Opciones de Operación¶
Introducción¶
Cada operación se puede configurar con opciones como cuándo expirará la operación, qué registrar y el plazo para el registro de depurar de la operación. La presencia de ciertos componentes como pasos de operación hace visibles opciones adicionales sobre si se ejecuta una operación posterior y si se utiliza fragmentación de datos.
Acceder a las Opciones de Operación¶
Se puede acceder a la opción Configuración para operaciones desde estas ubicaciones:
- La pestaña Flujos de Trabajo del panel del proyecto (consulte Menú de acciones de componentes en Pestaña Flujos de Trabajo del panel de proyecto).
- La pestaña Componentes del panel del proyecto (consulte Menú de acciones de componentes en Pestaña Componentes del panel de proyecto).
- El tela de diseño (consulte Menú de acciones del componente en Tela de Diseño).
Una vez que la pantalla de configuración de operación esté abierta, seleccione la pestaña Opciones:

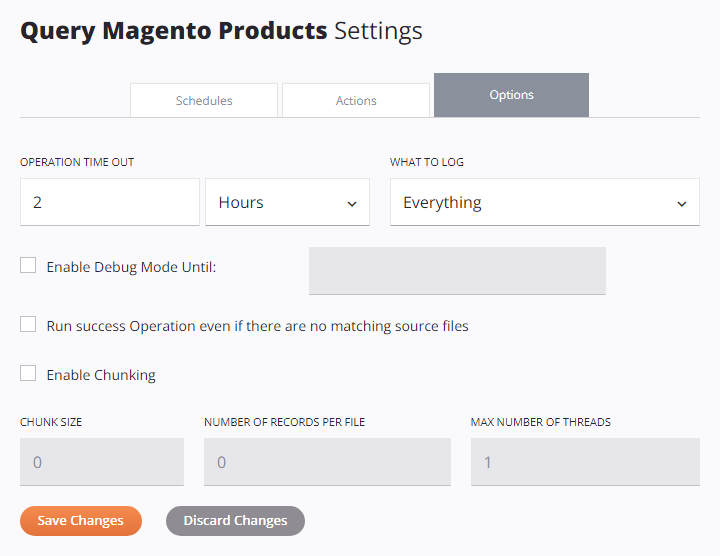
Configurar Opciones de Operación¶
Cada opción disponible dentro de la pestaña Opciones de la configuración de operación se describe a continuación.
-
Tiempo de espera de operación: Especifique la cantidad máxima de tiempo que se ejecutará la operación antes de cancelarse. En el primer campo, ingrese un número y en el segundo campo use el menú desplegable para seleccionar las unidades en Segundos, Minutos u Horas. El valor predeterminado es 2 horas.
Las razones comunes para ajustar el valor de Tiempo de espera de operación incluyen las siguientes:
-
Aumente el valor del tiempo de espera si la operación tiene conjuntos de datos grandes que tardan mucho en ejecutarse.
-
Disminuir el valor del tiempo de espera si la operación es urgente; es decir, no desea que la operación tenga éxito si no puede completarse dentro de un período de tiempo determinado.
Nota
Operaciones activadas por APIs de API Manager no están sujetos a la configuración de Tiempo de espera de operación cuando se utilizan Agentes en Nube. En Agentes Privados, utilice el
EnableAPITimeoutconfiguración en el archivo de configuración del Agente Privado para que la configuración Tiempo de espera de operación se aplique a las operaciones activadas por las APIs. -
-
Qué registrar: Utilice el menú desplegable para seleccionar qué registrar en los registros de operación, uno de Todo (predeterminado) o Sólo errores:
-
Todo: Operaciones con cualquier estado de operación están registrados.
-
Solo errores: Solo se registran las operaciones con un estado de tipo de error (como Error, Error de SOAP o Éxito con error secundario). Las operaciones secundarias exitosas no se registran. Las operaciones principales (nivel raíz) siempre se registran, ya que requieren registro para funcionar correctamente.
Una razón común para limitar los registros a Solo errores es si tiene problemas de latencia de operación. De esta manera, si no planeaba utilizar otros mensajes que no sean de error normalmente filtrados en los registros de operación, puede evitar que se generen en primer lugar.
-
-
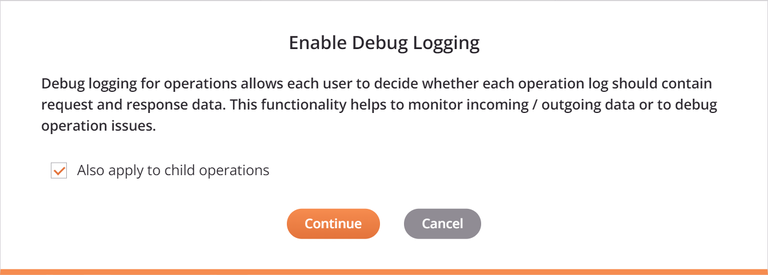
Habilitar modo de depuración hasta: Seleccione para habilitar el registro de depurar de operación y especifique una fecha en la que el modo de depurar se deshabilitará automáticamente, limitado a dos semanas a partir de la fecha actual. El registro de depurar de operaciones se desactivará al comienzo de esa fecha (es decir, a las 12:00 a. m.) utilizando la huso horario del agente.
Al seleccionar Habilitar modo de depuración hasta, un cuadro de diálogo proporciona una casilla de verificación Aplicar también a operaciones secundarias que pondrá en cascada la configuración a cualquier operación secundaria. Esta opción también se proporciona al borrar la configuración del modo de depurar de operación.
Cuando el registro de depurar de operación está habilitado, se generan estos tipos de registros, según el tipo de agente:
-
Agente Privado: Archivos de registro de depuración para una operación. Esta opción se utiliza principalmente para depurar problemas durante las pruebas y no debe activarse en producción, ya que puede crear archivos muy grandes. El registro de depuración también se puede habilitar para todo el proyecto desde el propio Agente Privado (consulte Registro de depuración de operaciones). Se puede acceder a los archivos de registro de depurar directamente en los Agentes Privados y se pueden descargar a través de la Management Console Agentes > Agentes y Operaciones en tiempo de ejecución páginas.
-
Agente Privado o Agente en Nube: Se pueden generar dos tipos de registros:
-
Datos de entrada y salida de componentes: Datos escritos en un Cloud Studio registro de operación para una operación que se ejecuta en la versión del agente 10.48 o posterior. Harmony conserva los datos durante 30 días.
-
Registros de operación de API: Registros de operación para operaciones de API exitosas (configuradas para APIs personalizadas o Servicios OData). De forma predeterminada, solo las operaciones de API con errores se registran en los registros de operación.
-
Para obtener detalles adicionales, consulte Registro de depuración de operaciones para Agentes en Nube o Registro de depuración de operación para Agentes Privados.
Precaución
La generación de datos de entrada y salida de componentes no se ve afectada por la configuración del Grupo de Agentes Habilitar registro en la nube (consulte Agentes > Grupos de Agente). Los datos de entrada y salida de los componentes se registrarán en la nube de Harmony incluso si el registro en la nube está deshabilitado.
Para deshabilitar la generación de datos de entrada y salida de componentes en un Grupo de Agentes Privados, en el archivo de configuración del Agente Privado bajo la
[VerboseLogging]sección, conjuntoverbose.logging.enable=false.Advertencia
Cuando se generan datos de entrada y salida de componentes, todos los datos de solicitud y respuesta para esa operación se registran en la nube de Harmony y permanecen allí durante 30 días. Tenga en cuenta que la información de identificación personal (PII) y los datos confidenciales, como las credenciales proporcionadas en una carga útil de solicitud, serán visibles en texto claro en los datos de entrada y salida dentro de los registros de la nube de Harmony.
-
-
Ejecutar operación exitosa incluso si no hay archivos fuente coincidentes: Seleccione para forzar que una operación arriba en la cadena sea exitosa. Esto le permite efectivamente iniciar una operación con una condición En caso de éxito (configurada con una acción de operación) incluso si el disparador falló.
Esta opción es aplicable solo si la operación contiene una API, Recurso compartido de archivos, FTP, HTTP, Almacenamiento local, SOAP, Almacenamiento temporal, o Actividad variable que se utiliza como fuente en la operación y se aplica solo cuando la operación tiene configurada una condición En caso de éxito. De forma predeterminada, cualquier operación En caso de éxito se ejecuta solo si tiene un archivo fuente coincidente para procesar. Esta opción puede ser útil para configurar partes posteriores de un proyecto sin requerir el éxito de una operación dependiente.
Nota
El ambiente
AlwaysRunSuccessOperationen el[OperationEngine]sección del archivo de configuración del Agente Privado anula la configuración Ejecutar operación exitosa incluso si no hay archivos fuente coincidentes. -
Habilitar fragmentación: Seleccione para habilitar la fragmentación de datos usando los parámetros especificados:
-
Tamaño del fragmento: Ingrese una cantidad de registros de origen (nodos) para procesar para cada subproceso. Cuando la fragmentación de datos está habilitada para operaciones que no contienen ninguna actividad basada en Salesforce, el tamaño de fragmentación predeterminado es
1. Cuando se agrega una actividad basada en Salesforce a una operación que no tiene la fragmentación de datos habilitada, la fragmentación de datos se habilita automáticamente con un tamaño de fragmento predeterminado de200. Si utiliza una actividad masiva basada en Salesforce, debe cambiar este valor predeterminado a un número mucho mayor, como 10 000. -
Número de registros por archivo: Ingrese el número solicitado de registros que se colocarán en el archivo de destino. El valor predeterminado es
0, lo que significa que no hay límite en la cantidad de registros por archivo. -
Número máximo de subprocesos: Ingrese el número de subprocesos simultáneos para procesar. Cuando la fragmentación de datos está habilitada para operaciones que no contienen ninguna actividad basada en Salesforce, el número predeterminado de subprocesos es
1. Cuando se agrega una actividad basada en Salesforce a una operación que no tiene la fragmentación de datos habilitada, la fragmentación de datos se habilita automáticamente con una cantidad predeterminada de subprocesos de2.
Esta opción está presente solo si la operación contiene una transformación o una base de datos, NetSuite, Salesforce, Salesforce Service Cloud, ServiceMax, o actividad SOAP, y se utiliza para procesar datos en el sistema de destino en fragmentos. Esto permite un procesamiento más rápido de grandes conjuntos de datos y también se utiliza para abordar los límites de registro impuestos por varios sistemas basados en servicios web al realizar una solicitud.
Tenga en cuenta que si está utilizando un extremo basado en Salesforce ( Salesforce, Salesforce Service Cloud o ServiceMax ):
-
Si se agrega una actividad basada en Salesforce a una operación que no tiene la fragmentación de datos habilitada, la fragmentación de datos se habilita con la configuración predeterminada específicamente para las actividades basadas en Salesforce como se describe anteriormente.
-
Si se agrega una actividad basada en Salesforce a una operación que ya tiene la fragmentación de datos habilitada, la configuración de la fragmentación de datos no se cambia. Del mismo modo, si una actividad basada en Salesforce se elimina de una operación, la configuración de fragmentación de datos no se cambia.
En la siguiente sección, fragmentación de datos.
-
-
Guardar cambios: Haga clic para guardar y cerrar la configuración de operación.
-
Descartar cambios: Después de realizar cambios en la configuración de operación, haga clic para cerrar la configuración sin guardar.
Fragmentación¶
La fragmentación se utiliza para dividir los datos de origen en varios fragmentos según el tamaño del fragmento configurado. El tamaño del fragmento es el número de registros de origen (nodos) para cada fragmento. Luego, la transformación se realiza en cada fragmento por separado, y cada fragmento de origen produce un fragmento de destino. Los fragmentos de objetivo resultantes se combinan para producir el objetivo final.
La fragmentación sólo se puede utilizar si los registros son independientes y provienen de una fuente que no es LDAP. Recomendamos utilizar un tamaño de fragmento lo más grande posible, asegurándose de que los datos de un fragmento quepan en la memoria disponible. Para conocer métodos adicionales para limitar la cantidad de memoria que utiliza una transformación, consulte Procesamiento de Transformación.
Advertencia
El uso de fragmentación de datos afecta el comportamiento de las variables globales y del proyecto. Consulte Usar variables con fragmentación abajo.
Limitaciones de la API¶
Muchas APIs de servicios web (SOAP/REST) tienen limitaciones de tamaño. Por ejemplo, un upsert basado en Salesforce acepta solo 200 registros por cada llamada. Con suficiente memoria, podría configurar una operación para utilizar un tamaño de fragmento de 200. La fuente se dividiría en fragmentos de 200 registros cada uno, y cada transformación llamaría al servicio web una vez con un fragmento de 200 registros. Esto se repetirá hasta que se hayan procesado todos los registros. Luego se combinarían los archivos de destino resultantes. (Tenga en cuenta que también puede utilizar actividades masivas basadas en Salesforce para evitar el uso de fragmentación de datos).
Procesamiento en Paralelo¶
Si tiene una fuente grande y una computadora con varias CPU, se puede utilizar la fragmentación de datos para dividir la fuente para el procesamiento en paralelo. Dado que cada fragmento se procesa de forma aislada, se pueden procesar varios fragmentos en paralelo. Esto se aplica sólo si los registros de origen son independientes entre sí en el nivel del nodo del fragmento. Los servicios web se pueden llamar en paralelo mediante fragmentación de datos, lo que mejora el rendimiento.
Cuando utilice fragmentación de datos en una operación donde el destino es una base de datos, tenga en cuenta que los datos de destino se escriben primero en numerosos archivos temporales (uno para cada fragmento). Luego, estos archivos se combinan en un archivo de destino, que se envía a la base de datos para su inserción/actualización. Si configura la variable Jitterbit jitterbit.target.db.commit_chunks a 1 o true cuando la fragmentación de datos está habilitada, cada fragmento se envía a la base de datos a medida que está disponible. Esto puede mejorar significativamente el rendimiento ya que la inserción/actualización de la base de datos se realiza en paralelo.
Utilice Variables con Fragmentación¶
Como la fragmentación de datos puede invocar subprocesos múltiples, su uso puede afectar el comportamiento de las variables que no se comparten entre los subprocesos.
Global y variables del proyecto están segregados entre las instancias de fragmentación de datos y, aunque los datos se combinan, los cambios en estas variables no. Sólo los cambios realizados en el hilo inicial se conservan al final de la transformación.
Por ejemplo, si una operación (con fragmentación de datos y múltiples subprocesos) tiene una transformación que cambia una variable global, el valor de la variable global después de que finaliza la operación es el del primer subproceso. Cualquier cambio en la variable en otros subprocesos es independiente y se descarta cuando se completa la operación.
Estas variables globales se pasan a los otros subprocesos por valor en lugar de por referencia, lo que garantiza que cualquier cambio en las variables no se refleje en otros subprocesos u operaciones. Esto es similar al RunOperation funcionar cuando está en modo asíncrono.