Pesquisar Dados Usando um Dicionário¶
Caso de Uso¶
Nota
Este padrão de design usa Design Studio como um exemplo; você pode aplicar os mesmos conceitos em Cloud Studio usando etapas semelhantes.
Nesse padrão, um registro de origem não contém todos os dados exigidos pelo destino. Por exemplo, no caso de um relacionamento pai-filho, se um registro filho for atualizado em um destino, geralmente uma referência de registro pai é exigida pelo destino. Ou, se estiver trabalhando com um registro de produto, o registro de origem pode ter apenas um número SKU, mas o destino também deseja uma referência de grupo ou classe.
Uma maneira de lidar com isso é fazer uma pesquisa em linha ou dinâmica, inserindo uma chamada de função na transformação, de forma que, à medida que cada registro é lido, uma pesquisa seja feita para um objeto diferente e esse valor seja preenchido no campo. As funções que podem realizar isso são:
- DBLookup é útil para obter um único campo em uma fonte de banco de dados.
- DBLookupAll e DBExecute, são úteis se mais de um campo precisar ser buscado.
- Se SFDC contém os dados necessários, então SFLookup, SFLookupAll e SFCacheLookup poderia ser usado. O SFCacheLookup tem a eficiência adicional de armazenamento em cache, de modo que o processo de login pode ser ignorado se a sessão SFDC ainda estiver ativa.
No entanto, há um custo para usar essas funções. Tome como exemplo o uso de SFLookup em uma transformação, onde ele está sendo usado para obter um ID de um objeto. Quando um conjunto de dados de origem passa por uma transformação, cada registro é avaliado e todas as funções de script são executadas individualmente. Se houver 10 registros a serem processados, haverá 10 chamadas para SFDC. Se a integração processar um pequeno número de registros, usar pesquisas em linha é uma ótima solução. Mas e se o universo de valores de pesquisa válidos não for 1.000, mas 10.000 registros devem ser processados? Realizar 10.000 chamadas adicionais em uma transformação, onde cada chamada leva pelo menos um segundo, é muito ineficiente e lento. A maneira muito melhor é pagar a pequena penalidade de tempo para pesquisar os 1.000 registros em um dicionário e usá-lo para pesquisas.
O Que é um Dicionário no Jitterbit?¶
No Jitterbit, um dicionário é um tipo especial de matriz de variável global que contém um par chave-valor. As etapas e funções são:
- Inicialize o dicionário usando o Dict função.
- Carregue dados com pares chave-valor, como '4011' e 'Banana', '4061' e 'Alface', '4063' e 'Tomate', etc. Use o AddtoDict função.
- Pesquise uma chave depois de verificar primeiro se a chave já existe usando HasKey função.
- Consulta de dados passando a chave (4011) e retornando o valor (Banana). O script usa um '
[ ]' após o nome do dicionário, como:$value=$d["4011"]
Um dicionário habilita nosso cenário de forma que uma operação possa obter dados da fonte e carregar o dicionário, tornando-o disponível para outras operações para pesquisas. Uma operação inicial pode carregar o dicionário com 10.000 registros e uma operação posterior pode passar rapidamente uma chave para o dicionário e obter um valor.
Uma série de coisas para manter em mente com dicionários:
- O escopo dos dicionários é limitado à instância da cadeia de operações. Por exemplo, se a operação A carregar
$MyDictcom 10.000 registros, somente as operações vinculadas por caminhos de Sucesso ou Falha, ou com RunOperation() terão acesso a esse dicionário. Mas, se uma operação usar fragmentação de dados e encadeamento e tiver uma transformação que preencha um dicionário, o dicionário será inconsistente. Isso ocorre porque o Jitterbit não pega os valores atribuídos às variáveis por vários segmentos de operação e os concatena em um único conjunto de valores. Isso é verdade para todas as variáveis globais ou arrays. Use os valores padrão de fragmentação de dados/threading ao criar uma operação que preencha dicionários. - Os dicionários, por usarem uma pesquisa binária, são muito rápidos em encontrar chaves e retornar valores. Uma chave geralmente pode ser encontrada em cinco a seis tentativas. Por outro lado, compare esse tipo de pesquisa com um loop em uma matriz de 10.000 registros para localizar uma chave.
- Os dicionários não são gravados na memória, portanto, não afetarão materialmente a memória disponível do servidor para processamento.
Exemplo 1¶
O cliente tem duas tabelas, uma com informações de produtos e outra com categorias de produtos, sendo que ambas são necessárias para atualizar uma 3ª tabela. A fonte é uma exibição em um data warehouse, que é otimizado para fornecer dados em massa, mas não para pesquisas rápidas. Usar a função DBLookup para milhares de registros seria bastante lento. Além disso, o cliente tem um arquivo CSV que contém informações usadas para filtrar dados da origem

PWE.01 Obter Lista LR¶
- Isso lê um arquivo externo em armazenamento temporário
PWE.02 Definir Dict do Produto¶
- Um script inicializa o Dicionário:
$Product.Dict.LR_List=Dict(); - Lê de um arquivo temporário de origem
- A Transformação carrega os valores em um dicionário:

