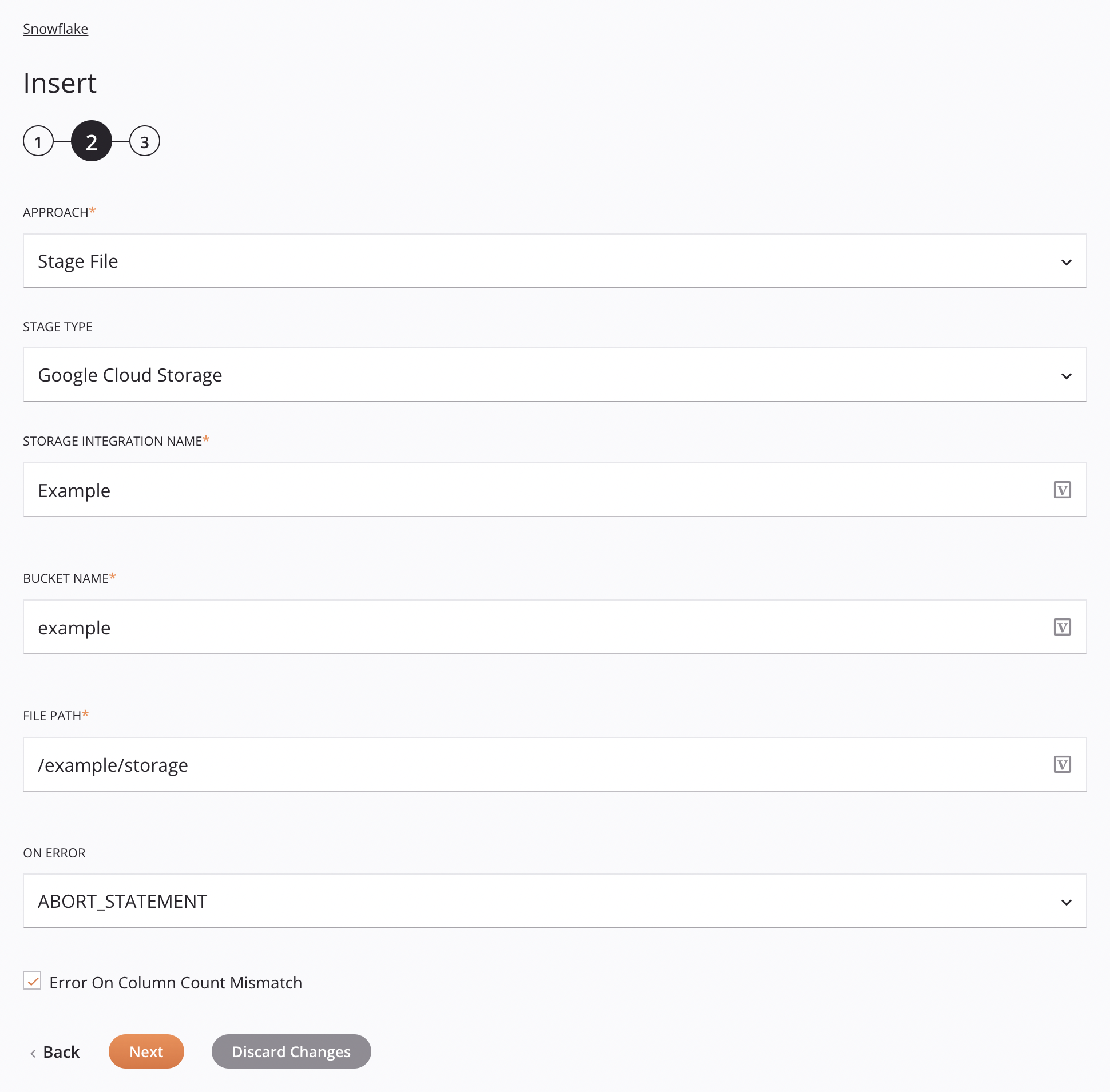
-
Enfoque: Utilice el menú desplegable para seleccionar Stage File.
-
Tipo de etapa: Elija Google Cloud Storage para recuperar los datos de una fuente interna.
-
Nombre de la integración de almacenamiento: Ingrese el nombre de la integración de almacenamiento de Snowflake.
-
Nombre del depósito: Ingrese un nombre de depósito válido para un depósito existente en Google Cloud Storage. Esto se ignora si
bucketNamese proporciona en el esquema de datosInsertGoogleCloudRequest. -
Ruta del archivo: Introduzca la ruta del archivo.
-
En caso de error: Elija una de estas opciones en el menú desplegable En caso de error; Aparecerán opciones adicionales según corresponda:
-
Abort_Statement: Anula el procesamiento si se encuentra algún error.
-
Continuar: Continúa cargando el archivo incluso si se encuentran errores.
-
Skip_File: Omite el archivo si se encuentra algún error en él.
-
Skip_File_\<num>: Omite el archivo cuando el número de errores en el archivo iguala o excede el número especificado en Omitir número de archivo.
-
Skip_File_\<num>%: Omite el archivo cuando el porcentaje de errores en el archivo excede el porcentaje especificado en Omitir porcentaje de número de archivo.
-
-
Error al no coincidir el recuento de columnas: Si se selecciona, informa un error en el nodo de error del esquema de respuesta si los recuentos de columnas de origen y de destino no coinciden. Si no selecciona esta opción, la operación no falla y se insertan los datos proporcionados.
-
Volver: Haga clic para regresar al paso anterior y almacenar temporalmente la configuración.
-
Siguiente: Haga clic para continuar con el siguiente paso y almacenar temporalmente la configuración. La configuración no se guardará hasta que haga clic en el botón Finalizado en el último paso.
-
Descartar cambios: Después de realizar cambios, haga clic para cerrar la configuración sin guardar los cambios realizados en ningún paso. Un mensaje le pide que confirme que desea descartar los cambios.
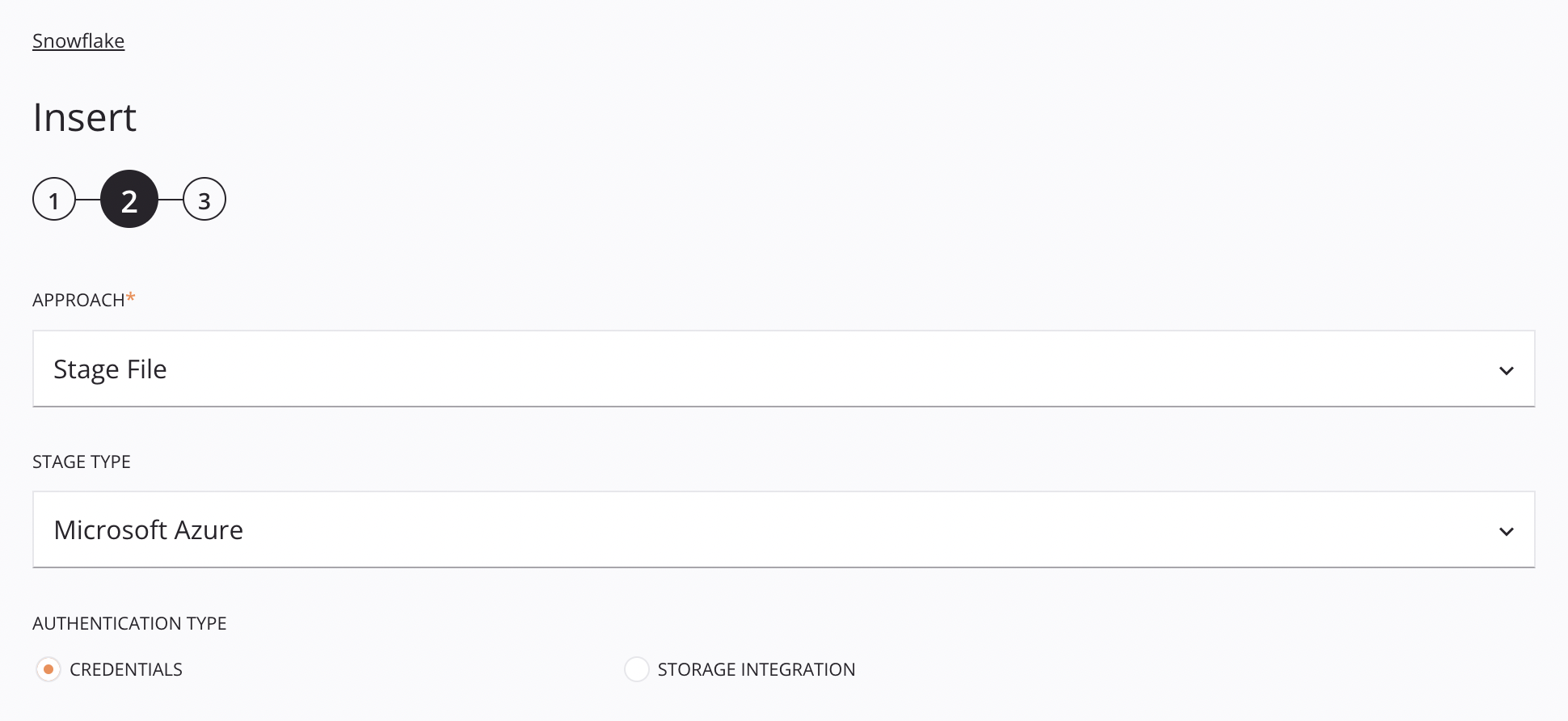
enfoque de Archivo de Etapa de Microsoft Azure¶
Este enfoque permite insertar un archivo CSV en Snowflake utilizando una fuente de Microsoft Azure. El archivo se prepara y luego se copia en la tabla siguiendo las especificaciones del esquema de datos de la solicitud.
-
Enfoque: Utilice el menú desplegable para seleccionar Stage File.
-
Tipo de etapa: Elija Microsoft Azure para recuperar datos de los contenedores de almacenamiento de Microsoft Azure.
-
Tipo de autenticación: Elija entre usar Credenciales o Integración de almacenamiento. Credenciales requiere un token de firma de acceso compartido (SAS) de Microsoft Azure y un nombre de cuenta de almacenamiento. Integración de almacenamiento solo requiere un nombre de integración de almacenamiento. Estos tipos de autenticación se tratan a continuación.
Autenticación de Credenciales¶
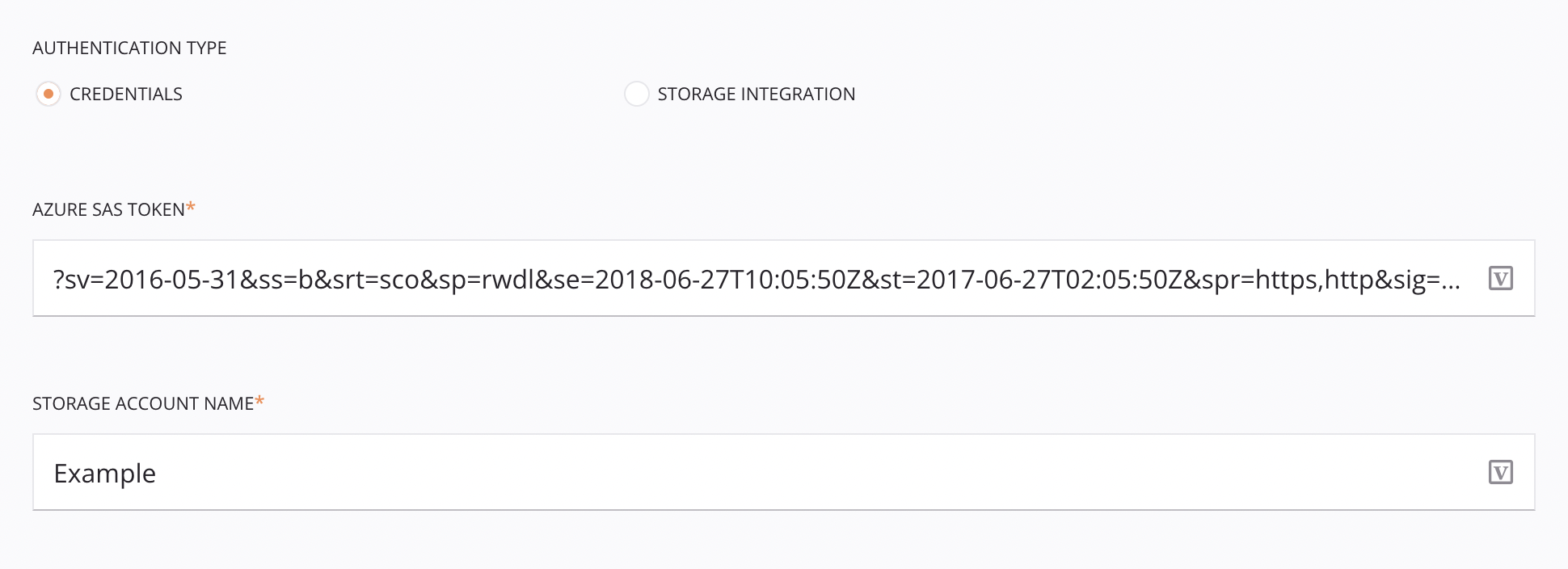
El tipo de autenticación Credenciales requiere un token SAS de Microsoft Azure y un nombre de cuenta de almacenamiento.
-
Tipo de autenticación: Elija Credenciales.
-
Token SAS de Azure: Introduzca el token SAS de Microsoft Azure. Para obtener información sobre la creación de tokens SAS para contenedores de almacenamiento en Microsoft Azure, consulte Crear tokens SAS para sus contenedores de almacenamiento en la documentación de Microsoft Azure.
-
Nombre de la cuenta de almacenamiento: Introduzca el nombre de la cuenta de almacenamiento de Microsoft Azure.
Autenticación de Integración de Almacenamiento¶
El tipo de autenticación Integración de almacenamiento requiere la creación de una integración de almacenamiento Snowflake. Para obtener información sobre cómo crear una integración de almacenamiento de Snowflake, consulte Crear integración de almacenamiento en la documentación de Snowflake.

-
Tipo de autenticación: Elija Integración de almacenamiento.
-
Nombre de la integración de almacenamiento: Ingrese el nombre de la integración de almacenamiento de Snowflake.
Opciones Adicionales¶
Tanto para la autenticación de Credenciales como de Integración de almacenamiento, existen estas opciones adicionales:
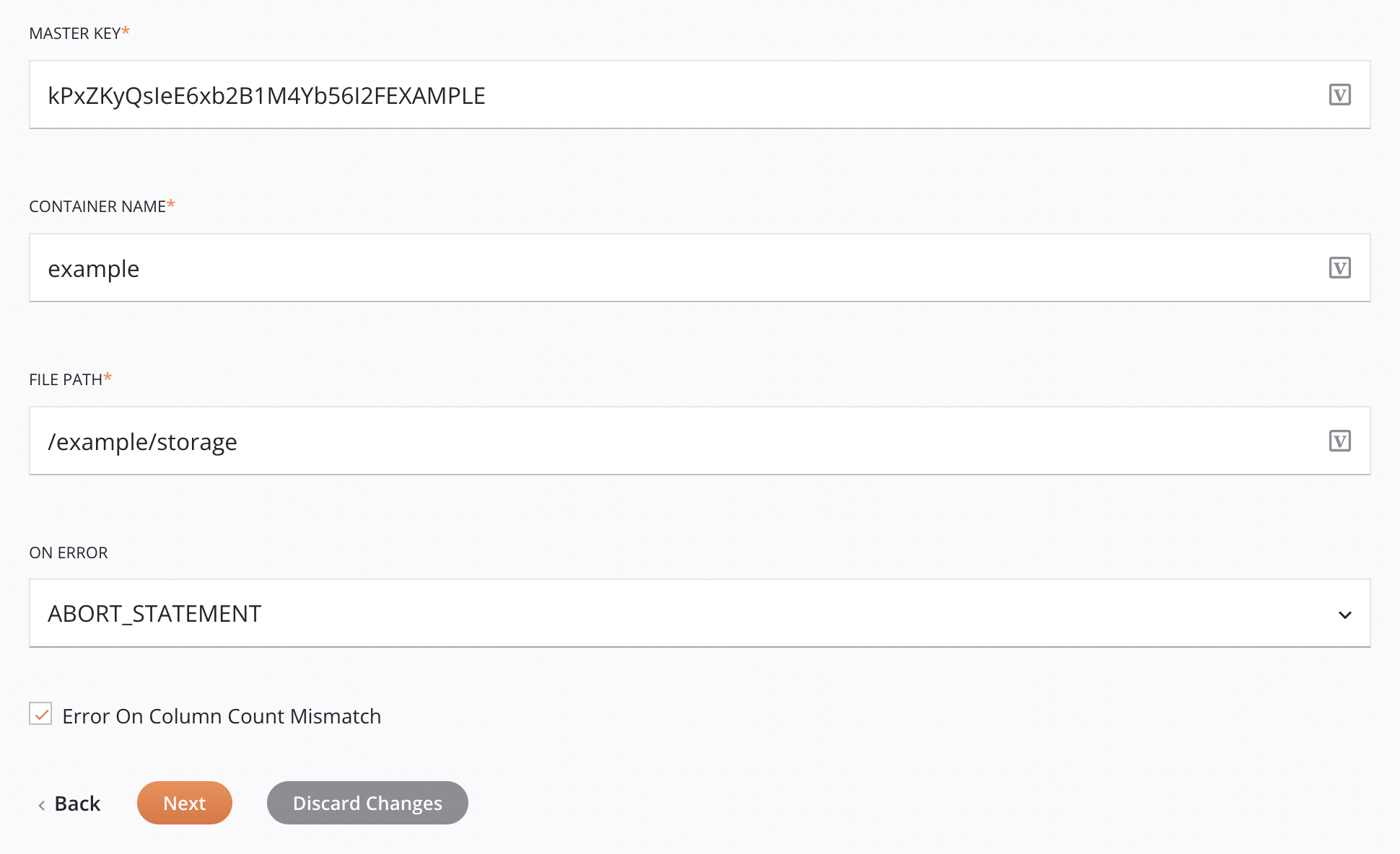
-
Clave maestra: Ingrese la clave maestra utilizada para el cifrado del lado del cliente (CSE) en Microsoft Azure. Esto se ignora si
azureMasterKeyse proporciona en el esquema de datosInsertMicrosoftAzureCloudRequest.Nota
Para obtener información sobre la creación de claves en Microsoft Azure, consulte Inicio rápido: configurar y recuperar una clave de Azure Key Vault mediante el portal de Azure en la documentación de Microsoft Azure.
Para obtener información sobre el almacenamiento CSE en Microsoft Azure, consulte cifrado del lado del cliente para blobs en la documentación de Microsoft Azure.
-
Nombre del contenedor: Ingrese un nombre de depósito válido para un contenedor de almacenamiento existente en Microsoft Azure. Esto se ignora si
containerNamese proporciona en el esquema de datosInsertMicrosoftAzureCloudRequest. -
Ruta del archivo: Introduzca la ruta del archivo.
-
En caso de error: Elija una de estas opciones en el menú desplegable En caso de error; Aparecerán opciones adicionales según corresponda:
-
Abort_Statement: Anula el procesamiento si se encuentra algún error.
-
Continuar: Continúa cargando el archivo incluso si se encuentran errores.
-
Skip_File: Omite el archivo si se encuentra algún error en él.
-
Skip_File_\<num>: Omite el archivo cuando el número de errores en el archivo iguala o excede el número especificado en Omitir número de archivo.
-
Skip_File_\<num>%: Omite el archivo cuando el porcentaje de errores en el archivo excede el porcentaje especificado en Omitir porcentaje de número de archivo.
-
-
Error al no coincidir el recuento de columnas: Si se selecciona, informa un error en el nodo de error del esquema de respuesta si los recuentos de columnas de origen y de destino no coinciden. Si no selecciona esta opción, la operación no falla y se insertan los datos proporcionados.
-
Volver: Haga clic para regresar al paso anterior y almacenar temporalmente la configuración.
-
Siguiente: Haga clic para continuar con el siguiente paso y almacenar temporalmente la configuración. La configuración no se guardará hasta que haga clic en el botón Finalizado en el último paso.
-
Descartar cambios: Después de realizar cambios, haga clic para cerrar la configuración sin guardar los cambios realizados en ningún paso. Un mensaje le pide que confirme que desea descartar los cambios.
Paso 3: Revisar los Esquemas de Datos¶
Se muestran los esquemas de solicitud y respuesta generados desde el extremo. Los esquemas mostrados dependen del Enfoque especificado en el paso anterior.
Estas subsecciones describen las estructuras de solicitud y respuesta para cada combinación de enfoque y tipo de etapa:
- Enfoque de inserción SQL
- Enfoque de archivo de etapa de Amazon S3
- Enfoque de archivo de etapa de Google Cloud Storage
- Enfoque de archivo de etapa interna
- Enfoque de archivo de etapa de Microsoft Azure
Estas acciones están disponibles con cada enfoque:
-
Esquemas de datos: Estos esquemas de datos se heredan mediante transformaciones adyacentes y se muestran nuevamente durante asignación de transformación.
Nota
Los datos proporcionados en una transformación tienen prioridad sobre la configuración de la actividad.
El conector Snowflake utiliza el Controlador JDBC Snowflake y los comandos SQL de Snowflake. Consulte la documentación de la API para obtener información sobre los campos y nodos del esquema.
-
Actualizar: Haga clic en el icono de actualización
o la palabra Actualizar para regenerar esquemas desde el extremo de Snowflake. Esta acción también regenera un esquema en otras ubicaciones del proyecto donde se hace referencia al mismo esquema, como en una transformación adyacente. -
Volver: Haga clic para almacenar temporalmente la configuración de este paso y volver al paso anterior.
-
Terminado: Haga clic para guardar la configuración de todos los pasos y cerrar la configuración de la actividad.
-
Descartar cambios: Después de realizar cambios, haga clic para cerrar la configuración sin guardar los cambios realizados en ningún paso. Un mensaje le pide que confirme que desea descartar los cambios.
enfoque de Inserción SQL¶
Si el enfoque es SQL Insert, se mostrarán las columnas de la tabla, lo que permitirá asignarlas en una transformación.
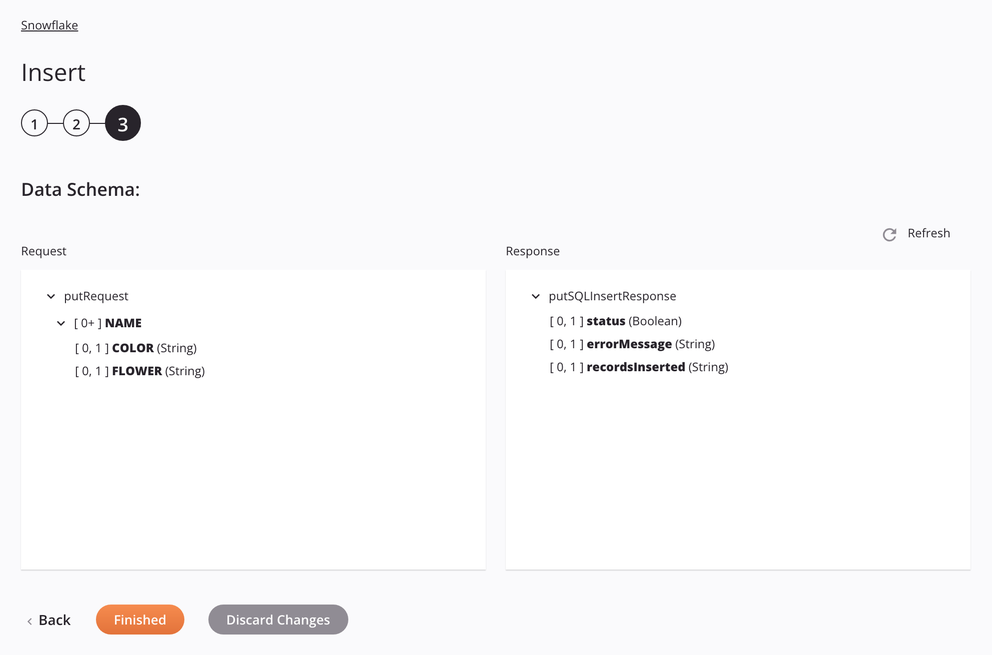
-
Pedido
Solicitar campo/nodo de esquema Notas tableNodo que muestra el nombre de la tabla. column_ANombre de la primera columna de la tabla. column_BNombre de la segunda columna de la tabla. . . .Columnas sucesivas de la tabla. -
Respuesta
Campo/nodo del esquema de respuesta Notas statusBandera booleana que indica si la inserción del registro fue exitosa. errorMessageMensaje de error descriptivo si se produce un error durante la inserción. recordsInsertedNúmero de registros insertados si la inserción se realizó correctamente.
Enfoque de Archivo de Etapa de Amazon S3¶
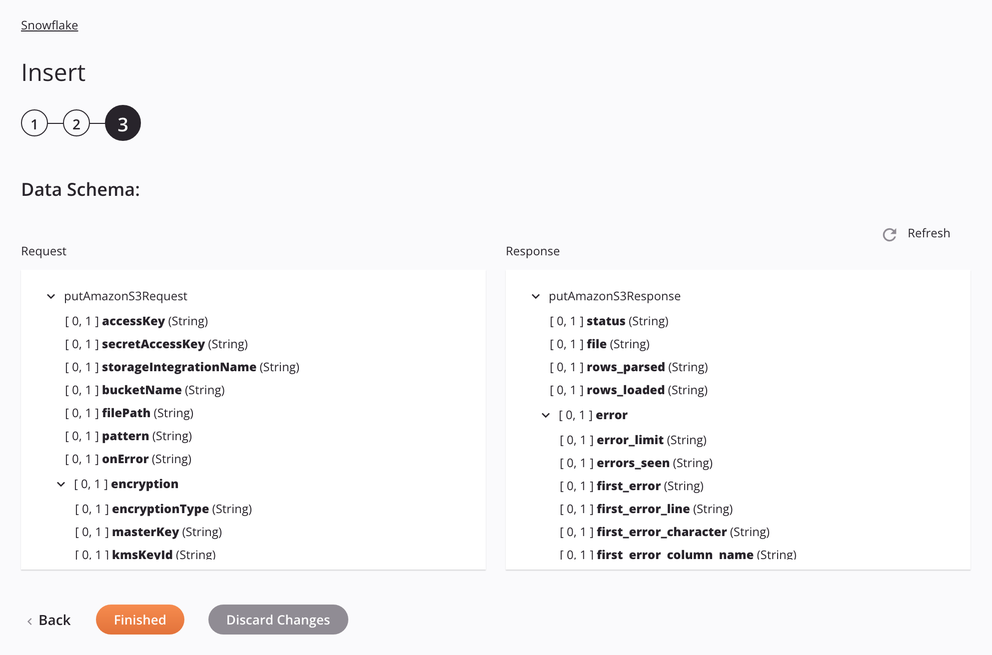
Si el enfoque es Archivo de etapa de Amazon S3, las especificaciones para preparar e insertar un archivo CSV se mostrarán en el esquema de datos para que se puedan asignar en una transformación. El patrón utilizado es hacer coincidir un solo archivo. Si el patrón coincide con más de un archivo, la actividad generará un error con un mensaje descriptivo.
-
Pedido
Solicitar campo/nodo de esquema Notas accessKeyID de clave de acceso de Amazon S3. secretAccessKeyClave de acceso secreta de Amazon S3. storageintegrationNameNombre de la integración de almacenamiento de Snowflake que se utilizará para la autenticación de la integración de almacenamiento de Snowflake. bucketNameNombre de depósito válido para un depósito existente en el servidor Amazon S3. filePathUbicación del archivo de etapa en el depósito de Amazon S3. patternPatrón de expresión regular utilizado para encontrar el archivo en el escenario; si compressionesGZIP,[.]gzse adjunta al patrón.onErrorEn caso de error opción seleccionada. encryptionNodo que representa el cifrado. encryptionTypeTipo de cifrado de Amazon S3 (ya sea cifrado del lado del servidor o cifrado del lado del cliente). masterKeyClave maestra de Amazon S3. kmsKeyIdServicio de administración de claves de Amazon Identificación maestra. fileFormatNodo que representa el formato del archivo. nullIfUna cadena para convertir a SQL NULL; de forma predeterminada, es una cadena vacía. Ver elNULL_IFopción del SnowflakeCOPY INTO<location>documentación.enclosingCharCarácter utilizado para encerrar campos de datos; ver el FIELD_OPTIONALLY_ENCLOSED_BYopción del SnowflakeCOPY INTO<location>documentación.Nota
El
enclosingCharpuede ser una comilla simple'o carácter de comilla doble". Para utilizar el carácter de comilla simple, utilice el carácter octal'o el maleficio0x27representaciones o utilizar un escape de comilla simple doble''. Cuando un campo contiene este carácter, escápelo usando el mismo carácter.compressionEl algoritmo de compresión utilizado para los archivos de datos. GZIPoNONEson compatibles. Consulte la Opción de compresión del SnowflakeCOPY INTO<location>documentación.skipHeaderNúmero de líneas al inicio del archivo fuente que se van a omitir. errorOnColumnCountMismatchIndicador booleano para informar un error si los recuentos de origen y destino del esquema de respuesta no coinciden. fieldDelimiterEl carácter delimitador utilizado para separar campos de datos; ver el FIELD_DELIMITERopción del SnowflakeCOPY INTO<table>documentación.recordDelimiterEl carácter delimitador utilizado para separar grupos de campos; ver el RECORD_DELIMITERopción del SnowflakeCOPY INTO<table>documentación. -
Respuesta
Campo/nodo del esquema de respuesta Notas statusEstado devuelto. fileNombre del archivo CSV preparado procesado al insertar datos en la tabla Snowflake. rows_parsedNúmero de filas analizadas del archivo CSV. rows_loadedNúmero de filas cargadas desde el archivo CSV en la tabla Snowflake sin errores. errorNodo que representa los mensajes de error. error_limitNúmero de errores que hacen que el archivo se omita según lo establecido en Skip_File_\<num>. errors_seenRecuento de errores vistos. first_errorEl primer error en el archivo fuente. first_error_lineEl número de primera línea del primer error. first_error_characterEl primer carácter del primer error. first_error_column_nameEl nombre de la columna de la primera ubicación del error.
Enfoque de Archivos de Etapa de Google Cloud Storage¶
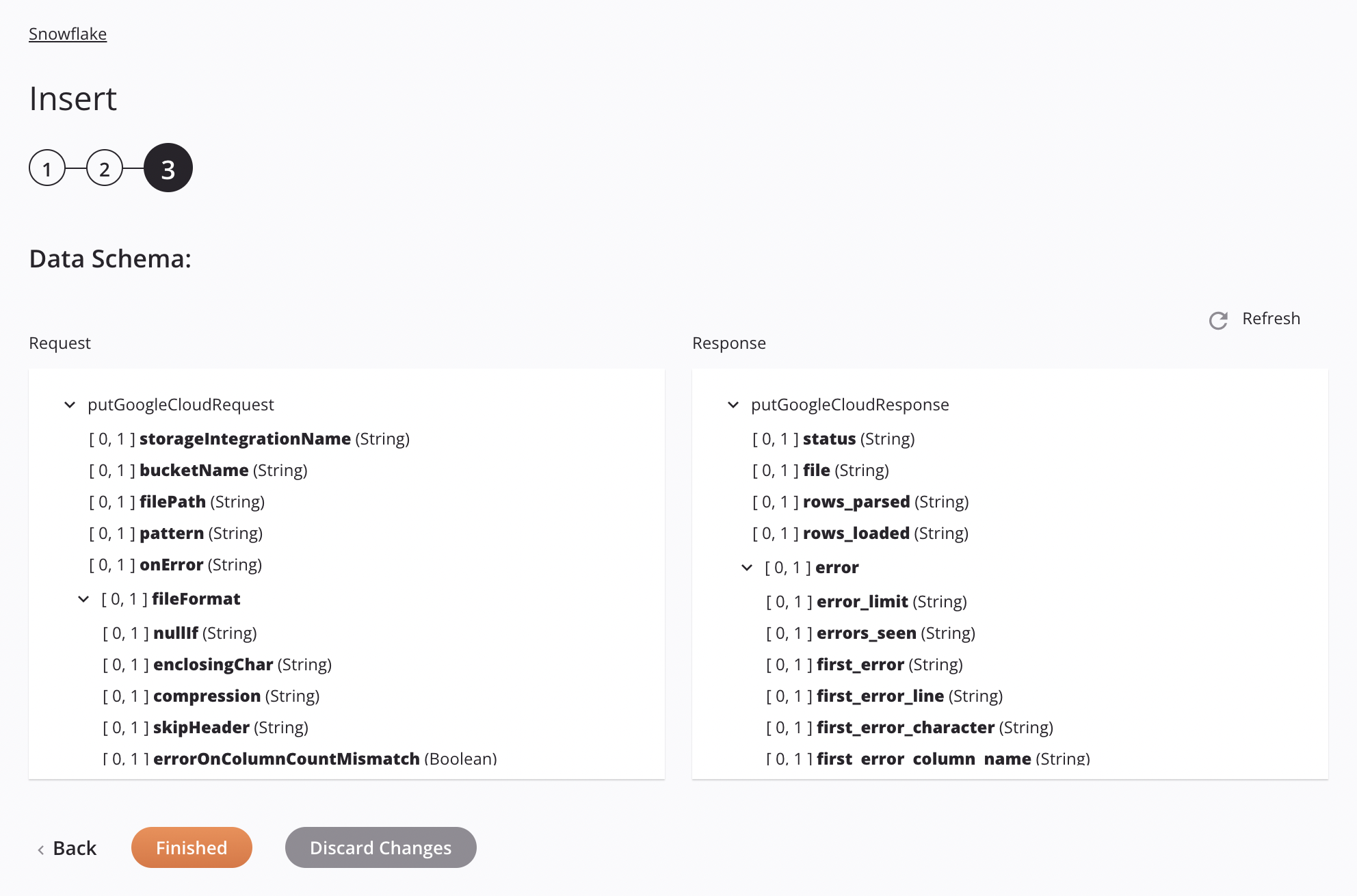
Si el enfoque es Archivo de etapa de Google Cloud Storage, las especificaciones para preparar e insertar un archivo CSV se mostrarán en el esquema de datos para que se puedan asignar en una transformación. El patrón utilizado es hacer coincidir un solo archivo. Si el patrón coincide con más de un archivo, la actividad generará un error con un mensaje descriptivo.
-
Pedido
Solicitar campo/nodo de esquema Notas storageintegrationNameNombre de la integración de almacenamiento de Snowflake que se utilizará para la autenticación de la integración de almacenamiento de Snowflake. bucketNameNombre de depósito válido para un depósito existente en Google Cloud Storage. filePathUbicación del archivo de etapa en el depósito de Google Cloud Storage. patternPatrón de expresión regular utilizado para encontrar el archivo en el escenario; si compressDataes verdad,[.]gzse adjunta al patrón.onErrorEn caso de error opción seleccionada. fileFormatNodo que representa el formato del archivo. nullIfUna cadena para convertir a SQL NULL; de forma predeterminada, es una cadena vacía. Ver elNULL_IFopción del SnowflakeCOPY INTO<location>documentación.enclosingCharCarácter utilizado para encerrar campos de datos; ver el FIELD_OPTIONALLY_ENCLOSED_BYopción del SnowflakeCOPY INTO<location>documentación.Nota
El
enclosingCharpuede ser una comilla simple'o carácter de comilla doble". Para utilizar el carácter de comilla simple, utilice el carácter octal'o el maleficio0x27representaciones o utilizar un escape de comilla simple doble''. Cuando un campo contiene este carácter, escápelo usando el mismo carácter.compressionEl algoritmo de compresión utilizado para los archivos de datos. GZIPoNONEson compatibles. Consulte la Opción de compresión del SnowflakeCOPY INTO<location>documentación.skipHeaderNúmero de líneas al inicio del archivo fuente que se van a omitir. errorOnColumnCountMismatchIndicador booleano para informar un error si los recuentos de origen y destino del esquema de respuesta no coinciden. fieldDelimiterEl carácter delimitador utilizado para separar campos de datos; ver el FIELD_DELIMITERopción del SnowflakeCOPY INTO<table>documentación.recordDelimiterEl carácter delimitador utilizado para separar grupos de campos; ver el RECORD_DELIMITERopción del SnowflakeCOPY INTO<table>documentación. -
Respuesta
Campo/nodo del esquema de respuesta Notas statusEstado devuelto. fileNombre del archivo CSV preparado procesado al insertar datos en la tabla Snowflake. rows_parsedNúmero de filas analizadas del archivo CSV. rows_loadedNúmero de filas cargadas desde el archivo CSV en la tabla Snowflake sin errores. errorNodo que representa los mensajes de error. error_limitNúmero de errores que hacen que el archivo se omita según lo establecido en Skip_File_\<num>. errors_seenRecuento de errores vistos. first_errorEl primer error en el archivo fuente. first_error_lineEl número de primera línea del primer error. first_error_characterEl primer carácter del primer error. first_error_column_nameEl nombre de la columna de la primera ubicación del error.
enfoque de Archivo de Etapa Interna¶
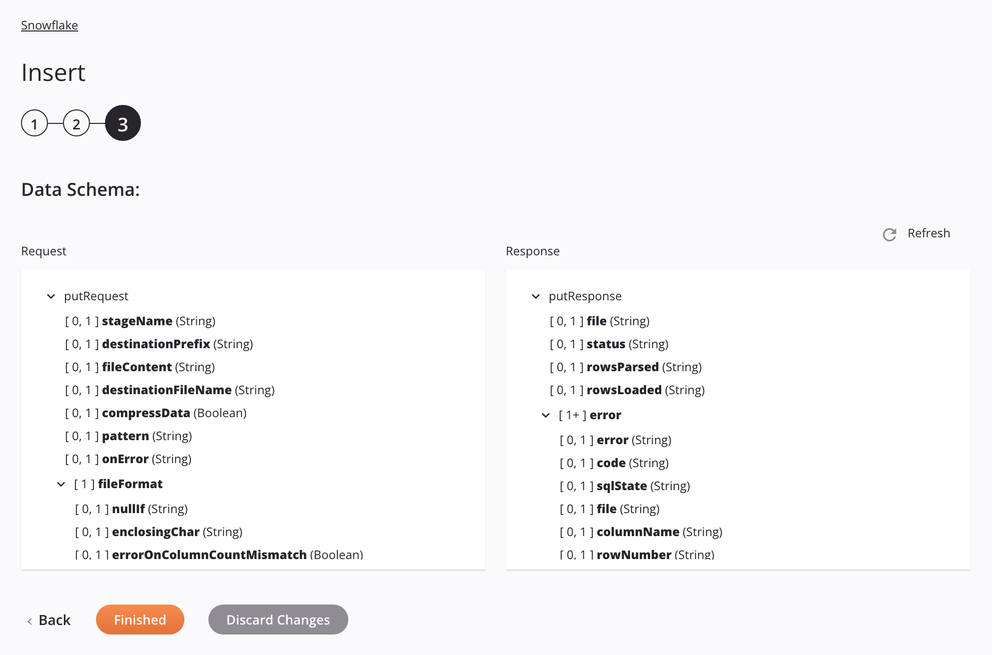
Si el enfoque es Archivo de etapa interna, las especificaciones para preparar e insertar un archivo CSV se mostrarán en el esquema de datos para que se puedan asignar en una transformación. El patrón utilizado es hacer coincidir un solo archivo. Si el patrón coincide con más de un archivo, la actividad generará un error con un mensaje descriptivo.
-
Pedido
Solicitar campo/nodo de esquema Notas stageNameEtapa, nombre de tabla o ruta interna de Snowflake. destinationPrefixRuta o prefijo bajo el cual se cargarán los datos en el escenario Snowflake. fileContentContenido del archivo de datos, en formato CSV, que se preparará para cargarlo en la tabla Snowflake. destinationFileNameNombre del archivo de destino que se utilizará en el escenario Snowflake. compressDataIndicador booleano para saber si se deben comprimir los datos antes de cargarlos en la etapa interna de Snowflake. patternPatrón de expresión regular utilizado para encontrar el archivo en el escenario; si compressDataes verdad,[.]gzse adjunta al patrón.onErrorEn caso de error opción seleccionada. fileFormatNodo que representa el formato del archivo. nullIfUna cadena para convertir a SQL NULL; de forma predeterminada, es una cadena vacía. Ver elNULL_IFopción del SnowflakeCOPY INTO<location>documentación.enclosingCharCarácter utilizado para encerrar campos de datos; ver el FIELD_OPTIONALLY_ENCLOSED_BYopción del SnowflakeCOPY INTO<location>documentación.Nota
El
enclosingCharpuede ser una comilla simple'o carácter de comilla doble". Para utilizar el carácter de comilla simple, utilice el carácter octal'o el maleficio0x27representaciones o utilizar un escape de comilla simple doble''. Cuando un campo contiene este carácter, escápelo usando el mismo carácter.errorOnColumnCountMismatchIndicador booleano para informar un error si los recuentos de origen y destino del esquema de respuesta no coinciden. fieldDelimiterEl carácter delimitador utilizado para separar campos de datos; ver el FIELD_DELIMITERopción del SnowflakeCOPY INTO<table>documentación.recordDelimiterEl carácter delimitador utilizado para separar grupos de campos; ver el RECORD_DELIMITERopción del SnowflakeCOPY INTO<table>documentación. -
Respuesta
Campo/nodo del esquema de respuesta Notas fileNombre del archivo CSV preparado procesado al colocar datos en la tabla Snowflake. statusEstado devuelto. rowsParsedNúmero de filas analizadas del archivo CSV. rowsLoadedNúmero de filas cargadas desde el archivo CSV en la tabla Snowflake sin errores. errorNodo que representa los mensajes de error. errorEl mensaje de error. codeEl código de error devuelto. sqlStateEl código de error numérico del estado SQL devuelto por la llamada a la base de datos. fileNodo que representa los mensajes de error. columnNameNombre y orden de la columna que contenía el error. rowNumberEl número de la fila en el archivo fuente donde se encontró el error. rowStartLineEl número de la primera línea de la fila donde se encontró el error.
enfoque de Archivo de Etapa de Microsoft Azure¶
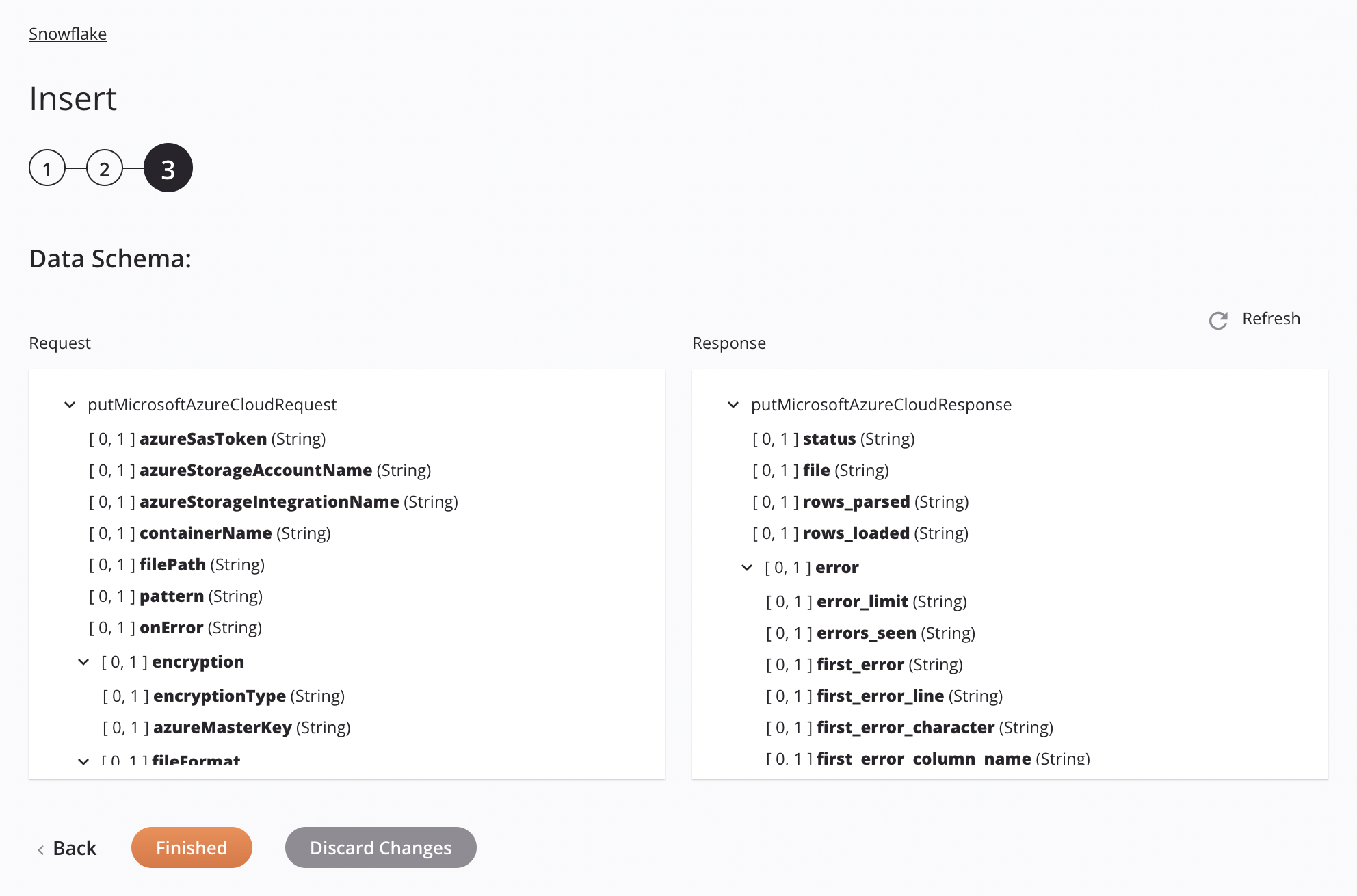
Si el enfoque es Microsoft Azure Stage File, las especificaciones para preparar e insertar un archivo CSV se mostrarán en el esquema de datos para que se puedan asignar en una transformación. El patrón utilizado es hacer coincidir un solo archivo. Si el patrón coincide con más de un archivo, la actividad generará un error con un mensaje descriptivo.
-
Pedido
Solicitar campo/nodo de esquema Notas azureSasTokenToken de firma de acceso compartido (SAS) de Microsoft Azure. azureStorageAccountNameNombre de la cuenta de almacenamiento de Microsoft Azure. azureStorageintegrationNameNombre de la integración de almacenamiento de Snowflake que se utilizará para la autenticación de la integración de almacenamiento de Snowflake. containerNameNombre de contenedor válido para un contenedor de almacenamiento existente en Microsoft Azure. filePathUbicación del archivo provisional en el contenedor de almacenamiento de Microsoft Azure. patternPatrón de expresión regular utilizado para encontrar el archivo en el escenario; si compressionesGZIP,[.]gzse adjunta al patrón.onErrorEn caso de error opción seleccionada. encryptionNodo que representa el cifrado. encryptionTypeTipo de cifrado de Microsoft Azure (solo cifrado del lado del cliente). azureMasterKeyClave maestra de Microsoft Azure. fileFormatNodo que representa el formato del archivo. nullIfUna cadena para convertir a SQL NULL; de forma predeterminada, es una cadena vacía. Ver elNULL_IFopción del SnowflakeCOPY INTO<location>documentación.enclosingCharCarácter utilizado para encerrar campos de datos; ver el FIELD_OPTIONALLY_ENCLOSED_BYopción del SnowflakeCOPY INTO<location>documentación.Nota
El
enclosingCharpuede ser una comilla simple'o carácter de comilla doble". Para utilizar el carácter de comilla simple, utilice el carácter octal'o el maleficio0x27representaciones o utilizar un escape de comilla simple doble''. Cuando un campo contiene este carácter, escápelo usando el mismo carácter.compressionEl algoritmo de compresión utilizado para los archivos de datos. GZIPoNONEson compatibles. Consulte la Opción de compresión del SnowflakeCOPY INTO<location>documentación.skipHeaderNúmero de líneas al inicio del archivo fuente que se van a omitir. errorOnColumnCountMismatchIndicador booleano para informar un error si los recuentos de origen y destino del esquema de respuesta no coinciden. fieldDelimiterEl carácter delimitador utilizado para separar campos de datos; ver el FIELD_DELIMITERopción del SnowflakeCOPY INTO<table>documentación.recordDelimiterEl carácter delimitador utilizado para separar grupos de campos; ver el RECORD_DELIMITERopción del SnowflakeCOPY INTO<table>documentación. -
Respuesta
Campo/nodo del esquema de respuesta Notas statusEstado devuelto. fileNombre del archivo CSV preparado procesado al insertar datos en la tabla Snowflake. rows_parsedNúmero de filas analizadas del archivo CSV. rows_loadedNúmero de filas cargadas desde el archivo CSV en la tabla Snowflake sin errores. errorNodo que representa los mensajes de error. error_limitNúmero de errores que hacen que el archivo se omita según lo establecido en Skip_File_\<num>. errors_seenRecuento de errores vistos. first_errorEl primer error en el archivo fuente. first_error_lineEl número de primera línea del primer error. first_error_characterEl primer carácter del primer error. first_error_column_nameEl nombre de la columna de la primera ubicación del error.
Próximos Pasos¶
Después de configurar una actividad Insertar de Snowflake, complete la configuración de la operación agregando y configurando otras actividades, transformaciones o secuencias de comandos como pasos de la operación. También puede configurar los ajustes de operación, que incluyen la capacidad de encadenar operaciones que se encuentran en el mismo flujos de trabajo o en diferentes.
Se puede acceder a las acciones del menú para una actividad desde el panel del proyecto y el tela de diseño. Para obtener más información, consulte Menú de acciones de actividad en Conceptos básicos del conector.
Las actividades de Snowflake Insertar se pueden utilizar como objetivo con estos patrones de operación:
- Patrón de transformación
- Patrón de dos transformaciones (como primer o segundo objetivo)
Para usar la actividad con funciones de secuencias de comandos, escriba los datos en una ubicación temporal y luego use esa ubicación temporal en la función de secuencias de comandos.
Cuando esté listo, desplegar y ejecutar la operación y validar el comportamiento comprobando los registros de operación.