Atividade de Inserção de Snowflake¶
Introdução¶
Uma atividade Snowflake Insert, usando sua conexão Snowflake, insere dados da tabela (como um arquivo CSV ou mapeado diretamente nas colunas de uma tabela) no Snowflake e deve ser usado como um destino para consumir dados em uma operação.
Crie uma Atividade de Inserção de Snowflake¶
Uma instância de uma atividade Snowflake Insert é criada a partir de uma conexão Snowflake usando seu tipo de atividade Insert.
Para criar uma instância de uma atividade, arraste o tipo de atividade para a quadro de design ou copie o tipo de atividade e cole-o na quadro de design. Para obter detalhes, consulte Criando uma instância de atividade em Reutilização de componentes.
Uma atividade Snowflake Insert existente pode ser editada nestes locais:
- A quadro de design (consulte Menu Ações do componente em Quadro de Design).
- A aba Componentes do painel do projeto (consulte Menu Ações do componente em Guia Componentes do painel do projeto).
Configurar uma Atividade de Inserção de Snowflake¶
Siga estas etapas para configurar uma atividade Snowflake Insert:
-
Etapa 1: Insira um nome e selecione um objeto
Forneça um nome para a atividade e selecione um objeto, seja uma tabela ou uma visualização. -
Etapa 2: Selecione uma abordagem
Diferentes abordagens são suportadas para inserir dados no Snowflake. Escolha entre Arquivo de teste ou Inserção SQL. Ao usar a abordagem Arquivo de teste, você pode selecionar os tipos de arquivo de teste Amazon S3 ou Interno. -
Etapa 3: Revise os esquemas de dados
Quaisquer esquemas de solicitação ou resposta gerados a partir do endpoint são exibidos.
Etapa 1: Insira um Nome e Selecione um Objeto¶
Nesta etapa, forneça um nome para a atividade e selecione uma tabela ou visualização (consulte Visão geral das visualizações do Snowflake). Cada elemento da interface do usuário desta etapa é descrito abaixo.
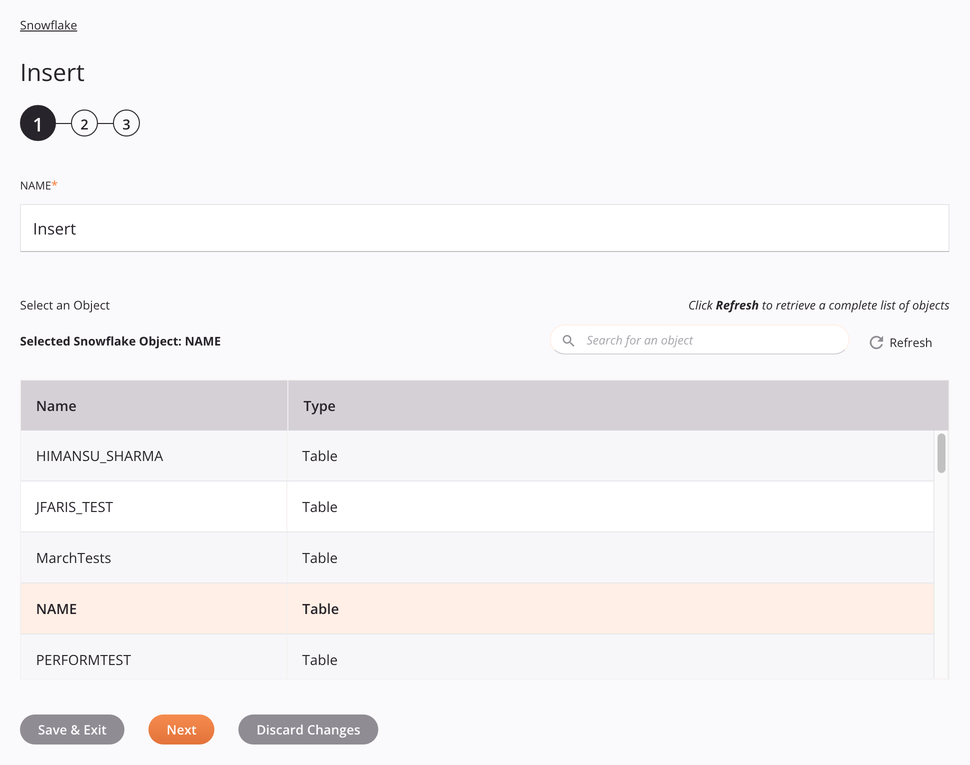
-
Nome: Insira um nome para identificar a atividade. O nome deve ser exclusivo para cada atividade Snowflake Insert e não deve conter barras
/ou dois pontos:. -
Selecione um objeto: Esta seção exibe objetos disponíveis no endpoint Snowflake. Ao reabrir uma configuração de atividade existente, apenas o objeto selecionado é exibido em vez de recarregar toda a lista de objetos.
-
Objeto Snowflake selecionado: Depois que um objeto é selecionado, ele é listado aqui.
-
Pesquisar: Insira qualquer parte do nome do objeto na caixa de pesquisa para filtrar a lista de objetos. A busca não diferencia maiúsculas de minúsculas. Se os objetos já estiverem exibidos na tabela, os resultados da tabela serão filtrados em tempo real a cada pressionamento de tecla. Para recarregar objetos do endpoint durante a pesquisa, insira os critérios de pesquisa e atualize, conforme descrito abaixo.
-
Atualizar: Clique no ícone de atualização
 ou a palavra Refresh para recarregar objetos do endpoint Snowflake. Isso pode ser útil se objetos tiverem sido adicionados ao Snowflake. Esta ação atualiza todos os metadados usados para construir a tabela de objetos exibidos na configuração.
ou a palavra Refresh para recarregar objetos do endpoint Snowflake. Isso pode ser útil se objetos tiverem sido adicionados ao Snowflake. Esta ação atualiza todos os metadados usados para construir a tabela de objetos exibidos na configuração. -
Selecionando um objeto: Na tabela, clique em qualquer lugar de uma linha para selecionar um objeto. Apenas um objeto pode ser selecionado. As informações disponíveis para cada objeto são obtidas no endpoint Snowflake:
-
Nome: O nome de um objeto, seja uma tabela ou uma visualização.
-
Tipo: O tipo do objeto, seja uma tabela ou uma visualização.
-
Dica
Se a tabela não for preenchida com objetos disponíveis, a conexão Snowflake pode não ter sucesso. Certifique-se de estar conectado reabrindo a conexão e testando novamente as credenciais.
-
-
Salvar e Sair: Se ativado, clique para salvar a configuração desta etapa e feche a configuração da atividade.
-
Próximo: Clique para armazenar temporariamente a configuração desta etapa e continuar para a próxima etapa. A configuração não será salva até que você clique no botão Concluído na última etapa.
-
Descartar alterações: Após fazer as alterações, clique para fechar a configuração sem salvar as alterações feitas em nenhuma etapa. Uma mensagem solicita que você confirme que deseja descartar as alterações.
Etapa 2: Selecione uma Abordagem¶
Diferentes abordagens são suportadas para inserir dados no Snowflake. Escolha entre Inserção SQL ou Arquivo de teste. Ao usar a abordagem Arquivo de teste, você seleciona os tipos de arquivo de teste Amazon S3 ou Interno.
- Abordagem de Inserção SQL
- Abordagem de arquivo de estágio do Amazon S3
- Abordagem de arquivo de estágio do Google Cloud Storage
- Abordagem de arquivo de estágio interno
- Abordagem de arquivo de estágio do Microsoft Azure
abordagem de Inserção SQL¶
Para esta abordagem, as colunas da tabela serão mostradas na etapa do esquema de dados a seguir, permitindo que sejam mapeadas em uma transformação.
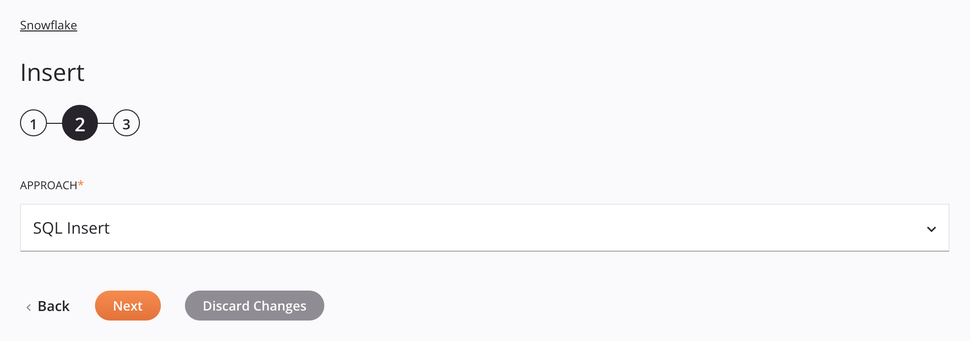
-
Abordagem: Use o menu suspenso para selecionar SQL Insert.
-
Voltar: Clique para retornar à etapa anterior e armazenar temporariamente a configuração.
-
Próximo: Clique para continuar para a próxima etapa e armazenar temporariamente a configuração. A configuração não será salva até que você clique no botão Concluído na última etapa.
-
Descartar alterações: Após fazer as alterações, clique para fechar a configuração sem salvar as alterações feitas em nenhuma etapa. Uma mensagem solicita que você confirme que deseja descartar as alterações.
Abordagem de Arquivo de Estágio do Amazon S3¶
Essa abordagem permite que um arquivo CSV seja inserido no Snowflake usando uma fonte do Amazon S3. O arquivo é preparado e copiado na tabela seguindo as especificações do esquema de dados da solicitação.
Para obter informações sobre como fazer solicitações ao Amazon S3, consulte Fazer solicitações na documentação do Amazon S3.
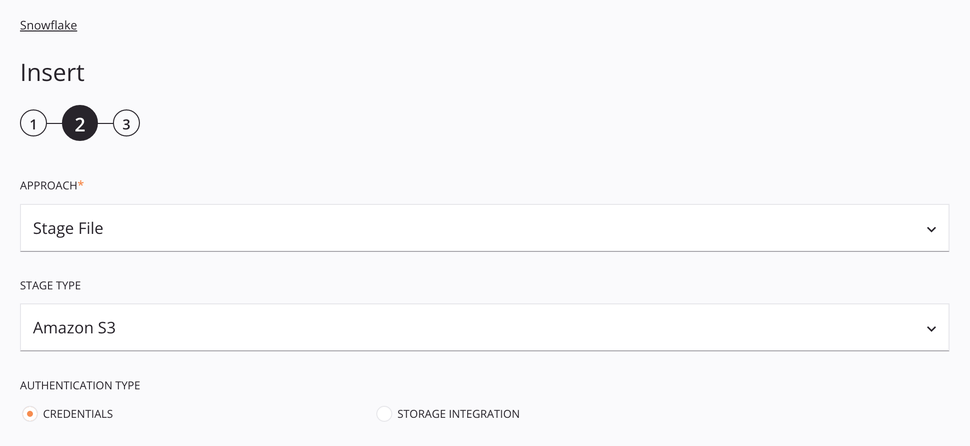
-
Abordagem: Use o menu suspenso para selecionar Arquivo de teste.
-
Tipo de estágio: Escolha Amazon S3 para recuperar dados do armazenamento do Amazon S3.
-
Tipo de autenticação: Escolha entre Credenciais ou Integração de armazenamento. Credenciais requerem o ID da chave de acesso do Amazon S3 e a chave de acesso secreta. Integração de armazenamento requer apenas o nome da integração de armazenamento. Esses tipos de autenticação são abordados abaixo.
Autenticação de Credenciais¶
O tipo de autenticação Credentials requer o ID da chave de acesso do Amazon S3 e a chave de acesso secreta (para obter informações sobre como fazer solicitações ao Amazon S3, consulte Como fazer solicitações na documentação do Amazon S3).
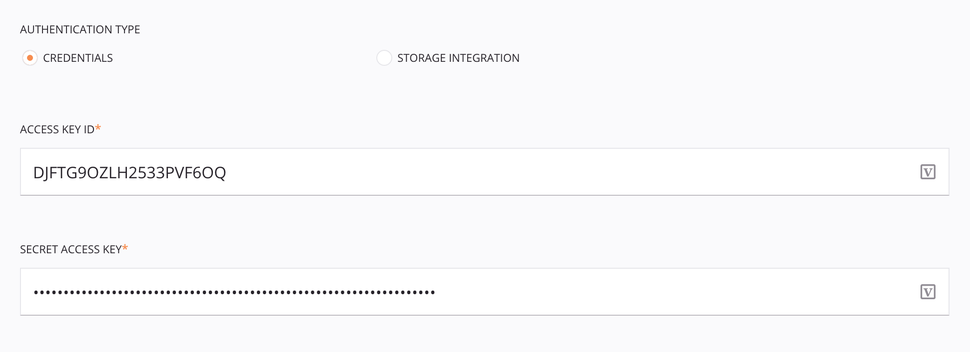
-
Tipo de autenticação: Escolha Credenciais.
-
ID da chave de acesso: Insira o ID da chave de acesso do Amazon S3.
-
Chave de acesso secreta: Insira a chave de acesso secreta do Amazon S3.
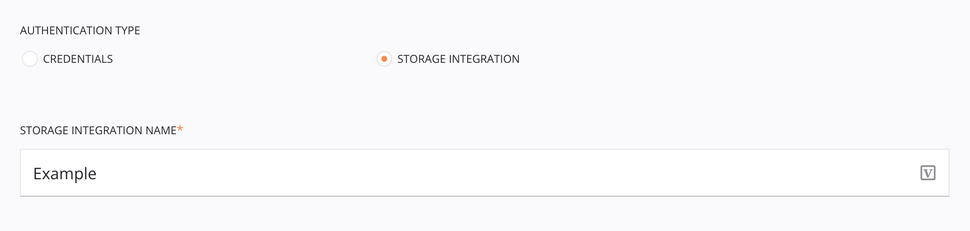
Autenticação de Integração de Armazenamento¶
O tipo de autenticação Storage Integration requer a criação de uma integração de armazenamento Snowflake. Para obter informações sobre como criar uma integração de armazenamento Snowflake, consulte Criar integração de armazenamento na documentação do Snowflake.
-
Tipo de autenticação: Escolha Integração de armazenamento.
-
Nome da integração de armazenamento: Insira o nome da integração de armazenamento do Snowflake.
Opções Adicionais¶
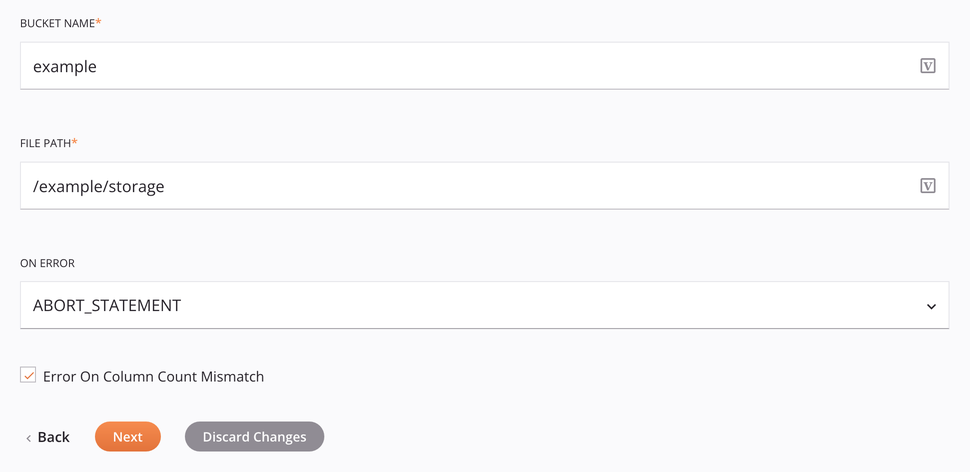
Para a autenticação Credenciais e Integração de armazenamento, existem estas opções adicionais:
-
Nome do bucket: Insira um nome de bucket válido para um bucket existente no servidor Amazon S3. Isto é ignorado se
bucketNameé fornecido no esquema de dadosInsertAmazonS3Request. -
Caminho do arquivo: Insira o caminho do arquivo.
-
Em caso de erro: Escolha uma destas opções no menu suspenso Em caso de erro; opções adicionais aparecerão conforme apropriado:
-
Abort_Statement: Aborta o processamento se algum erro for encontrado.
-
Continuar: Continua carregando o arquivo mesmo se forem encontrados erros.
-
Skip_File: Ignora o arquivo se algum erro for encontrado no arquivo.
-
Skip_File_\<num>: Ignora o arquivo quando o número de erros no arquivo for igual ou superior ao número especificado em Skip File Number.
-
Skip_File_\<num>%: Ignora o arquivo quando a porcentagem de erros no arquivo excede a porcentagem especificada em Porcentagem de número de arquivo ignorado.
-
-
Erro na incompatibilidade de contagem de colunas: Se selecionado, relata um erro no nó de erro do esquema de resposta se as contagens de colunas de origem e de destino não corresponderem. Se você não selecionar esta opção, a operação não falhará e os dados fornecidos serão inseridos.
-
Voltar: Clique para retornar à etapa anterior e armazenar temporariamente a configuração.
-
Próximo: Clique para continuar para a próxima etapa e armazenar temporariamente a configuração. A configuração não será salva até que você clique no botão Concluído na última etapa.
-
Descartar alterações: Após fazer as alterações, clique para fechar a configuração sem salvar as alterações feitas em nenhuma etapa. Uma mensagem solicita que você confirme que deseja descartar as alterações.
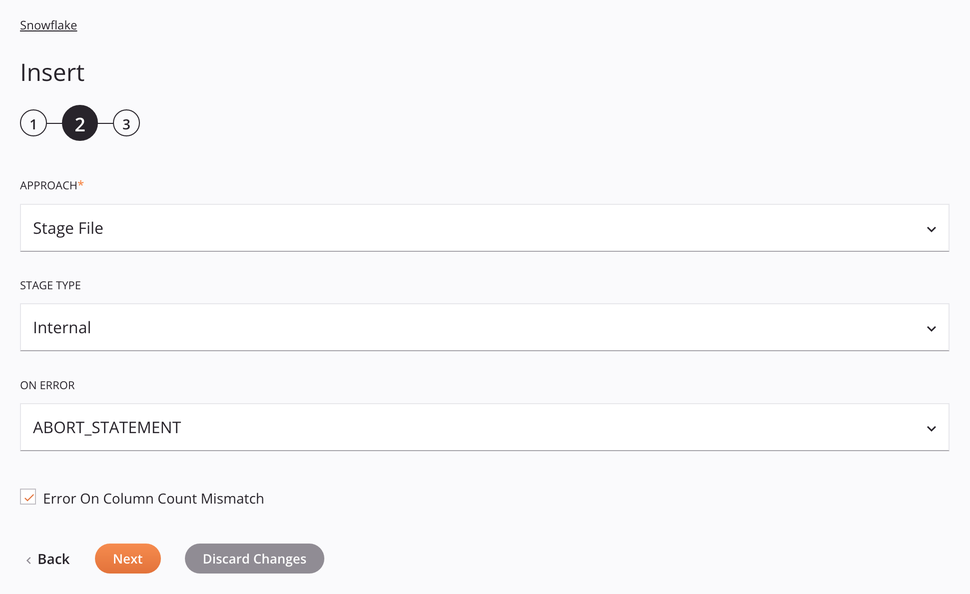
abordagem de Arquivo de Estágio Interno¶
Essa abordagem permite que um arquivo CSV seja inserido no Snowflake. O arquivo será preparado e copiado na tabela seguindo as especificações do esquema de dados da solicitação.
-
Abordagem: Use o menu suspenso para selecionar Arquivo de teste.
-
Tipo de estágio: Escolha Interno para recuperar os dados de uma fonte interna.
-
Em caso de erro: Escolha uma destas opções no menu suspenso Em caso de erro; opções adicionais aparecerão conforme apropriado:
-
Abort_Statement: Aborta o processamento se algum erro for encontrado.
-
Continuar: Continua carregando o arquivo mesmo se forem encontrados erros.
-
Skip_File: Ignora o arquivo se algum erro for encontrado no arquivo.
-
Skip_File_\<num>: Ignora o arquivo quando o número de erros no arquivo for igual ou superior ao número especificado em Skip File Number.
-
Skip_File_\<num>%: Ignora o arquivo quando a porcentagem de erros no arquivo excede a porcentagem especificada em Porcentagem de número de arquivo ignorado.
-
-
Erro na incompatibilidade de contagem de colunas: Se selecionado, relata um erro no nó de erro do esquema de resposta se as contagens de colunas de origem e de destino não corresponderem. Se você não selecionar esta opção, a operação não falhará e os dados fornecidos serão inseridos.
-
Voltar: Clique para retornar à etapa anterior e armazenar temporariamente a configuração.
-
Próximo: Clique para continuar para a próxima etapa e armazenar temporariamente a configuração. A configuração não será salva até que você clique no botão Concluído na última etapa.
-
Descartar alterações: Após fazer as alterações, clique para fechar a configuração sem salvar as alterações feitas em nenhuma etapa. Uma mensagem solicita que você confirme que deseja descartar as alterações.
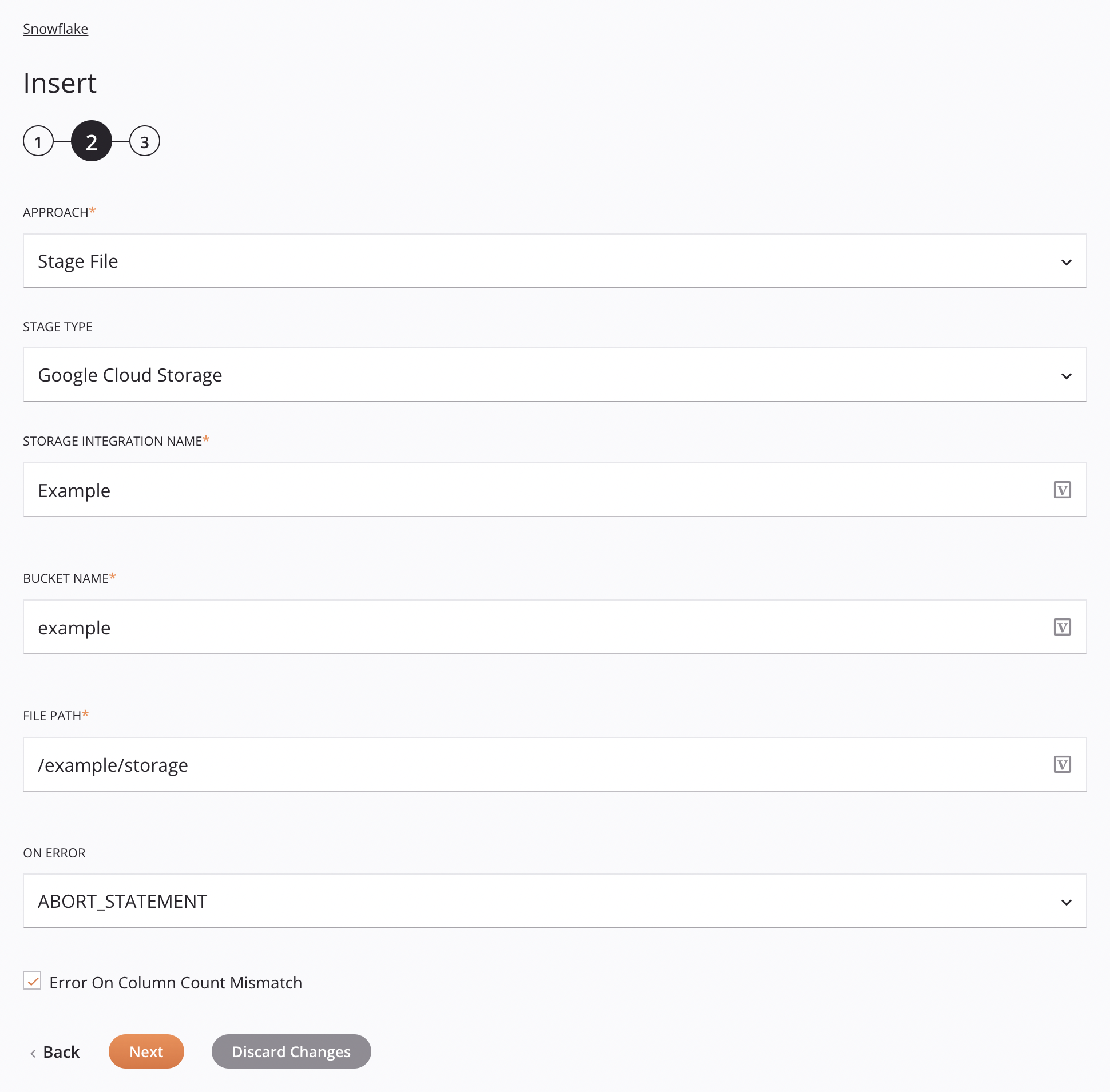
Abordagem de Arquivo de Estágio do Google Cloud Storage¶
Essa abordagem permite que um arquivo CSV seja inserido no Google Cloud Storage. O arquivo será preparado e copiado na tabela seguindo as especificações do esquema de dados da solicitação.
-
Abordagem: Use o menu suspenso para selecionar Arquivo de teste.
-
Tipo de estágio: Escolha Google Cloud Storage para recuperar os dados de uma fonte interna.
-
Nome da integração de armazenamento: Insira o nome da integração de armazenamento do Snowflake.
-
Nome do intervalo: Insira um nome de intervalo válido para um intervalo existente no Google Cloud Storage. Isto é ignorado se
bucketNameé fornecido no esquema de dadosInsertGoogleCloudRequest. -
Caminho do arquivo: Insira o caminho do arquivo.
-
Em caso de erro: Escolha uma destas opções no menu suspenso Em caso de erro; opções adicionais aparecerão conforme apropriado:
-
Abort_Statement: Aborta o processamento se algum erro for encontrado.
-
Continuar: Continua carregando o arquivo mesmo se forem encontrados erros.
-
Skip_File: Ignora o arquivo se algum erro for encontrado no arquivo.
-
Skip_File_\<num>: Ignora o arquivo quando o número de erros no arquivo for igual ou superior ao número especificado em Skip File Number.
-
Skip_File_\<num>%: Ignora o arquivo quando a porcentagem de erros no arquivo excede a porcentagem especificada em Porcentagem de número de arquivo ignorado.
-
-
Erro na incompatibilidade de contagem de colunas: Se selecionado, relata um erro no nó de erro do esquema de resposta se as contagens de colunas de origem e de destino não corresponderem. Se você não selecionar esta opção, a operação não falhará e os dados fornecidos serão inseridos.
-
Voltar: Clique para retornar à etapa anterior e armazenar temporariamente a configuração.
-
Próximo: Clique para continuar para a próxima etapa e armazenar temporariamente a configuração. A configuração não será salva até que você clique no botão Concluído na última etapa.
-
Descartar alterações: Após fazer as alterações, clique para fechar a configuração sem salvar as alterações feitas em nenhuma etapa. Uma mensagem solicita que você confirme que deseja descartar as alterações.
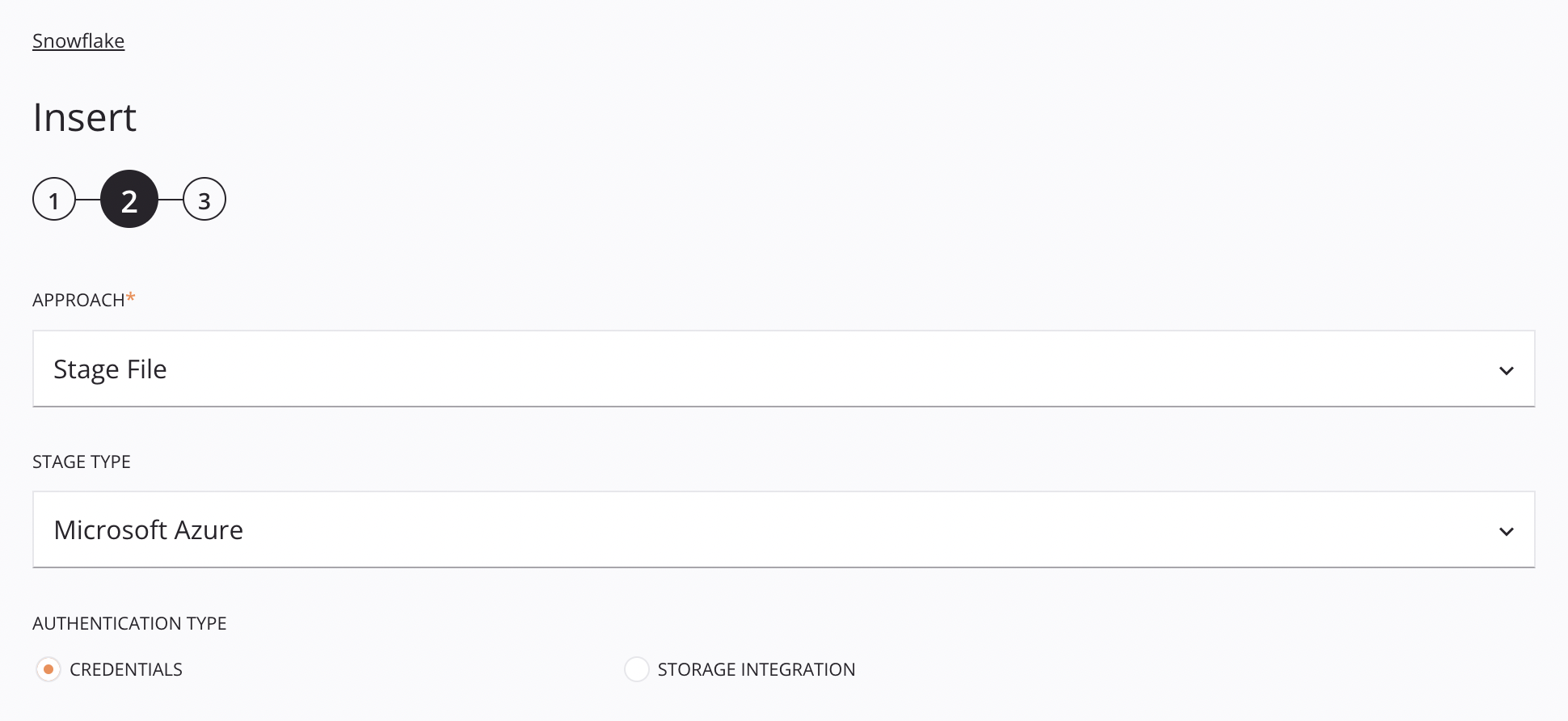
abordagem de Arquivo de Estágio do Microsoft Azure¶
Essa abordagem permite que um arquivo CSV seja inserido no Snowflake usando uma fonte do Microsoft Azure. O arquivo é preparado e copiado na tabela seguindo as especificações do esquema de dados da solicitação.
-
Abordagem: Use o menu suspenso para selecionar Arquivo de teste.
-
Tipo de estágio: Escolha Microsoft Azure para recuperar dados de contêineres de armazenamento do Microsoft Azure.
-
Tipo de autenticação: Escolha entre Credenciais ou Integração de armazenamento. Credenciais requerem um token SAS (assinatura de acesso compartilhado) do Microsoft Azure e um nome de conta de armazenamento. Integração de armazenamento requer apenas um nome de integração de armazenamento. Esses tipos de autenticação são abordados abaixo.
Autenticação de Credenciais¶
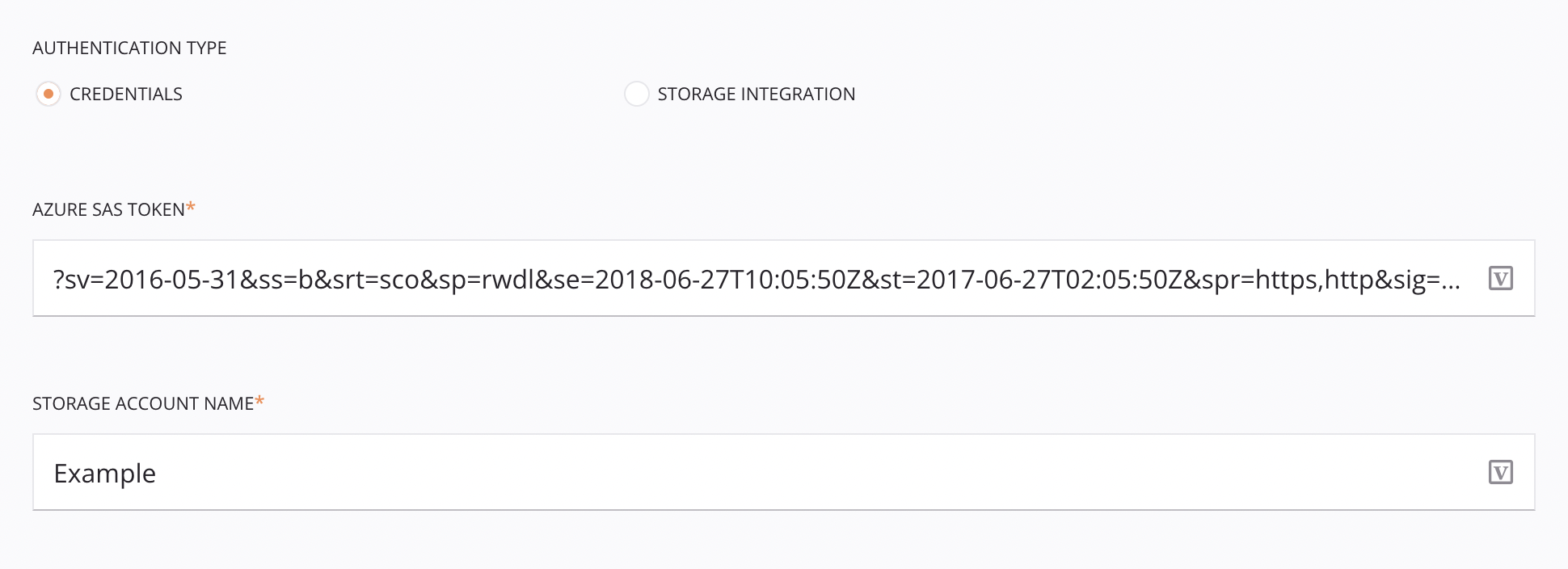
O tipo de autenticação Credenciais requer um token SAS do Microsoft Azure e um nome de conta de armazenamento.
-
Tipo de autenticação: Escolha Credenciais.
-
Token SAS do Azure: Insira o token SAS do Microsoft Azure. Para obter informações sobre como criar tokens SAS para contêineres de armazenamento no Microsoft Azure, consulte Criar tokens SAS para contêineres de armazenamento na documentação do Microsoft Azure.
-
Nome da conta de armazenamento: Insira o nome da conta de armazenamento do Microsoft Azure.
Autenticação de Integração de Armazenamento¶
O tipo de autenticação Storage Integration requer a criação de uma integração de armazenamento Snowflake. Para obter informações sobre como criar uma integração de armazenamento Snowflake, consulte Criar integração de armazenamento na documentação do Snowflake.

-
Tipo de autenticação: Escolha Integração de armazenamento.
-
Nome da integração de armazenamento: Insira o nome da integração de armazenamento do Snowflake.
Opções Adicionais¶
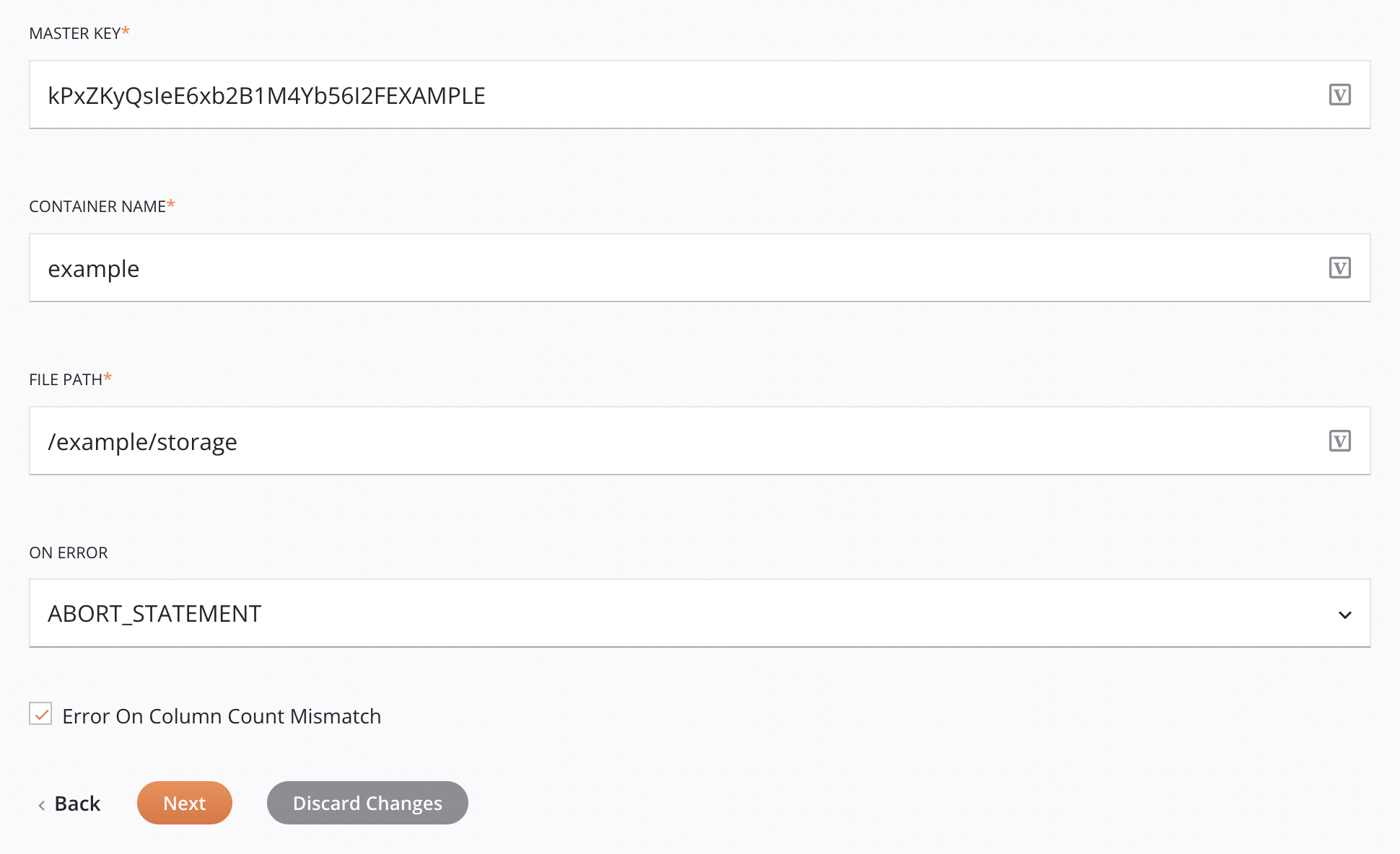
Para a autenticação Credenciais e Integração de armazenamento, existem estas opções adicionais:
-
Chave mestra: Insira a chave mestra usada para criptografia do lado do cliente (CSE) no Microsoft Azure. Isto é ignorado se
azureMasterKeyé fornecido no esquema de dadosInsertMicrosoftAzureCloudRequest.Nota
Para obter informações sobre como criar chaves no Microsoft Azure, consulte Início rápido: definir e recuperar uma chave do Azure Key Vault usando o portal do Azure na documentação do Microsoft Azure.
Para obter informações sobre armazenamento CSE no Microsoft Azure, consulte criptografia do lado do cliente para blobs na documentação do Microsoft Azure.
-
Nome do contêiner: Insira um nome de bucket válido para um contêiner de armazenamento existente no Microsoft Azure. Isto é ignorado se
containerNameé fornecido no esquema de dadosInsertMicrosoftAzureCloudRequest. -
Caminho do arquivo: Insira o caminho do arquivo.
-
Em caso de erro: Escolha uma destas opções no menu suspenso Em caso de erro; opções adicionais aparecerão conforme apropriado:
-
Abort_Statement: Aborta o processamento se algum erro for encontrado.
-
Continuar: Continua carregando o arquivo mesmo se forem encontrados erros.
-
Skip_File: Ignora o arquivo se algum erro for encontrado no arquivo.
-
Skip_File_\<num>: Ignora o arquivo quando o número de erros no arquivo for igual ou superior ao número especificado em Skip File Number.
-
Skip_File_\<num>%: Ignora o arquivo quando a porcentagem de erros no arquivo excede a porcentagem especificada em Porcentagem de número de arquivo ignorado.
-
-
Erro na incompatibilidade de contagem de colunas: Se selecionado, relata um erro no nó de erro do esquema de resposta se as contagens de colunas de origem e de destino não corresponderem. Se você não selecionar esta opção, a operação não falhará e os dados fornecidos serão inseridos.
-
Voltar: Clique para retornar à etapa anterior e armazenar temporariamente a configuração.
-
Próximo: Clique para continuar para a próxima etapa e armazenar temporariamente a configuração. A configuração não será salva até que você clique no botão Concluído na última etapa.
-
Descartar alterações: Após fazer as alterações, clique para fechar a configuração sem salvar as alterações feitas em nenhuma etapa. Uma mensagem solicita que você confirme que deseja descartar as alterações.
Etapa 3: Revise os Esquemas de Dados¶
Os esquemas de solicitação e resposta gerados a partir do endpoint são exibidos. Os esquemas exibidos dependem da Abordagem especificada na etapa anterior.
Estas subseções descrevem as estruturas de solicitação e resposta para cada combinação de abordagem e tipo de estágio:
- Abordagem de Inserção SQL
- Abordagem de arquivo de estágio do Amazon S3
- Abordagem de arquivo de estágio do Google Cloud Storage
- Abordagem de arquivo de estágio interno
- Abordagem de arquivo de estágio do Microsoft Azure
Estas ações estão disponíveis com cada abordagem:
-
Esquemas de dados: Esses esquemas de dados são herdados por transformações adjacentes e são exibidos novamente durante o mapeamento de transformação.
Nota
Os dados fornecidos em uma transformação têm precedência sobre a configuração da atividade.
O conector Snowflake usa o Driver JDBC Snowflake e os comandos SQL do Snowflake. Consulte a documentação da API para obter informações sobre os nós e campos do esquema.
-
Atualizar: Clique no ícone de atualização
ou a palavra Refresh para regenerar esquemas do endpoint Snowflake. Esta ação também regenera um esquema em outros locais do projeto onde o mesmo esquema é referenciado, como em uma transformação adjacente. -
Voltar: Clique para armazenar temporariamente a configuração desta etapa e retornar à etapa anterior.
-
Concluído: Clique para salvar a configuração de todas as etapas e fechar a configuração da atividade.
-
Descartar alterações: Após fazer as alterações, clique para fechar a configuração sem salvar as alterações feitas em nenhuma etapa. Uma mensagem solicita que você confirme que deseja descartar as alterações.
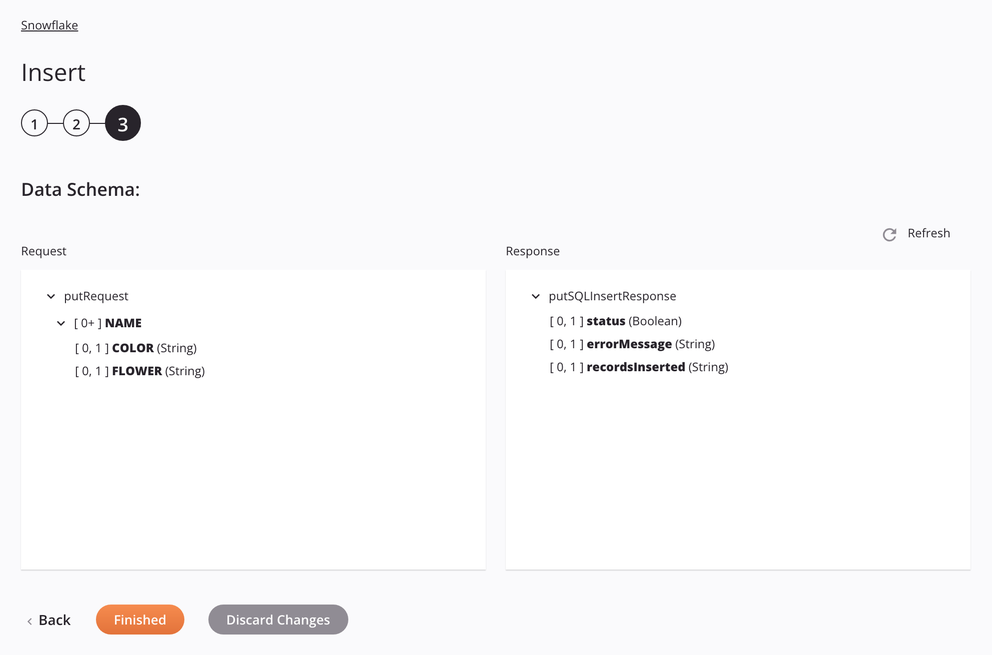
abordagem de Inserção SQL¶
Se a abordagem for SQL Insert, as colunas da tabela serão mostradas, permitindo que sejam mapeadas em uma transformação.
-
Solicitar
Campo/nó do esquema de solicitação Notas tableNó mostrando o nome da tabela. column_ANome da primeira coluna da tabela. column_BNome da segunda coluna da tabela. . . .Colunas seguintes da tabela. -
Resposta
Campo/nó do esquema de resposta Notas statusSinalizador booleano informando se a inserção do registro foi bem-sucedida. errorMessageMensagem de erro descritiva em caso de falha durante a inserção. recordsInsertedNúmero de registros inseridos se a inserção for bem-sucedida.
Abordagem de Arquivo de Estágio do Amazon S3¶
Se a abordagem for Arquivo de preparação do Amazon S3, as especificações para preparação e inserção de um arquivo CSV serão mostradas no esquema de dados para que possam ser mapeadas em uma transformação. O padrão usado é corresponder a apenas um arquivo. Se o padrão corresponder a mais de um arquivo, a atividade apresentará um erro com uma mensagem descritiva.
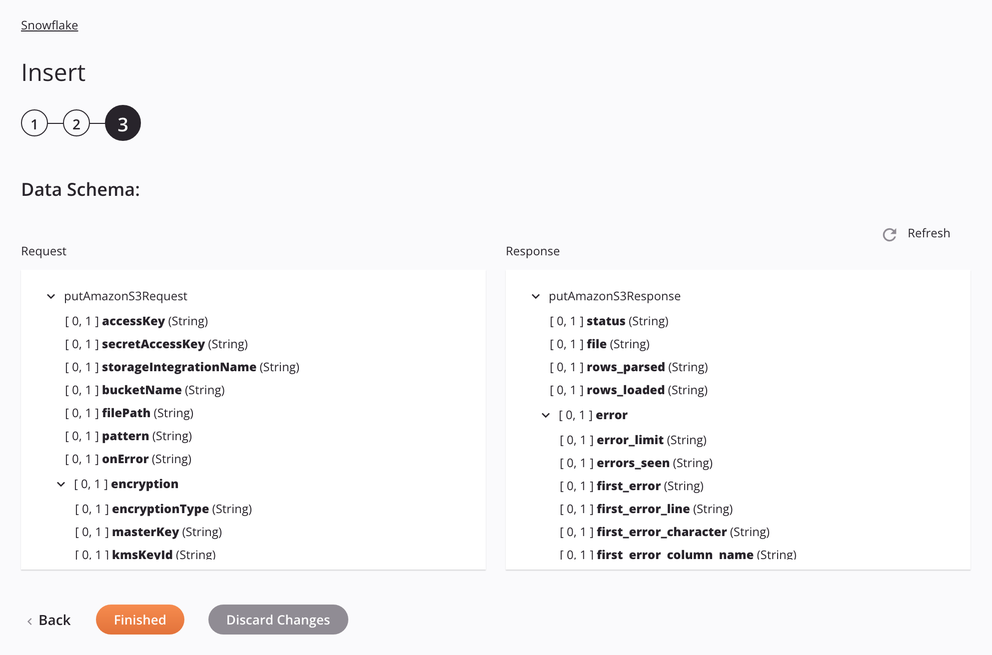
-
Solicitar
Campo/nó do esquema de solicitação Notas accessKeyID da chave de acesso do Amazon S3. secretAccessKeyChave de acesso secreta do Amazon S3. storageintegrationNameNome da integração de armazenamento Snowflake a ser usada para autenticação de integração de armazenamento Snowflake. bucketNameNome de bucket válido para um bucket existente no servidor Amazon S3. filePathLocal do arquivo de teste no bucket do Amazon S3. patternPadrão de expressão regular usado para localizar o arquivo no palco; se compressionéGZIP,[.]gzé anexado ao padrão.onErrorEm caso de erro opção selecionada. encryptionNó que representa a criptografia. encryptionTypeTipo de criptografia do Amazon S3 ( criptografia do lado do servidor ou criptografia do lado do cliente). masterKeyChave mestra do Amazon S3. kmsKeyIdServiço de gerenciamento de chaves da Amazon Identidade Principal. fileFormatNó que representa o formato do arquivo. nullIfUma string a ser convertida em SQL NULL; por padrão, é uma string vazia. Veja oNULL_IFopção do SnowflakeCOPY INTO<location>documentação.enclosingCharCaractere usado para delimitar campos de dados; Veja o FIELD_OPTIONALLY_ENCLOSED_BYopção do SnowflakeCOPY INTO<location>documentação.Nota
O
enclosingCharpode ser um caractere de aspas simples'ou caractere de aspas duplas". Para usar o caractere de aspas simples, use o octal'ou o hexadecimal0x27representações ou use um escape de aspas simples duplas''. Quando um campo contém esse caractere, escape dele usando o mesmo caractere.compressionO algoritmo de compactação usado para os arquivos de dados. GZIPouNONEsão suportados. Veja a opção de compactação do SnowflakeCOPY INTO<location>documentação.skipHeaderNúmero de linhas no início do arquivo de origem a serem ignoradas. errorOnColumnCountMismatchSinalizador booleano para relatar um erro se as contagens de origem e destino do esquema de resposta não corresponderem. fieldDelimiterO caractere delimitador usado para separar campos de dados; Veja o FIELD_DELIMITERopção do SnowflakeCOPY INTO<table>documentação.recordDelimiterO caractere delimitador usado para separar grupos de campos; Veja o RECORD_DELIMITERopção do SnowflakeCOPY INTO<table>documentação. -
Resposta
Campo/nó do esquema de resposta Notas statusStatus retornado. fileNome do arquivo CSV preparado processado ao inserir dados na tabela Snowflake. rows_parsedNúmero de linhas analisadas do arquivo CSV. rows_loadedNúmero de linhas carregadas do arquivo CSV na tabela Snowflake sem erros. errorNó que representa as mensagens de erro. error_limitNúmero de erros que fazem com que o arquivo seja ignorado conforme definido em Skip_File_\<num>. errors_seenContagem de erros vistos. first_errorO primeiro erro no arquivo de origem. first_error_lineO número da primeira linha do primeiro erro. first_error_characterO primeiro caractere do primeiro erro. first_error_column_nameO nome da coluna do primeiro local de erro.
Abordagem de Arquivo de Estágio do Google Cloud Storage¶
Se a abordagem for Google Cloud Storage Stage File, as especificações para preparação e inserção de um arquivo CSV serão mostradas no esquema de dados para que possam ser mapeadas em uma transformação. O padrão usado é corresponder a apenas um arquivo. Se o padrão corresponder a mais de um arquivo, a atividade apresentará um erro com uma mensagem descritiva.
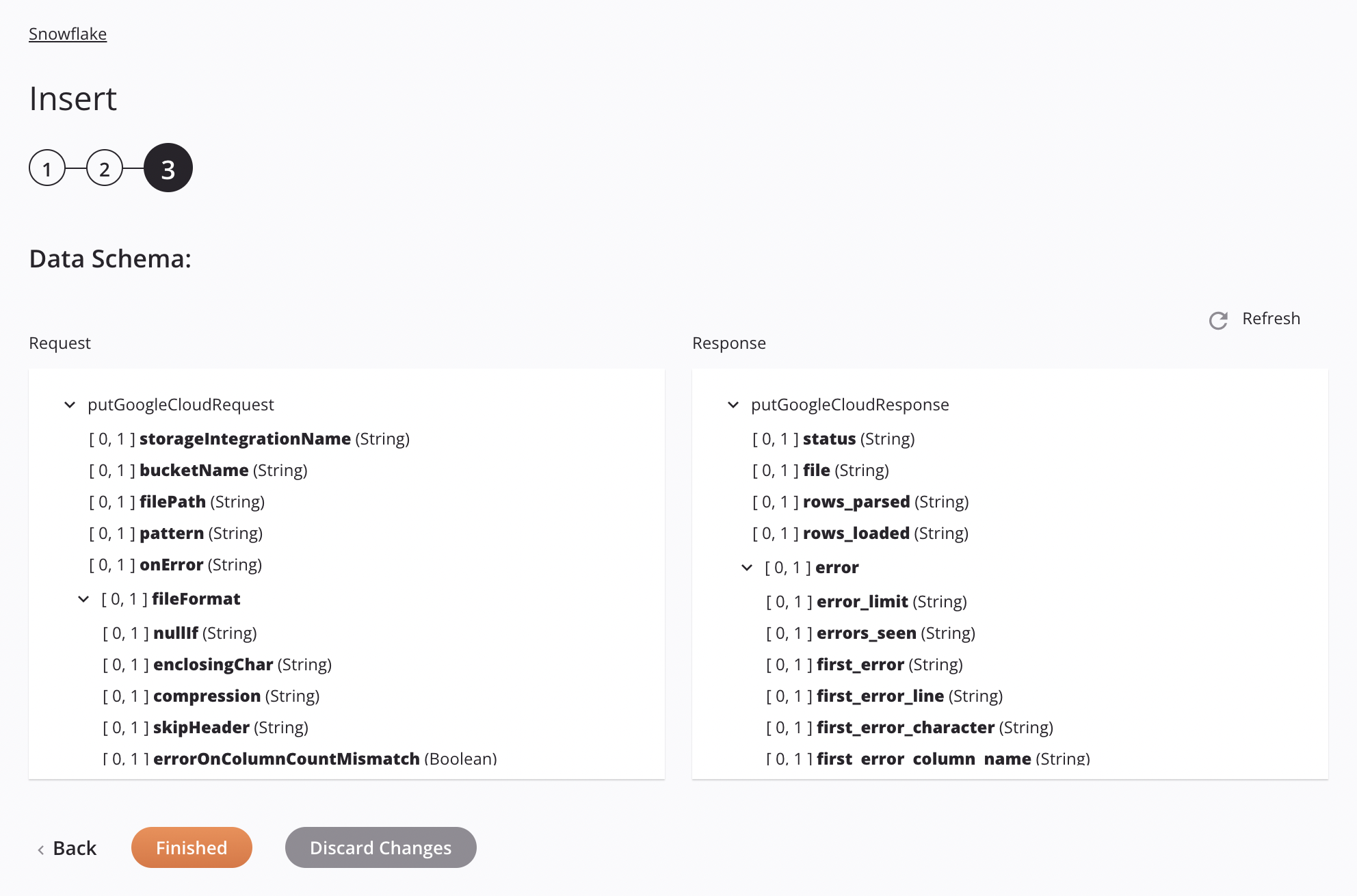
-
Solicitar
Campo/nó do esquema de solicitação Notas storageintegrationNameNome da integração de armazenamento Snowflake a ser usada para autenticação de integração de armazenamento Snowflake. bucketNameNome de bucket válido para um bucket existente no Google Cloud Storage. filePathLocalização do arquivo de teste no intervalo do Google Cloud Storage. patternPadrão de expressão regular usado para localizar o arquivo no palco; se compressDataé verdade,[.]gzé anexado ao padrão.onErrorEm caso de erro opção selecionada. fileFormatNó que representa o formato do arquivo. nullIfUma string a ser convertida em SQL NULL; por padrão, é uma string vazia. Veja oNULL_IFopção do SnowflakeCOPY INTO<location>documentação.enclosingCharCaractere usado para delimitar campos de dados; Veja o FIELD_OPTIONALLY_ENCLOSED_BYopção do SnowflakeCOPY INTO<location>documentação.Nota
O
enclosingCharpode ser um caractere de aspas simples'ou caractere de aspas duplas". Para usar o caractere de aspas simples, use o octal'ou o hexadecimal0x27representações ou use um escape de aspas simples duplas''. Quando um campo contém esse caractere, escape dele usando o mesmo caractere.compressionO algoritmo de compactação usado para os arquivos de dados. GZIPouNONEsão suportados. Veja a opção de compactação do SnowflakeCOPY INTO<location>documentação.skipHeaderNúmero de linhas no início do arquivo de origem a serem ignoradas. errorOnColumnCountMismatchSinalizador booleano para relatar um erro se as contagens de origem e destino do esquema de resposta não corresponderem. fieldDelimiterO caractere delimitador usado para separar campos de dados; Veja o FIELD_DELIMITERopção do SnowflakeCOPY INTO<table>documentação.recordDelimiterO caractere delimitador usado para separar grupos de campos; Veja o RECORD_DELIMITERopção do SnowflakeCOPY INTO<table>documentação. -
Resposta
Campo/nó do esquema de resposta Notas statusStatus retornado. fileNome do arquivo CSV preparado processado ao inserir dados na tabela Snowflake. rows_parsedNúmero de linhas analisadas do arquivo CSV. rows_loadedNúmero de linhas carregadas do arquivo CSV na tabela Snowflake sem erros. errorNó que representa as mensagens de erro. error_limitNúmero de erros que fazem com que o arquivo seja ignorado conforme definido em Skip_File_\<num>. errors_seenContagem de erros vistos. first_errorO primeiro erro no arquivo de origem. first_error_lineO número da primeira linha do primeiro erro. first_error_characterO primeiro caractere do primeiro erro. first_error_column_nameO nome da coluna do primeiro local de erro.
abordagem de Arquivo de Estágio Interno¶
Se a abordagem for Arquivo de preparação interno, as especificações para preparação e inserção de um arquivo CSV serão mostradas no esquema de dados para que possam ser mapeadas em uma transformação. O padrão usado é corresponder a apenas um arquivo. Se o padrão corresponder a mais de um arquivo, a atividade apresentará um erro com uma mensagem descritiva.
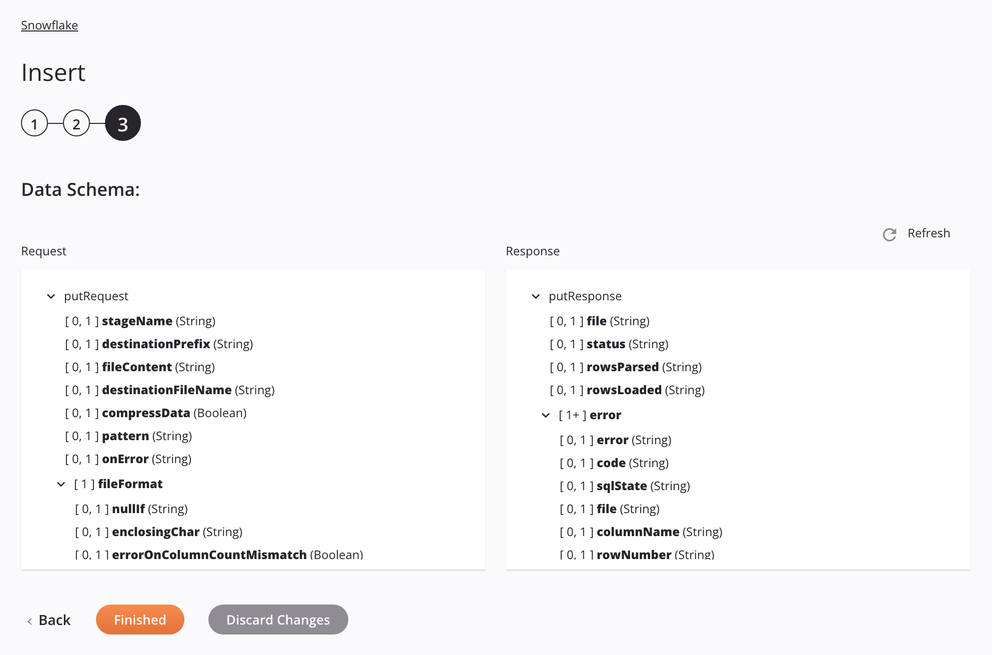
-
Solicitar
Campo/nó do esquema de solicitação Notas stageNameEstágio interno do Snowflake, nome da tabela ou caminho. destinationPrefixCaminho ou prefixo sob o qual os dados serão carregados no estágio Snowflake. fileContentConteúdo do arquivo de dados, em formato CSV, que será preparado para upload na tabela Snowflake. destinationFileNameNome do arquivo de destino a ser usado no estágio Snowflake. compressDataSinalizador booleano para compactar os dados antes de carregá-los para o estágio interno do Snowflake. patternPadrão de expressão regular usado para localizar o arquivo no palco; se compressDataé verdade,[.]gzé anexado ao padrão.onErrorEm caso de erro opção selecionada. fileFormatNó que representa o formato do arquivo. nullIfUma string a ser convertida em SQL NULL; por padrão, é uma string vazia. Veja oNULL_IFopção do SnowflakeCOPY INTO<location>documentação.enclosingCharCaractere usado para delimitar campos de dados; Veja o FIELD_OPTIONALLY_ENCLOSED_BYopção do SnowflakeCOPY INTO<location>documentação.Nota
O
enclosingCharpode ser um caractere de aspas simples'ou caractere de aspas duplas". Para usar o caractere de aspas simples, use o octal'ou o hexadecimal0x27representações ou use um escape de aspas simples duplas''. Quando um campo contém esse caractere, escape dele usando o mesmo caractere.errorOnColumnCountMismatchSinalizador booleano para relatar um erro se as contagens de origem e destino do esquema de resposta não corresponderem. fieldDelimiterO caractere delimitador usado para separar campos de dados; Veja o FIELD_DELIMITERopção do SnowflakeCOPY INTO<table>documentação.recordDelimiterO caractere delimitador usado para separar grupos de campos; Veja o RECORD_DELIMITERopção do SnowflakeCOPY INTO<table>documentação. -
Resposta
Campo/nó do esquema de resposta Notas fileNome do arquivo CSV preparado processado ao colocar dados na tabela Snowflake. statusStatus retornado. rowsParsedNúmero de linhas analisadas do arquivo CSV. rowsLoadedNúmero de linhas carregadas do arquivo CSV na tabela Snowflake sem erros. errorNó que representa as mensagens de erro. errorA mensagem de erro. codeO código de erro retornado. sqlStateO código de erro numérico do estado SQL retornado da chamada do banco de dados. fileNó que representa as mensagens de erro. columnNameNome e ordem da coluna que continha o erro. rowNumberO número da linha no arquivo de origem onde o erro foi encontrado. rowStartLineO número da primeira linha da linha onde o erro foi encontrado.
abordagem de Arquivo de Estágio do Microsoft Azure¶
Se a abordagem for Microsoft Azure Stage File, as especificações para preparação e inserção de um arquivo CSV serão mostradas no esquema de dados para que possam ser mapeadas em uma transformação. O padrão usado é corresponder a apenas um arquivo. Se o padrão corresponder a mais de um arquivo, a atividade apresentará um erro com uma mensagem descritiva.
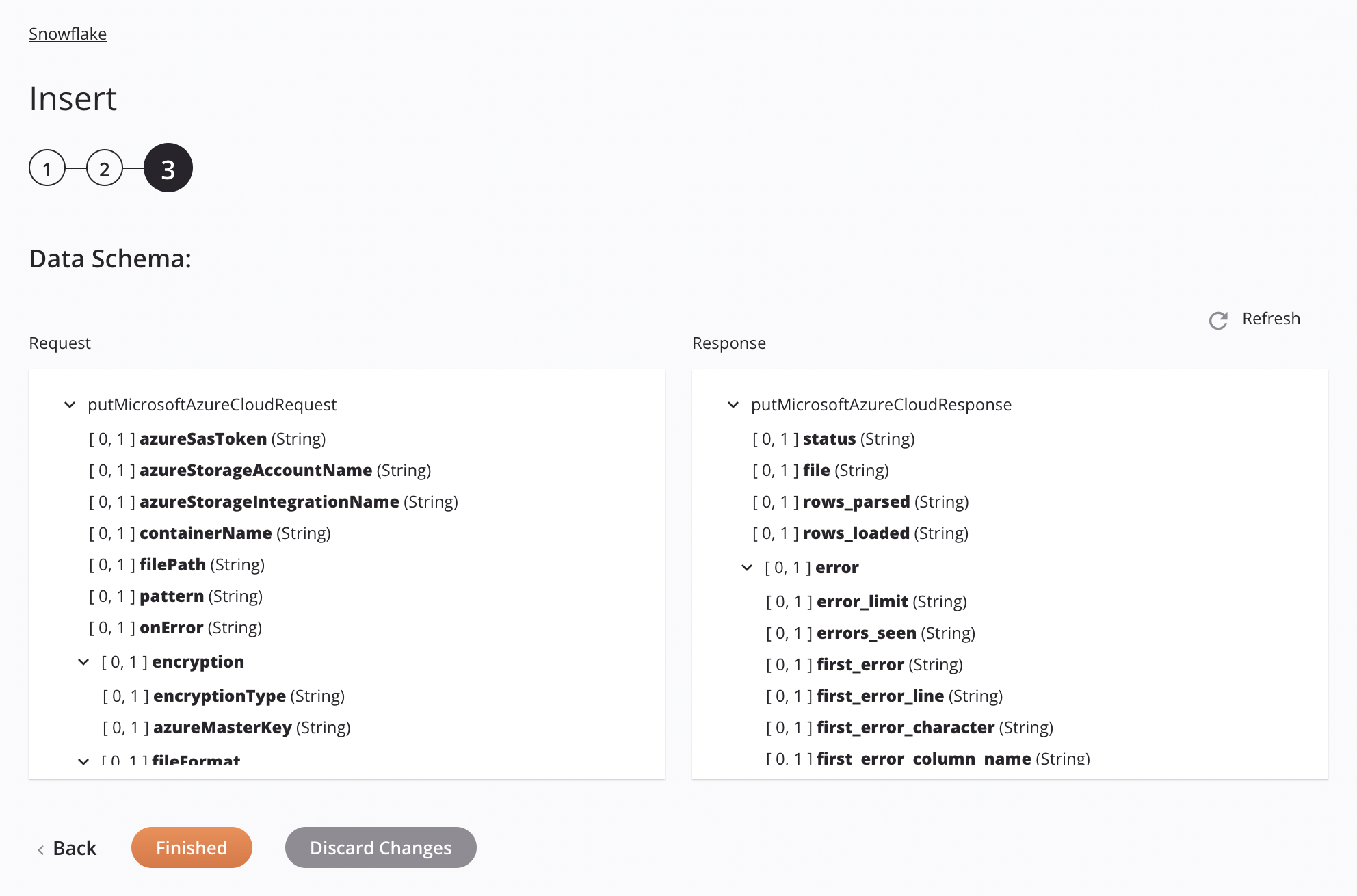
-
Solicitar
Campo/nó do esquema de solicitação Notas azureSasTokenToken de assinatura de acesso compartilhado (SAS) do Microsoft Azure. azureStorageAccountNameNome da conta de armazenamento do Microsoft Azure. azureStorageintegrationNameNome da integração de armazenamento Snowflake a ser usada para autenticação de integração de armazenamento Snowflake. containerNameNome de contêiner válido para um contêiner de armazenamento existente no Microsoft Azure. filePathLocalização do arquivo de teste no contêiner de armazenamento do Microsoft Azure. patternPadrão de expressão regular usado para localizar o arquivo no palco; se compressionéGZIP,[.]gzé anexado ao padrão.onErrorEm caso de erro opção selecionada. encryptionNó que representa a criptografia. encryptionTypeTipo de criptografia do Microsoft Azure (somente criptografia do lado do cliente). azureMasterKeyChave mestra do Microsoft Azure. fileFormatNó que representa o formato do arquivo. nullIfUma string a ser convertida em SQL NULL; por padrão, é uma string vazia. Veja oNULL_IFopção do SnowflakeCOPY INTO<location>documentação.enclosingCharCaractere usado para delimitar campos de dados; Veja o FIELD_OPTIONALLY_ENCLOSED_BYopção do SnowflakeCOPY INTO<location>documentação.Nota
O
enclosingCharpode ser um caractere de aspas simples'ou caractere de aspas duplas". Para usar o caractere de aspas simples, use o octal'ou o hexadecimal0x27representações ou use um escape de aspas simples duplas''. Quando um campo contém esse caractere, escape dele usando o mesmo caractere.compressionO algoritmo de compactação usado para os arquivos de dados. GZIPouNONEsão suportados. Veja a opção de compactação do SnowflakeCOPY INTO<location>documentação.skipHeaderNúmero de linhas no início do arquivo de origem a serem ignoradas. errorOnColumnCountMismatchSinalizador booleano para relatar um erro se as contagens de origem e destino do esquema de resposta não corresponderem. fieldDelimiterO caractere delimitador usado para separar campos de dados; Veja o FIELD_DELIMITERopção do SnowflakeCOPY INTO<table>documentação.recordDelimiterO caractere delimitador usado para separar grupos de campos; Veja o RECORD_DELIMITERopção do SnowflakeCOPY INTO<table>documentação. -
Resposta
Campo/nó do esquema de resposta Notas statusStatus retornado. fileNome do arquivo CSV preparado processado ao inserir dados na tabela Snowflake. rows_parsedNúmero de linhas analisadas do arquivo CSV. rows_loadedNúmero de linhas carregadas do arquivo CSV na tabela Snowflake sem erros. errorNó que representa as mensagens de erro. error_limitNúmero de erros que fazem com que o arquivo seja ignorado conforme definido em Skip_File_\<num>. errors_seenContagem de erros vistos. first_errorO primeiro erro no arquivo de origem. first_error_lineO número da primeira linha do primeiro erro. first_error_characterO primeiro caractere do primeiro erro. first_error_column_nameO nome da coluna do primeiro local de erro.
Próximos Passos¶
Depois de configurar uma atividade Snowflake Insert, conclua a configuração da operação adicionando e configurando outras atividades, transformações ou scripts como etapas da operação. Você também pode definir as configurações de operação, que incluem a capacidade de encadear operações que estejam no mesmo fluxo de trabalho ou em workflows diferentes.
As ações de menu de uma atividade podem ser acessadas no painel do projeto e na quadro de design. Para obter detalhes, consulte Menu Ações da atividade em Noções básicas do conector.
As atividades Snowflake Insert podem ser usadas como destino com estes padrões de operação:
- Padrão de transformação
- Padrão de duas transformações (como o primeiro ou segundo alvo)
Para usar a atividade com funções de script, grave os dados em um local temporário e use esse local temporário na função de script.
Quando estiver pronto, implantar e execute a operação e validar o comportamento verificando os logs de operação.