-
Script:
AddtoDict($Product.Dict.LR_List,Style_Color,Flag+"|"+Launch_Release_Date); -
Observe aqui que o valor é na verdade 2 valores, separados por um '|'. A alternativa seria criar 2 dicionários, um para Flag e outro para Launch_Release_Date, o que seria uma complexidade desnecessária.
Produto de Consulta PWE.03 da Teradata¶
- A transformação possui uma condição para filtrar os produtos que não estão no arquivo CSV, e que também atribui valores às variáveis que são utilizadas na transformação.
- Observe que estamos dividindo (com um '|') o que foi carregado na operação anterior e carregando em $Product.Flag e $Product.ReleaseDate.
result=false;
$Product.Dict.Key=PROD_CD;
If(HasKey($Product.Dict.LR_List,$Product.Dict.Key),
result=true;
value=$Product.Dict.LR_List[$Product.Dict.Key];
arr=Split(value,"|");
$Product.Flag=arr[0];
$Product.ReleaseDate=arr[1];
);
result
PWE.04 Consulta de Categorias de Produtos¶
Esta é uma consultar SFDC em massa (não SOAP), que não afeta os limites da API do cliente. Ele carrega dados em um arquivo temporário local.
PWE.05 Ditado de Categoria de Produto¶
- Isso carrega um dicionário com o código como chave e os dados SFDC como valor

$Code__c=Code__c;
AddToDict($Dict.Product.Category.Line, $Code__c, Id)
PWE.06 Estilo de Processo¶
- O dicionário é inicializado:
$Style.Dict.Unique=Dict(); - A Transformação procura o ID no campo Product_Category

$GBL_CAT_CORE_FOCS_CD=GBL_CAT_CORE_FOCS_CD;
If(HasKey($Dict.Product.Category.Line,$GBL_CAT_CORE_FOCS_CD),result=$Dict.Product.Category.Line[$GBL_CAT_CORE_FOCS_CD],result="");
result
- Observe o uso de HasKey para verificar se a chave existe, em vez de apenas ...
$Dict.Product.Category.Line[$GBL_CAT_CORE_FOCS_CD]. - Se for passada uma chave que não existe no dicionário, será gerado um erro, pois estamos tentando consultar um valor inexistente.
PWE.07 Estilos de Inserção em Massa¶
- Por fim, o arquivo é carregado em massa no SFDC.
Exemplo 2¶
Neste exemplo, estamos processando uma resposta XML, extraindo os SKUs e os valores em um dicionário para uso em uma operação posterior.

- Este script está no penúltimo script pós-operatório:
arr=Array();
$jitterbit.scripting.while.max_iterations=10000;
arr=Split($IFMS.Response,'<');
cnt=Length(arr);i=0;j=0;
$DCL.LineItem=Dict();
While(i<cnt,
If(CountSubString(arr[i],'RemoteOrderNumber xmlns=""')==1,
order=arr[i];
start=Index(order,'>');
end=Length(order);
myorder=Mid(order,start+1,(end-1)-start);
$ACM.Shipment.Number=myorder;
);
If(CountSubString(arr[i],'ShipDate xmlns=""')==1,
shipdate=arr[i];
start=Index(shipdate,'>');
end=Length(shipdate);
shipdate=Mid(shipdate,start+1,(end-1)-start);
if(Length(shipdate)>7,
shipdate=Left(shipdate, Index(shipdate, ' '));
shipdate=CVTDate(shipdate,'?m/?d/yyyy','yyyy-mm-dd');
);
$ACM.ShipDate=shipdate;
WriteToOperationLog("Shipment: "+myorder+" ShipDate: "+shipdate);
);
If(CountSubString(arr[i],'ShippingTrackingNumber xmlns=""')==1,
tracking=arr[i];
start=Index(tracking,'>');
end=Length(tracking);
tracking=Mid(tracking,start+1,(end-1)-start);
$ACM.Tracking.Number=tracking;
WriteToOperationLog("Shipment: "+myorder+" Tracking: "+tracking);
);
If(CountSubString(arr[i],'SKU xmlns=""')==1,
sku=arr[i];
start=Index(sku,'>');
end=Length(sku);
mysku=Mid(sku,start+1, (end-1)-start);
WriteToOperationLog("SKU: "+mysku);
j++;
);
If(CountSubString(arr[i],'QuantityShipped xmlns=""')==1,
qty=arr[i];
start=Index(qty,'>');
end=Length(qty);
myqty=Mid(qty,start+1, (end-1)-start);
WriteToOperationLog("QuantityShipped: "+myqty);
$DCL.LineItem[mysku]=myqty
);
If(CountSubString(arr[i],'/OrderList')==1,
WriteToOperationLog("End of OrderList. " + String(j) + " items found.");
$ACM.Login.Counter=1;
RunOperation("<TAG>Operations/2. Fulfillment/F.5.0.D Get Shipments</TAG>");
$DCL.LineItem=Dict();
);
++i);
- Este script faz uma série de coisas, então esses comentários se referem às ações realizadas em relação aos dicionários.
- O dicionário DCL.LineItem é inicializado.
- As variáveis locais 'mysku' e 'myquantity' são preenchidas a partir da fonte XML.
- DCL.LineItem é preenchido usando 'mysku' como chave e 'myquantity' como valor.
- O dicionário é usado em uma operação posterior, F.5.2.4

- A transformação exibe o mapeamento para Quantidade Enviada.
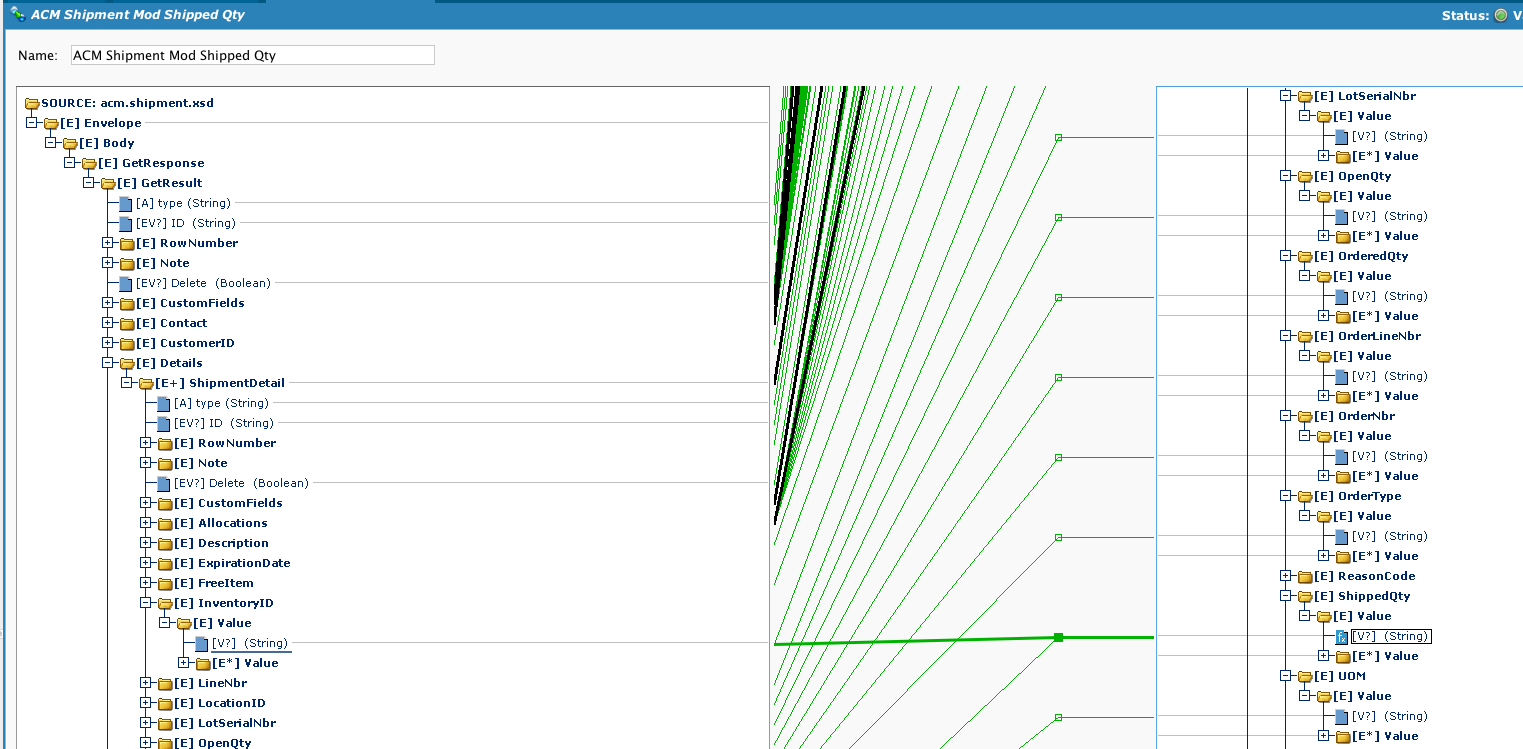
- O script ShippedQty usa o campo de origem como uma chave para recuperar a quantidade enviada e preencher o valor.
- Observe que verificamos (usando HasKey) se a chave existe ou não.
$myVal=Envelope$Body$GetResponse$GetResult$Details$ShipmentDetail.InventoryID$Value$;
WriteToOperationLog("Shipped Qty: "+Envelope$Body$GetResponse$GetResult$Details$ShipmentDetail.ShippedQty$Value$+" ------- "+
"InventoryID: "+Envelope$Body$GetResponse$GetResult$Details$ShipmentDetail.InventoryID$Value$);
If(HasKey($DCL.LineItem, $myVal),
output=$DCL.LineItem[$myVal],
WriteToOperationLog("Could not find: "+$myVal+" in Dict");
output=0
);
output