Opções de Operação¶
Introdução¶
Cada operação pode ser configurada com opções como quando a operação atingirá o tempo limite, o que registrar e o prazo para o log de depurar da operação. A presença de determinados componentes como etapas de operação torna visíveis opções adicionais para a execução de uma operação subsequente e para o uso de fragmentação de dados.
Acessar Opções de Operação¶
A opção Configurações para operações pode ser acessada nestes locais:
- A aba Workflows do painel do projeto (consulte Menu Ações do componente em Guia Workflows do painel do projeto).
- A aba Componentes do painel do projeto (consulte Menu Ações do componente em Guia Componentes do painel do projeto).
- A quadro de design (consulte Menu Ações do componente em Quadro de Design).
Assim que a tela de configurações de operação estiver aberta, selecione a aba Opções:

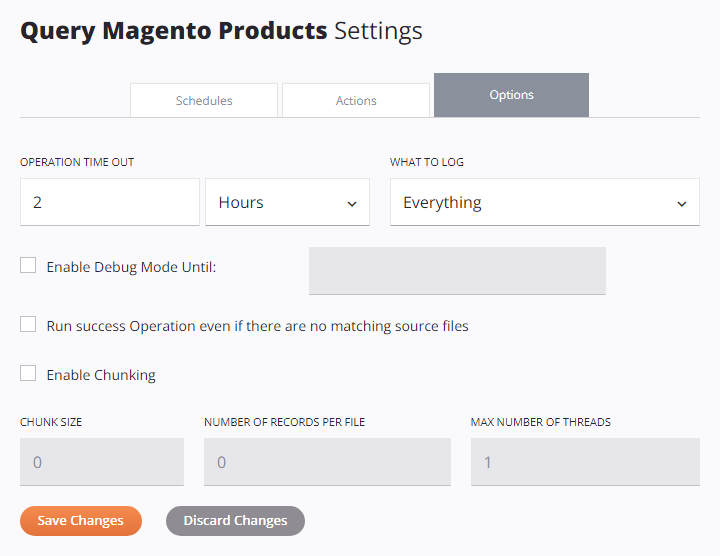
Configurar Opções de Operação¶
Cada opção disponível na aba Opções das configurações de operação é descrita abaixo.
-
Tempo limite da operação: Especifique o tempo máximo que a operação durará antes de ser cancelada. No primeiro campo, insira um número e no segundo campo use o menu suspenso para selecionar as unidades em Segundos, Minutos ou Horas. O padrão é 2 horas.
Os motivos comuns para ajustar o valor Tempo limite de operação incluem estes:
-
Aumente o valor do tempo limite se a operação tiver grandes conjuntos de dados que demoram muito para serem executados.
-
Diminuir o valor do timeout caso a operação seja sensível ao tempo; isto é, você não deseja que a operação seja bem-sucedida se ela não puder ser concluída dentro de um determinado período de tempo.
Nota
Operações que são acionadas por APIs do API Manager não estão sujeitos à configuração Tempo limite de operação ao usar Agentes em Nuvem. Em Agentes Privados, use o
EnableAPITimeoutconfiguração no arquivo de configuração do Agente Privado para que a configuração Tempo limite da operação seja aplicada às operações acionadas por APIs. -
-
O que registrar: Use o menu suspenso para selecionar o que registrar nos logs de operação, um de Tudo (padrão) ou Somente erros:
-
Tudo: Operações com qualquer status de operação são registrados.
-
Somente erros: Somente operações com status de tipo de erro (como Erro, Falha SOAP ou Sucesso com erro filho) são registradas. As operações secundárias bem-sucedidas não são registradas. As operações pai (nível raiz) são sempre registradas, pois exigem registro para funcionar corretamente.
Um motivo comum para limitar os logs a Somente erros é se você estiver tendo problemas de latência de operação. Dessa forma, se você não planejava usar as outras mensagens que não são de erro normalmente filtradas nos logs de operação, você pode evitar que elas sejam geradas em primeiro lugar.
-
-
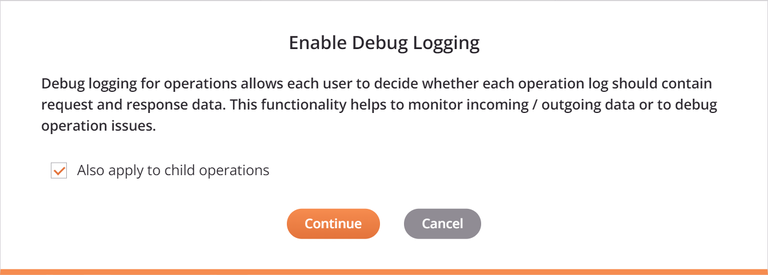
Ativar modo de depuração até: Selecione para ativar o registro de depurar da operação e especifique uma data em que o modo de depurar será desativado automaticamente, limitado a duas semanas a partir da data atual. O log de depurar da operação será desativado no início dessa data (ou seja, 12h) usando o fuso horário do agente.
Ao selecionar Ativar modo de depuração até, uma caixa de diálogo fornece uma caixa de seleção Aplicar também a operações secundárias que transmitirá as configurações para quaisquer operações secundárias. Esta opção também é fornecida ao limpar a configuração do modo de depurar da operação.
Quando o log de depurar de operação está habilitado, estes tipos de logs são gerados, dependendo do tipo de agente:
-
Agente Privado: Arquivos de log de depuração para uma operação. Esta opção é usada principalmente para depuração de problemas durante testes e não deve ser ativada em produção, pois pode criar arquivos muito grandes. O registro de depuração também pode ser habilitado para todo o projeto a partir do próprio Agente Privado (consulte Registro de depuração de operação). Os arquivos de log de depurar podem ser acessados diretamente nos Agentes Privados e podem ser baixados através do Management Console Agentes > Agentes e Operações em tempo de execução Páginas.
-
Agente Privado ou Agente em Nuvem: Dois tipos de logs podem ser gerados:
-
Dados de entrada e saída do componente: Dados gravados em um Cloud Studio log de operação para uma operação em execução no agente versão 10.48 ou posterior. Os dados são retidos por 30 dias pelo Harmony.
-
Logs de operações de API: Logs de operações para operações de API bem-sucedidas (configuradas para APIs personalizadas ou Serviços OData). Por padrão, apenas operações de API com erros são registradas nos logs de operação.
-
Para obter detalhes adicionais, consulte Registro de depuração de operação para Agentes em Nuvem ou Registro de depuração de operação para Agentes Privados.
Cuidado
A geração de dados de entrada e saída do componente não é afetada pela configuração do Grupo de Agentes Ativar Cloud Logging (consulte Agentes > Grupos de Agente). Os dados de entrada e saída do componente serão registrados na nuvem Harmony mesmo se o registro na nuvem estiver desativado.
Para desabilitar a geração de dados de entrada e saída de componentes em um Grupo de Agentes Privados, no arquivo de configuração do Agente Privado debaixo de
[VerboseLogging]seção, conjuntoverbose.logging.enable=false.Aviso
Quando os dados de entrada e saída do componente são gerados, todos os dados de solicitação e resposta para essa operação são registrados na nuvem Harmony e permanecem lá por 30 dias. Esteja ciente de que informações de identificação pessoal (PII) e dados confidenciais, como credenciais fornecidas em uma payload de solicitação, estarão visíveis em texto não criptografado nos dados de entrada e saída nos logs da nuvem Harmony.
-
-
Executar operação bem-sucedida mesmo se não houver arquivos de origem correspondentes: Selecione para forçar o sucesso de uma operação acima na cadeia. Isso efetivamente permite iniciar uma operação com uma condição On Success (configurada com uma ação de operação) mesmo se o gatilho falhar.
Esta opção é aplicável somente se a operação contiver uma API, Compartilhamento de arquivo, FTP, HTTP, Armazenamento local, SOAP, Armazenamento temporário ou Atividade variável que é usado como origem na operação e se aplica somente quando a operação tem uma condição On Success configurada. Por padrão, qualquer operação On Success será executada somente se tiver um arquivo de origem correspondente para processar. Esta opção pode ser útil para configurar partes posteriores de um projeto sem exigir o sucesso de uma operação dependente.
Nota
A configuração
AlwaysRunSuccessOperationno[OperationEngine]seção do arquivo de configuração do Agente Privado substitui a configuração Executar operação com sucesso mesmo se não houver arquivos de origem correspondentes. -
Ativar fragmentação: Selecione para ativar a fragmentação de dados usando os parâmetros especificados:
-
Tamanho do bloco: Insira um número de registros de origem (nós) para processar para cada thread. Quando a fragmentação de dados está habilitada para operações que não contêm nenhuma atividade baseada no Salesforce, o tamanho padrão da fragmentação é
1. Quando uma atividade baseada no Salesforce é adicionada a uma operação que não tem a fragmentação de dados habilitada, a fragmentação de dados é automaticamente habilitada com um tamanho de fragmento padrão de200. Se estiver usando uma atividade em massa baseada no Salesforce, você deverá alterar esse padrão para um número muito maior, como 10.000. -
Número de registros por arquivo: Insira um número solicitado de registros a serem colocados no arquivo de destino. O padrão é
0, o que significa que não há limite para o número de registros por arquivo. -
Número máximo de threads: Insira o número de threads simultâneos a serem processados. Quando a fragmentação de dados está habilitada para operações que não contêm nenhuma atividade baseada no Salesforce, o número padrão de threads é
1. Quando uma atividade baseada no Salesforce é adicionada a uma operação que não tem a fragmentação de dados habilitada, a fragmentação de dados é automaticamente habilitada com um número padrão de threads de2.
Esta opção estará presente somente se a operação contiver uma transformação ou um banco de dados, NetSuite, Salesforce, Salesforce Service Cloud, ServiceMax ou atividade SOAP e é usado para processar dados para o sistema de destino em partes. Isto permite um processamento mais rápido de grandes conjuntos de dados e também é usado para resolver limites de registro impostos por vários sistemas baseados em serviços da Web ao fazer uma solicitação.
Observe se você estiver usando um endpoint baseado em Salesforce ( Salesforce, Salesforce Service Cloud ou ServiceMax ):
-
Se uma atividade baseada no Salesforce for adicionada a uma operação que não tenha a fragmentação de dados habilitada, a fragmentação de dados será habilitada com configurações padrão especificamente para atividades baseadas no Salesforce, conforme descrito acima.
-
Se uma atividade baseada no Salesforce for adicionada a uma operação que já tenha a fragmentação de dados habilitada, as configurações da fragmentação de dados não serão alteradas. Da mesma forma, se uma atividade baseada no Salesforce for removida de uma operação, as configurações de fragmentação de dados não serão alteradas.
Informações adicionais e práticas recomendadas para fragmentação de dados são fornecidas na próxima seção, Chunking.
-
-
Salvar alterações: Clique para salvar e fechar as configurações de operação.
-
Descartar alterações: Após fazer alterações nas configurações de operação, clique para fechar as configurações sem salvar.
Pedaço¶
Chunking é usado para dividir os dados de origem em vários pedaços com base no tamanho do pedaço configurado. O tamanho do bloco é o número de registros de origem (nós) para cada bloco. A transformação é então executada em cada pedaço separadamente, com cada pedaço de origem produzindo um pedaço de destino. Os pedaços de destino resultantes se combinam para produzir o destino final.
O chunking poderá ser usado somente se os registros forem independentes e provenientes de uma origem não LDAP. Recomendamos usar o maior tamanho possível de bloco, certificando-se de que os dados de um bloco caibam na memória disponível. Para métodos adicionais para limitar a quantidade de memória que uma transformação usa, consulte Processamento de Transformação.
Aviso
O uso de fragmentação de dados afeta o comportamento das variáveis globais e do projeto. Consulte Usar variáveis com fragmentação abaixo.
Limitações da API¶
Muitas APIs de serviços da Web (SOAP/REST) têm limitações de tamanho. Por exemplo, um upsert baseado no Salesforce aceita apenas 200 registros para cada chamada. Com memória suficiente, você poderia configurar uma operação para usar um tamanho de bloco de 200. A origem seria dividida em blocos de 200 registros cada, e cada transformação chamaria o serviço Web uma vez com um bloco de 200 registros. Isso seria repetido até que todos os registros fossem processados. Os arquivos de destino resultantes seriam então combinados. (Observe que você também pode usar atividades em massa baseadas no Salesforce para evitar o uso de fragmentação de dados.)
Processamento Paralelo¶
Se você tiver uma fonte grande e um computador com várias CPUs, o fragmentação de dados poderá ser usado para dividir a fonte para processamento paralelo. Como cada pedaço é processado isoladamente, vários pedaços podem ser processados em paralelo. Isso se aplica somente se os registros de origem forem independentes uns dos outros no nível do nó do bloco. Os serviços da Web podem ser chamados em paralelo usando fragmentação de dados, melhorando o desempenho.
Ao usar o fragmentação de dados em uma operação onde o destino é um banco de dados, observe que os dados do destino são primeiro gravados em vários arquivos temporários (um para cada chunk). Esses arquivos são então combinados em um arquivo de destino, que é enviado ao banco de dados para inserção/atualização. Se você definir a variável Jitterbit jitterbit.target.db.commit_chunks para 1 ou true quando o fragmentação de dados está habilitado, cada pedaço é confirmado no banco de dados assim que fica disponível. Isso pode melhorar significativamente o desempenho, pois as inserções/atualizações do banco de dados são executadas em paralelo.
Use Variáveis com Chunking¶
Como o fragmentação de dados pode invocar multithreading, seu uso pode afetar o comportamento de variáveis que não são compartilhadas entre os threads.
Global e variáveis do projeto são segregados entre as instâncias de fragmentação de dados e, embora os dados sejam combinados, as alterações nessas variáveis não o são. Somente as alterações feitas no thread inicial são preservadas no final da transformação.
Por exemplo, se uma operação — com fragmentação de dados e vários threads — tiver uma transformação que altera uma variável global, o valor da variável global após o término da operação será aquele do primeiro thread. Quaisquer alterações na variável em outros threads são independentes e são descartadas quando a operação é concluída.
Essas variáveis globais são passadas para os outros threads por valor e não por referência, garantindo que quaisquer alterações nas variáveis não sejam refletidas em outros threads ou operações. Isto é semelhante ao RunOperation funcionar quando estiver no modo assíncrono.