Read a zipped Base64-encoded file in Jitterbit Integration Studio
Introduction
When a request or response contains a binary file (like a PDF), it usually is encoded into Base64. The reason is simple: JSON and XML are text-based formats and cannot use anything binary.
Encode a string
Encoding a string is accomplished using Base64Encode in combination with Jitterbit's HexToBinary and StringToHex functions:
binary = Base64Encode(HexToBinary(StringToHex("Hello world!"));
Decode a binary file
Decoding a binary file is even simpler with Base64Decode. However, dealing with a Base64-encoded zipped file takes extra work.
Let's say you keep zipped files in Amazon S3 and need them to be read in an Integration Studio project. Since Amazon S3 stores all its data in Base64, the standard approach is to simply use Base64Decode and read the result. However, if the source is zipped, we have to follow a different process. First, the binary file needs to be stored on disk (not in a Variable endpoint). This can be done by writing to Temporary Storage or a local File Share.

In the above operation, the request transformation provides input to the Amazon S3 activity:
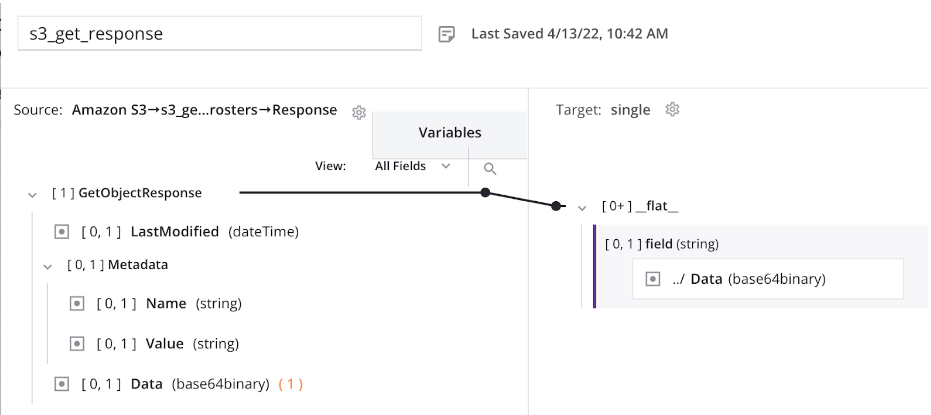
Next, the content is read and decoded:
//decode file
undecoded = Base64Decode(ReadFile("<TAG>activity:tempstorage/s3_get_response/tempstorage_read/Read</TAG>"));
This is followed by writing the decoded file to a different Temporary Storage endpoint. Note the use of FlushFile:
//write to temp
WriteFile("<TAG>activity:tempstorage/s3_get_response/tempstorage_write/Write</TAG>",undecoded,"undecoded.zip");
FlushFile("<TAG>activity:tempstorage/s3_get_response/tempstorage_write/Write</TAG>","undecoded.zip");
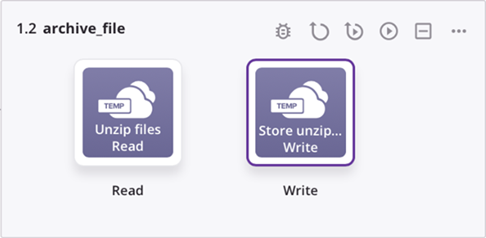
Finally, an operation using the Archive pattern reads the file and writes to the target:
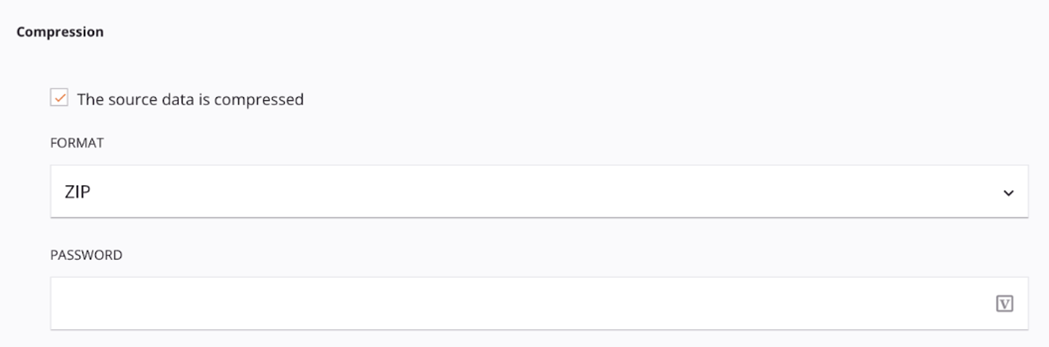
The Temporary Storage Read activity is configured in its options to treat this as a zipped file:
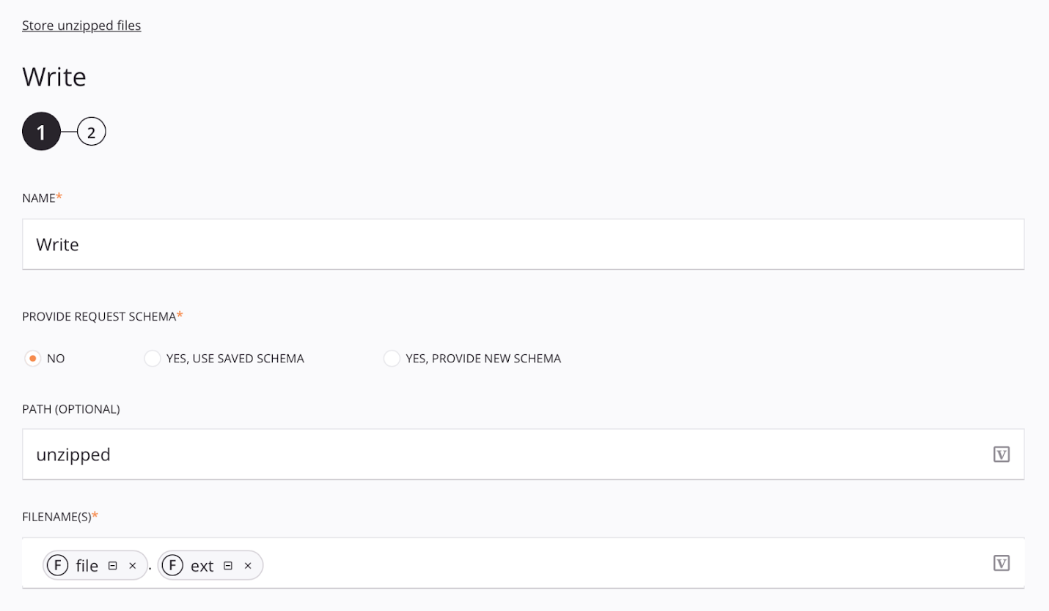
In order for the original zipped file name to be stored by the Temporary Storage Write activity, use the [file].[ext] filename keywords in the Filenames field: