Criar Saída de Registro Único Ou Múltiplo¶
Caso de Uso¶
Um cenário frequente é quando a origem contém vários registros e a orquestração eficiente é habilitada se os arquivos de destino forem gravados individualmente, de modo que o nome do arquivo contenha um valor-chave derivado de um valor de campo no registro.
O comportamento padrão do Jitterbit é criar um único arquivo contendo vários registros quando a origem contém vários registros. Esta página também demonstra (no Exemplo 2) como realizar a saída de vários registros usando o prefixo de variável global reservado SOURCE_CHUNK.
Nota
Este padrão de design usa Design Studio como um exemplo; você pode aplicar os mesmos conceitos em Cloud Studio usando etapas semelhantes.
Exemplo 1: Vários Registros em um Único Arquivo de Saída¶
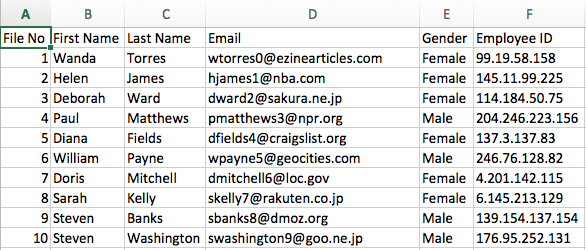
Para estes exemplos, suponha que o arquivo de origem contenha uma lista de funcionários em que um campo contenha um ID de funcionário.
Exemplo de dados de origem:
Crie uma Operação básica onde aceitamos todos os padrões:
Defina a Fonte:
Mapeamento simples onde a transformação mostra os registros de origem e destino:
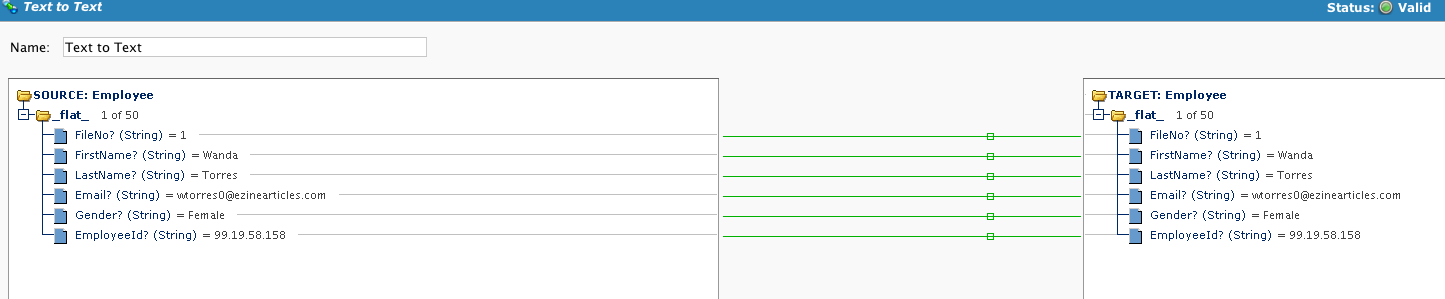
Defina o Alvo:
O arquivo de destino (Multiple records.txt) será um único arquivo que contém vários registros:

Exemplo 2: Vários Arquivos de Saída Contendo um Único Registro¶
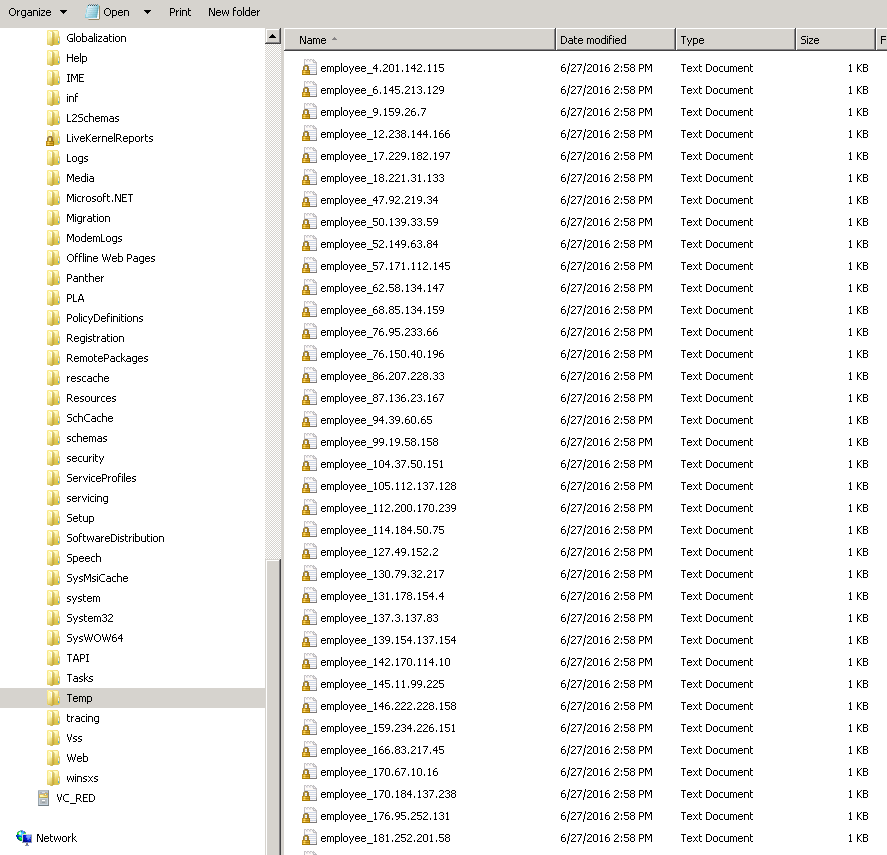
O endpoint de destino requer um formato de arquivo em que o ID do funcionário é obrigatório no nome do arquivo. Isso significa criar 50 registros com cada registro em um nome de arquivo padronizado após employee_\<employee id>.txt.
Antes da introdução do SCOPE_CHUNK, a geração de vários arquivos contendo um único registro exigiria um conjunto adicional de operações para ler os registros e escrevê-los individualmente.
Usando SCOPE_CHUNK, uma única operação pode gerar vários registros e fornecer controle sobre o nome do arquivo orientado por dados. Este exemplo processará um arquivo para um conjunto diferente de 50 funcionários que contém os mesmos campos de dados que o arquivo de dados de origem usado no Exemplo 1. A operação neste exemplo cria 50 registros, cada um terminando com o nome de arquivo employee_ \<id do funcionário>.txt.
Cuidado
O SCOPE_CHUNK a sintaxe de prefixo não é suportada em operações com uma transformação que usa mapeamento condicional.
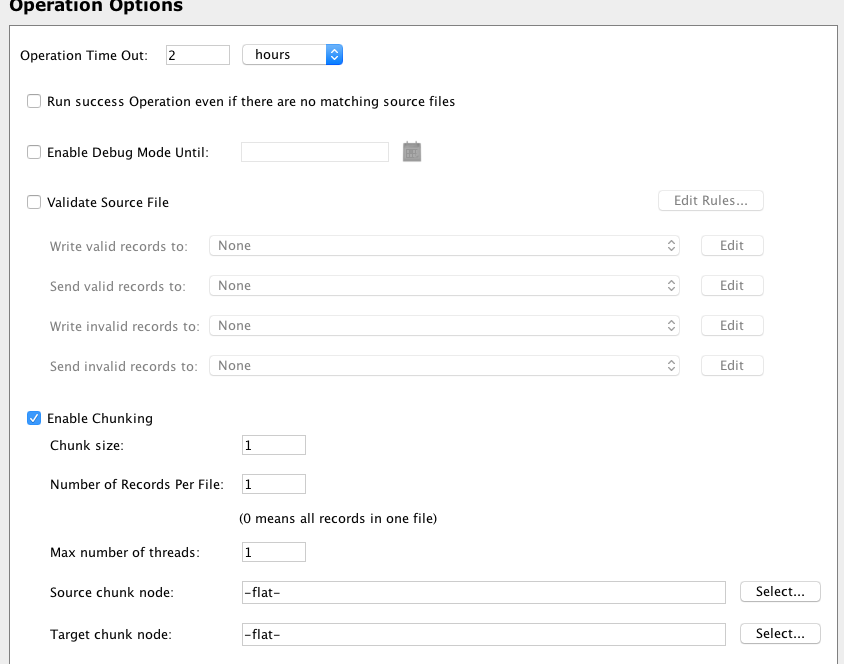
Defina Ativar Chunking em Opções de operação. Defina Tamanho do bloco, Número de registros por arquivo e Número máximo de threads como 1. Isso forçará a transformação a processar um registro por vez:
O mapeamento é semelhante, com adição de aplicação de script no último campo. Observe que quando a operação é testada, apenas 1 registro é processado.
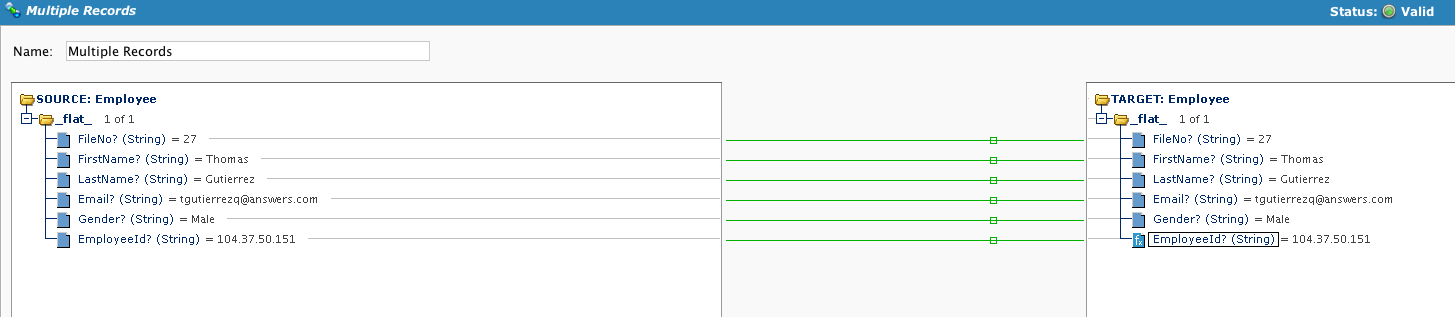
Crie um Script no último campo. Ao construir uma variável global precedida por SCOPE_CHUNK e preencher o nome do arquivo desejado para incluir um valor de registro, podemos passar a variável global para o destino.

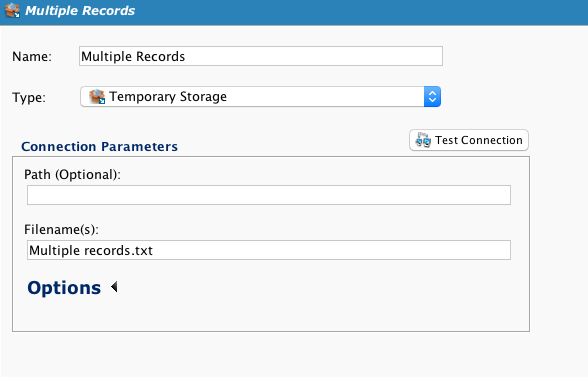
Insira a variável global no campo Nome(s) de arquivo do destino:
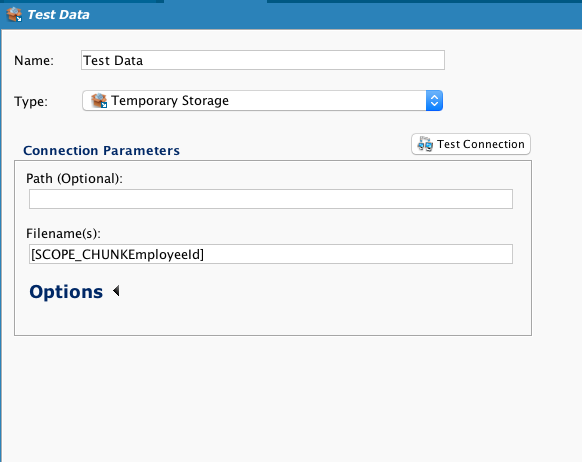
Quando executada, a operação agora cria um arquivo individual para cada funcionário, contendo apenas aquele registro de funcionário e nomeado individualmente para incluir o ID do funcionário. Na captura de tela mostrada, os sufixos de nome de arquivo (.txt) estão ocultos: