Divida um Arquivo em Registros Individuais Usando SCOPE_CHUNK¶
Introdução¶
Este padrão de design pode ser usado para dividir os dados em um arquivo com vários registros em vários arquivos, cada um contendo um único registro, usando o SCOPE_CHUNK sintaxe de prefixo do Set função.
Dica
Esse padrão é recomendado quando os dados de origem são simples (não hierárquicos) e a operação não contém uma transformação que usa mapeamento condicional. Para dados de origem complexos (hierárquicos), consulte Dividir um arquivo em registros individuais usando SourceInstanceCount.
Caso de Uso¶
Neste cenário, os dados de origem contêm vários registros e o processo de negócios ou terminal de endpoint exige que os registros sejam processados individualmente.
Padrão de Design¶
Esse padrão de design serve para ler o arquivo usando uma operação em que a transformação usa o mesmo esquema de origem e destino. Este padrão tem estas características principais:
- No primeiro campo da transformação que processa os dados, o
Seta função é usada para definir uma variável que começa comSCOPE_CHUNKseguido de texto adicional para construir o nome da variável. O primeiro argumento cria o nome do arquivo de saída, normalmente usando um identificador de registro dos dados de origem. Os nomes dos arquivos devem ser exclusivos para evitar serem substituídos, portanto, um contador de registros ou um GUID pode ser usado como parte do nome do arquivo. - Um destino de armazenamento de arquivos como Armazenamento temporário ou Armazenamento local deve ser usado. (Usando uma Variável não é compatível.) É recomendável definir um caminho. O nome do arquivo deve ser configurado com o nome da variável global usada no
Setfunção. - As opções de operação deve ser configurado com Enable Chunking selecionado, com um Chunk Size de
1, Número de registros por arquivo de1e Número máximo de threads de1. - Durante o tempo de execução, cada registro será lido e atribuído a um nome de arquivo exclusivo e gravado individualmente no destino.
Depois de usar esse padrão, normalmente a próxima etapa é usar o FileList função para obter a matriz de nomes de arquivos no diretório (configure a atividade do diretório de arquivos Read com o * curinga), em seguida, percorre a matriz e lê cada arquivo na origem para a próxima operação.
Exemplos¶
Exemplos usando o padrão de design descrito acima são fornecidos para dois tipos diferentes de dados de origem: um arquivo CSV simples e um arquivo JSON hierárquico.
CSV Simples¶
Este exemplo de cadeia de operação aplica o padrão de design descrito acima para dividir dados CSV simples em um arquivo para cada registro. Cada número corresponde a uma descrição da etapa de operação abaixo. Para obter detalhes adicionais, consulte as capturas de tela do JSON hierárquico exemplo.
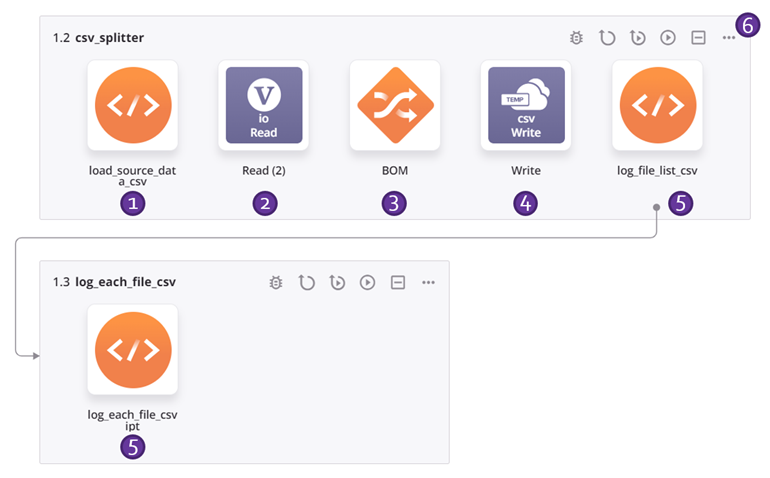
-
O script atribui os dados de origem a uma variável global chamada
io(entrada/saída). (Um script é usado para fins de demonstração; os dados de origem também podem vir de um endpoint configurado.)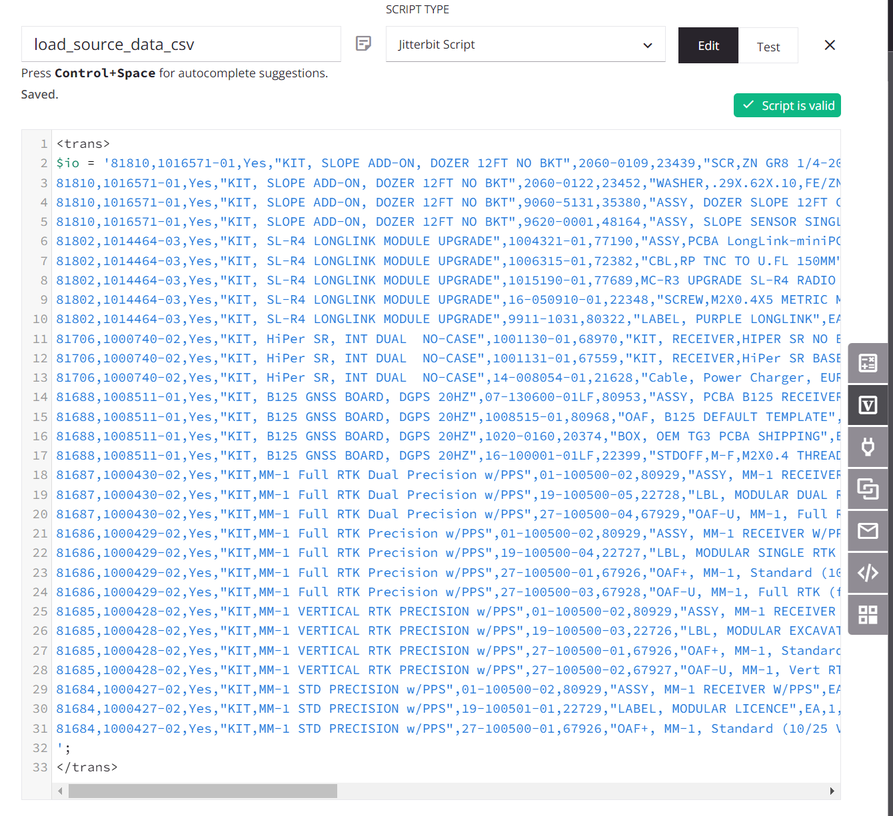
-
O
iovariável global é usada para configurar uma Variável endpoint e uma atividade Variable Read associada é usada pela operação como a origem da transformação. -
Dentro da transformação, a origem e os destinos usam o mesmo esquema e todos os campos são mapeados. O primeiro campo de dados no script de mapeamento da transformação está configurado para usar
SCOPE_CHUNK. OSeta função é usada para construir uma variável começando com a fraseSCOPE_CHUNKe é concatenado com o ID de registro exclusivo da origem, bem como um contador de registros e um sufixo de.csv: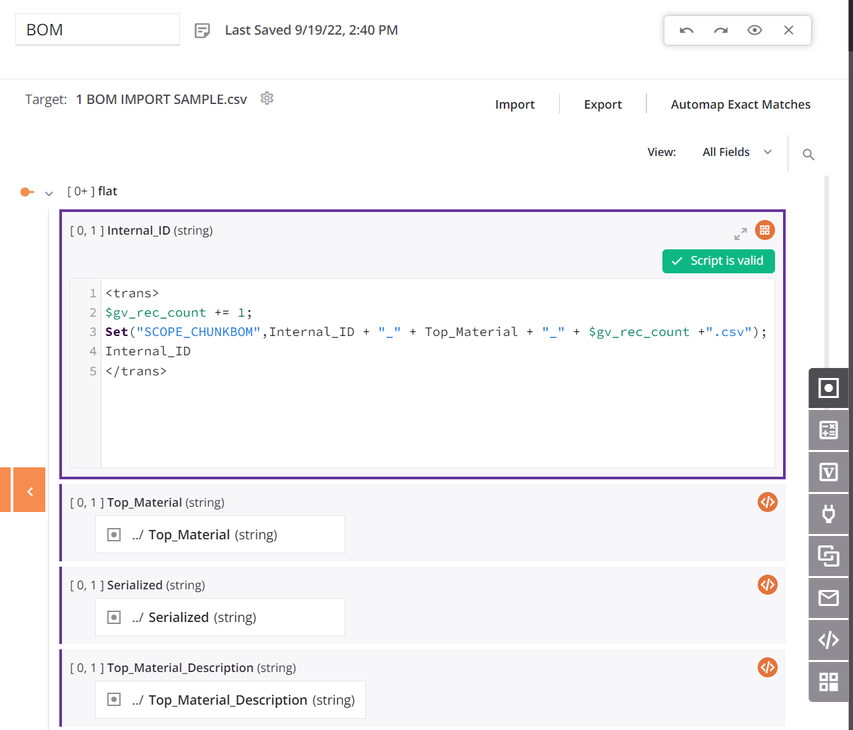
-
O alvo é um Armazenamento Temporário Atividade Write configurada com um caminho padrão e a variável global de nome de arquivo definida anteriormente.
-
Os scripts servem para registrar a saída e são opcionais. O primeiro script obtém uma lista dos arquivos do diretório e percorre a lista, registrando o nome e o tamanho do arquivo e, em seguida, passa o nome do arquivo para uma operação com outro script que registra o conteúdo do arquivo. (Veja as capturas de tela do JSON Hierárquico exemplo acima.)
-
As opções de operação deve ser configurado com Enable Chunking selecionado, com um Chunk Size de
1, Número de registros por arquivo de1e Número máximo de threads de1.
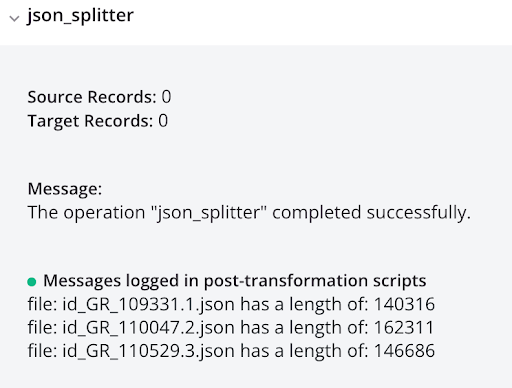
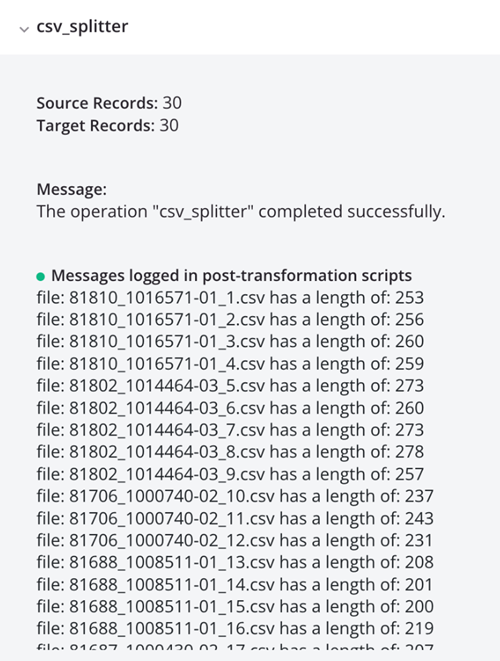
A execução da operação resulta em registros CSV individuais, mostrados na saída do log:
JSON Hierárquico¶
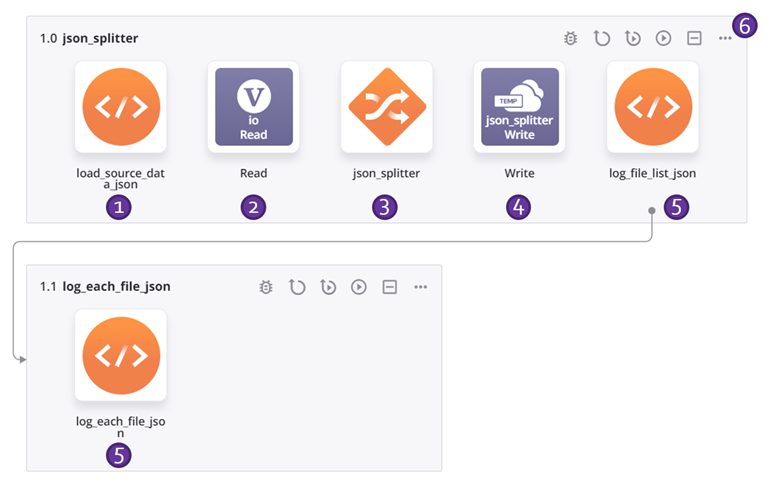
Este exemplo de cadeia de operação aplica o padrão de design descrito acima para dividir dados JSON hierárquicos em um arquivo para cada registro. Cada número corresponde a uma descrição da etapa de operação abaixo.
Nota
Este padrão de design não é mais o método recomendado para dividir dados JSON hierárquicos. Para obter o método recomendado, consulte Dividir um arquivo em registros individuais usando SourceInstanceCount.
-
O script atribui os dados de origem a uma variável global chamada
io(entrada/saída). (Um script é usado para fins de demonstração; os dados de origem também podem vir de um endpoint configurado.)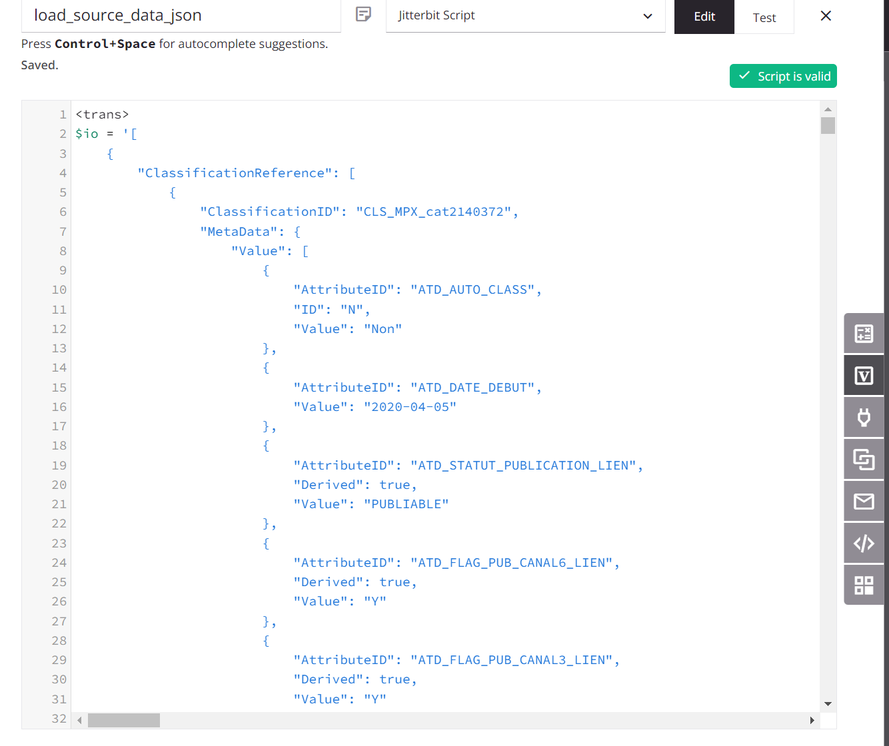
-
O
iovariável global é usada para configurar uma Variável endpoint e uma atividade Variable Read associada é usada pela operação como a origem da transformação:
-
Dentro da transformação, a origem e o destino usam o mesmo esquema e todos os campos são mapeados:
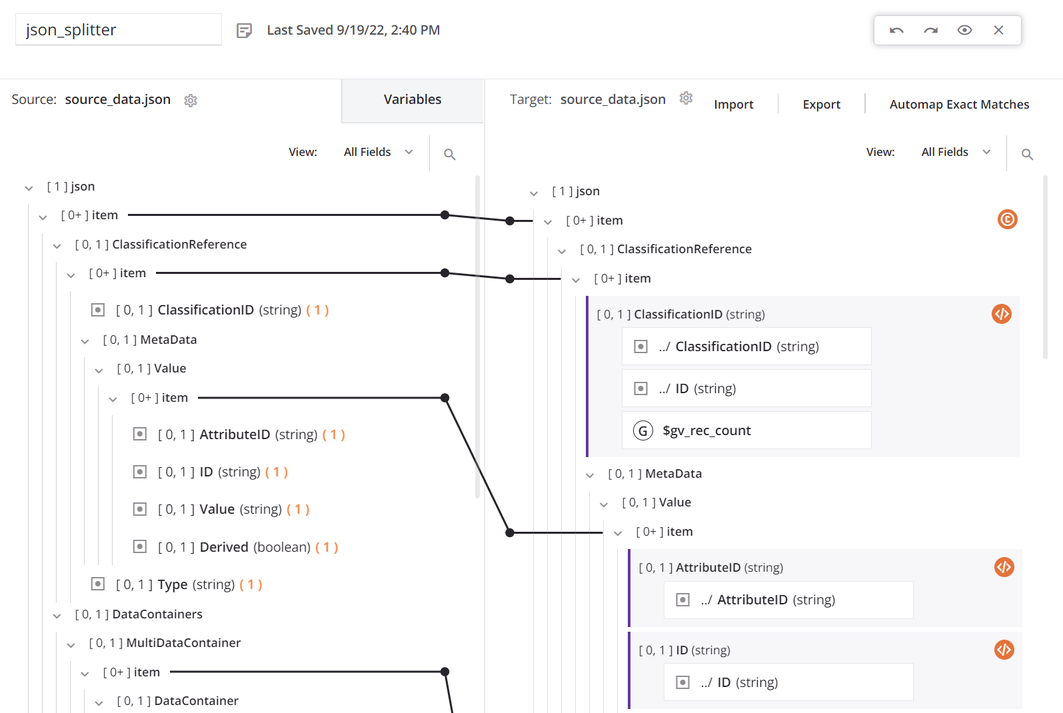
O topo
itemO nó tem uma condição para gerar a contagem de registros. O primeiro campo de dados no mapeamento de transformação está configurado para usarSCOPE_CHUNK. OSeta função é usada para construir uma variável começando com a fraseSCOPE_CHUNKe é concatenado com o ID de registro exclusivo da origem, bem como um contador de registros e um sufixo de.json: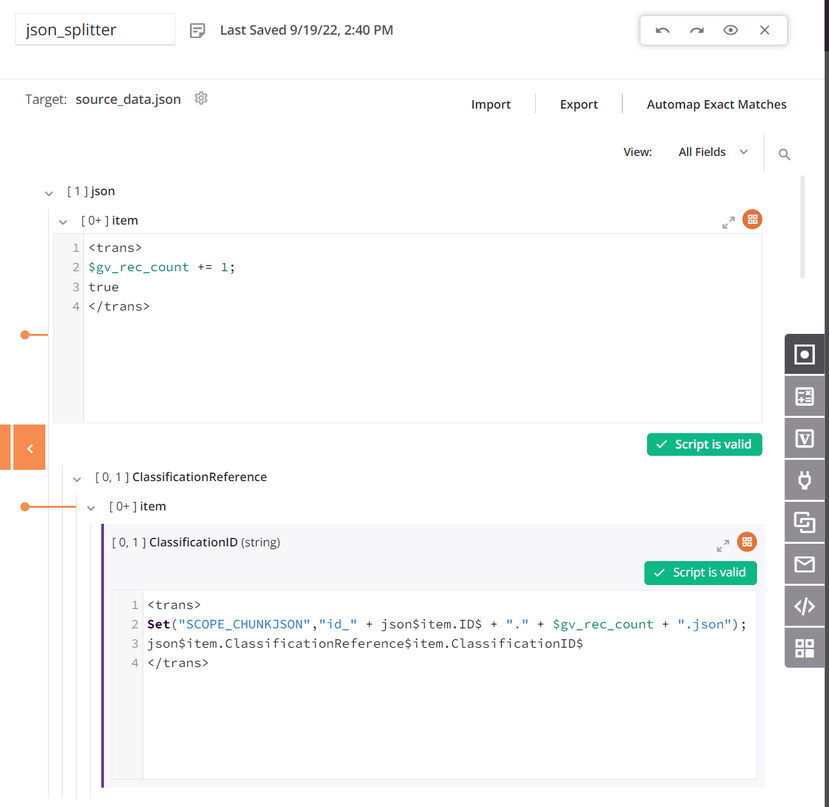
-
O alvo é um Armazenamento Temporário Atividade Write configurada com um caminho padrão e a variável global de nome de arquivo definida anteriormente:
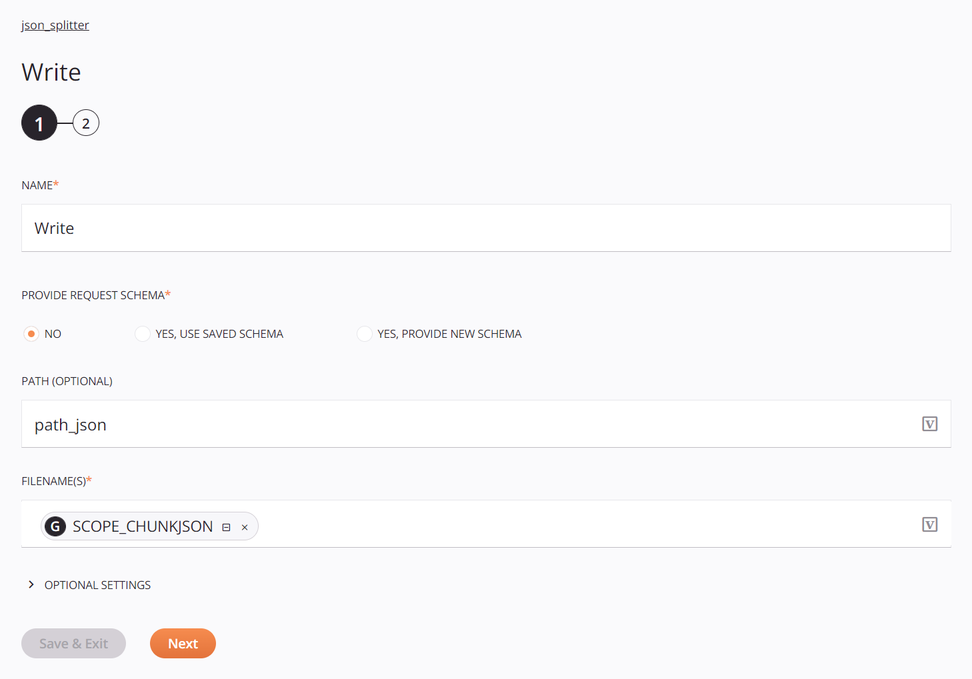
-
Os scripts servem para registrar a saída e são opcionais. O primeiro script obtém uma lista dos arquivos do diretório e percorre a lista, registrando o nome e o tamanho do arquivo e, em seguida, passa o nome do arquivo para uma operação com outro script que registra o conteúdo do arquivo:
log_file_list_json<trans> arr = Array(); arr = FileList("<TAG>activity:tempstorage/json_splitter/tempstorage_read/Read</TAG>"); cnt = Length(arr); i = 0; While(i < cnt, filename = arr[i]; file = ReadFile("<TAG>activity:tempstorage/json_splitter/tempstorage_read/Read</TAG>",filename); WriteToOperationLog("file: " + filename + " has a length of: " + Length(file)); $gv_file_filter = filename; RunOperation("<TAG>operation:log_each_file_json</TAG>"); i++ ); </trans>log_each_file_json<trans> WriteToOperationLog(ReadFile("<TAG>activity:tempstorage/json_splitter/tempstorage_read/Read</TAG>",$gv_file_filter)); </trans> -
As opções de operação deve ser configurado com Enable Chunking selecionado, com um Chunk Size de
1, Número de registros por arquivo de1e Número máximo de threads de1: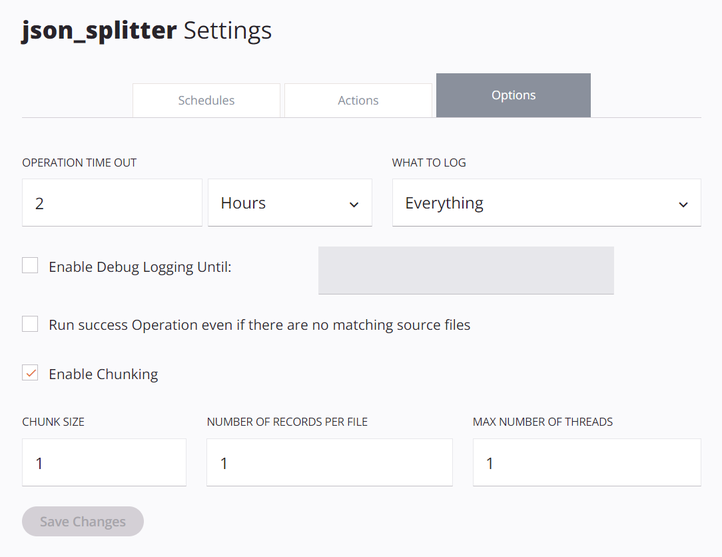
A execução da operação resulta em registros JSON individuais, mostrados na saída do log: