Crear Salida de Uno o Varios Registros¶
Caso de Uso¶
Un escenario frecuente es cuando el origen contiene varios registros y se habilita una orquestación eficiente si los archivos de destino se escriben individualmente de modo que el nombre del archivo contenga un valor clave derivado de un valor de campo en el registro.
El comportamiento predeterminado de Jitterbit es crear un único archivo que contenga varios registros cuando la fuente contiene varios registros. Esta página también demuestra (en Ejemplo 2) cómo lograr la salida de múltiples registros usando el prefijo de variable global reservado SOURCE_CHUNK.
Nota
Este patrón de diseño utiliza Design Studio como ejemplo; puedes aplicar los mismos conceptos en Cloud Studio siguiendo pasos similares.
Ejemplo 1: Varios Registros en un Único Archivo de Salida¶
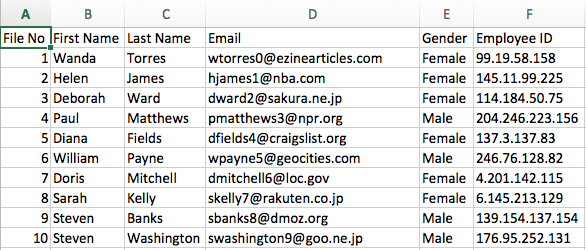
Para estos ejemplos, supongamos que el archivo fuente contiene una lista de empleados donde un campo contiene un ID de empleado.
Ejemplo de datos de origen:
Cree una Operación básica donde aceptemos todos los valores predeterminados:
Defina la Fuente:
Mapeo simple donde la transformación muestra los registros de origen y destino:
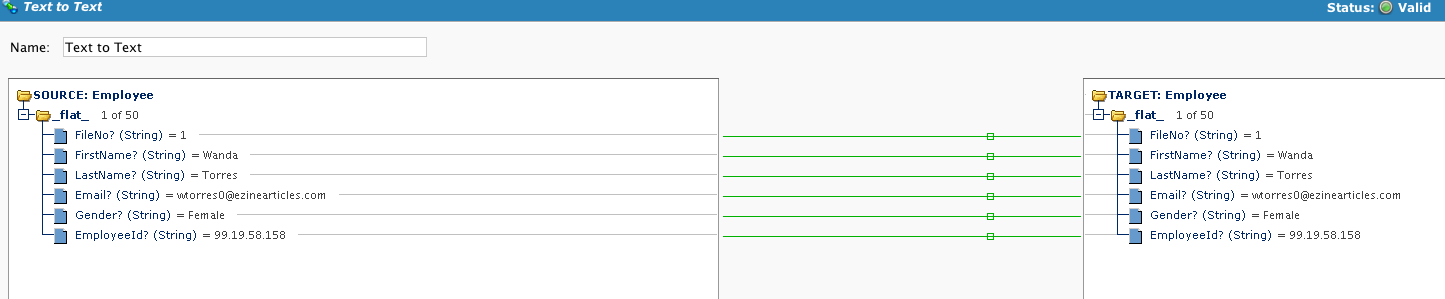
Defina el Objetivo:
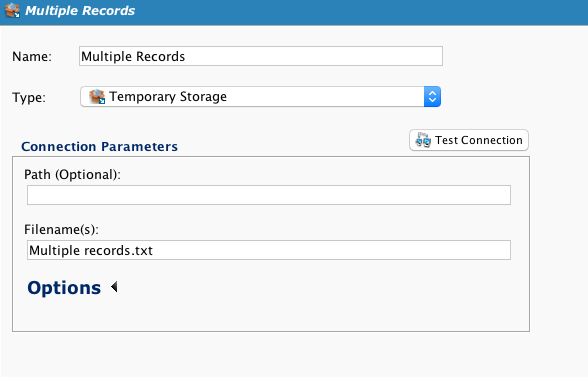
El archivo de destino (Múltiples registros.txt) será un único archivo que contiene varios registros:

Ejemplo 2: Varios Archivos de Salida Que Contienen un Único Registro¶
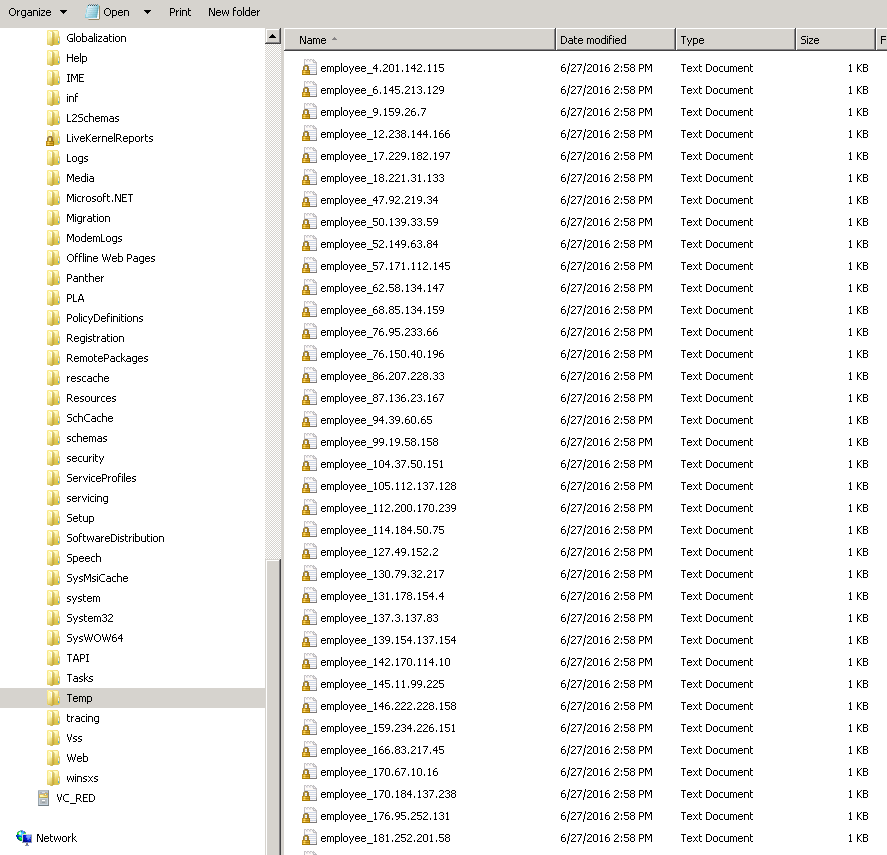
El extremo de destino requiere un formato de archivo donde se requiere la identificación del empleado en el nombre del archivo. Esto significa crear 50 registros con cada registro en un nombre de archivo con el patrón employee_\<employee id>.txt.
Antes de la introducción de SCOPE_CHUNK, la generación de múltiples archivos que contenían un solo registro requeriría un conjunto adicional de operaciones para leer los registros y escribirlos individualmente.
Con SCOPE_CHUNK, una sola operación puede generar múltiples registros y proporcionar control sobre el nombre del archivo basado en datos. Este ejemplo procesará un archivo para un conjunto diferente de 50 empleados que contiene los mismos campos de datos que el archivo de datos de origen que se utiliza en el Ejemplo 1. La operación en este ejemplo crea 50 registros, cada uno de los cuales termina en un nombre de archivo de empleado_ \<identificación del empleado>.txt.
Precaución
El SCOPE_CHUNK La sintaxis de prefijo no se admite en operaciones con una transformación que utiliza mapeo condicional.
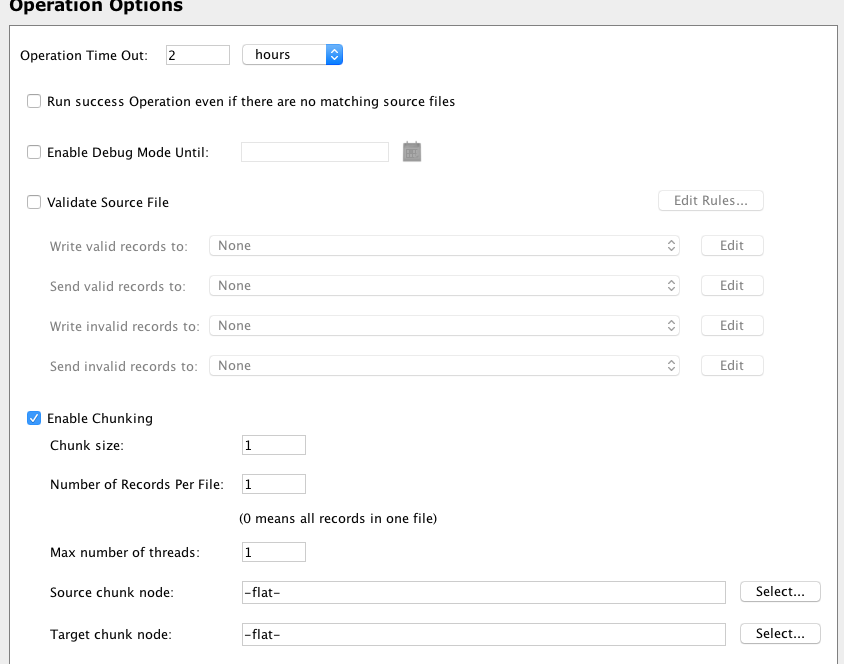
Establezca Habilitar fragmentación en Opciones de operación. Establezca Tamaño de fragmento, Número de registros por archivo y Número máximo de subprocesos en 1. Esto obligará a la transformación a procesar un registro a la vez:
El mapeo es similar, con la adición de aplicar un secuencia de comandos al último campo. Tenga en cuenta que cuando se prueba la operación, solo se procesa 1 registro.
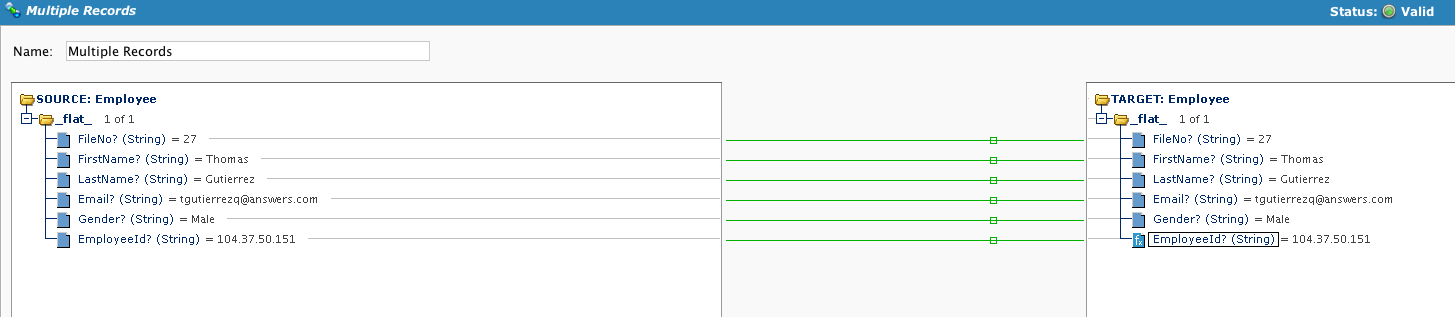
Cree un Secuencia de Comandos en el último campo. Al crear una variable global precedida por SCOPE_CHUNK y completar el nombre del archivo deseado para incluir un valor de registro, podemos pasar la variable global al destino.

Ingrese la variable global en el campo Nombre(s) de archivo del destino:
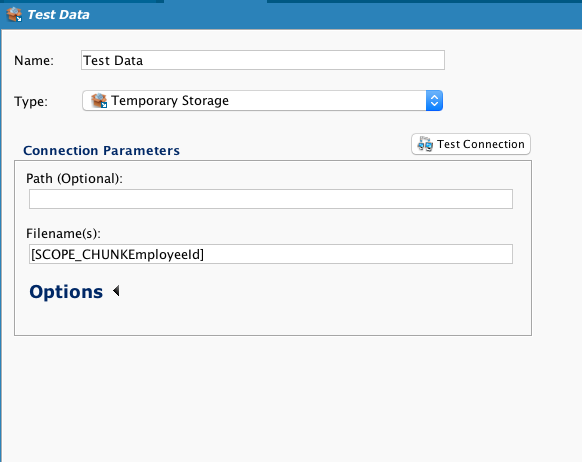
Cuando se ejecuta, la operación ahora crea un archivo individual para cada empleado, que contiene solo ese registro de empleado y tiene un nombre individual para incluir el ID del empleado. En la captura de pantalla que se muestra, los sufijos del nombre de archivo (.txt) están escondidos: